 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVS^2: Deep Unsupervised Multi-view Stereo with Multi-View Symmetry
Paper and Code
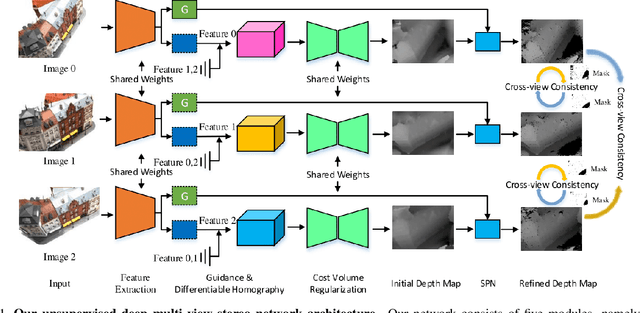
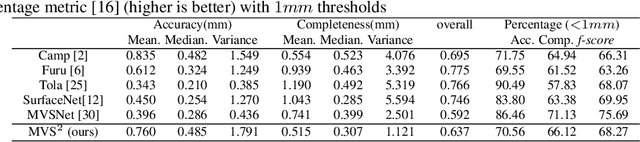


The success of existing deep-learning based multi-view stereo (MVS) approaches greatly depends on the availability of large-scale supervision in the form of dense depth maps. Such supervision, while not always possible, tends to hinder the generalization ability of the learned models in never-seen-before scenarios. In this paper, we propose the first unsupervised learning based MVS network, which learns the multi-view depth maps from the input multi-view images and does not need ground-truth 3D training data. Our network is symmetric in predicting depth maps for all views simultaneously, where we enforce cross-view consistency of multi-view depth maps during both training and testing stages. Thus, the learned multi-view depth maps naturally comply with the underlying 3D scene geometry. Besides, our network also learns the multi-view occlusion maps, which further improves the robustness of our network in handling real-world occlusions. Experimental results on multiple benchmarking datasets demonstrate the effectiveness of our network and the excellent generalization ability.