 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSELD-Mamba: Selective State-Space Model for Sound Event Localization and Detection with Source Distance Estimation
Paper and Code
Aug 09, 2024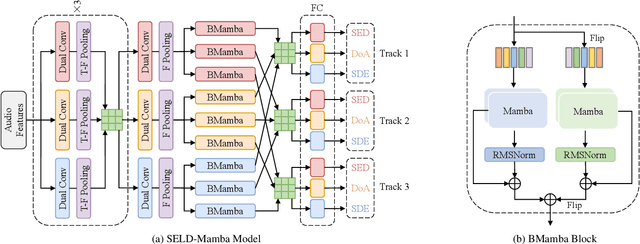

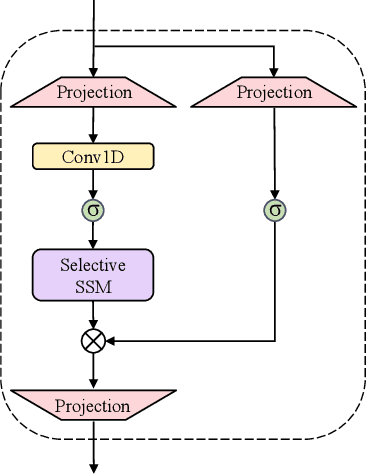

In the Sound Event Localization and Detection (SELD) task, Transformer-based models have demonstrated impressive capabilities. However, the quadratic complexity of the Transformer's self-attention mechanism results in computational inefficiencies. In this paper, we propose a network architecture for SELD called SELD-Mamba, which utilizes Mamba, a selective state-space model. We adopt the Event-Independent Network V2 (EINV2) as the foundational framework and replace its Conformer blocks with bidirectional Mamba blocks to capture a broader range of contextual information while maintaining computational efficiency. Additionally, we implement a two-stage training method, with the first stage focusing on Sound Event Detection (SED) and Direction of Arrival (DoA) estimation losses, and the second stage reintroducing the Source Distance Estimation (SDE) loss. Our experimental results on the 2024 DCASE Challenge Task3 dataset demonstrate the effectiveness of the selective state-space model in SELD and highlight the benefits of the two-stage training approach in enhancing SELD performance.