 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Instance-incremental Scene Graph Generation from Real-world Point Clouds via Normalizing Flows
Feb 21, 2023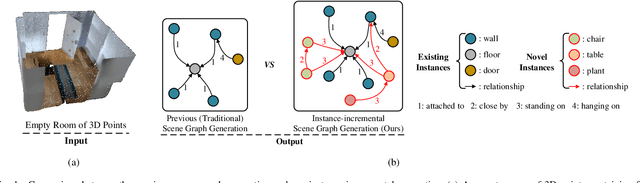
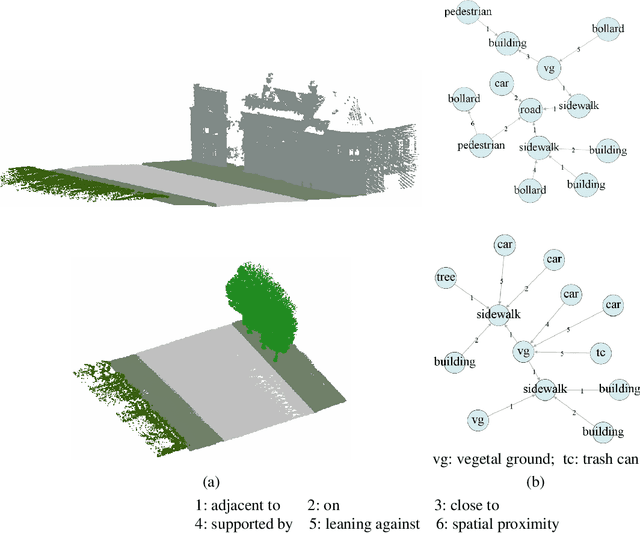
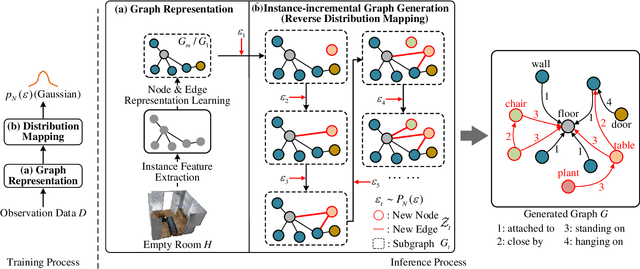
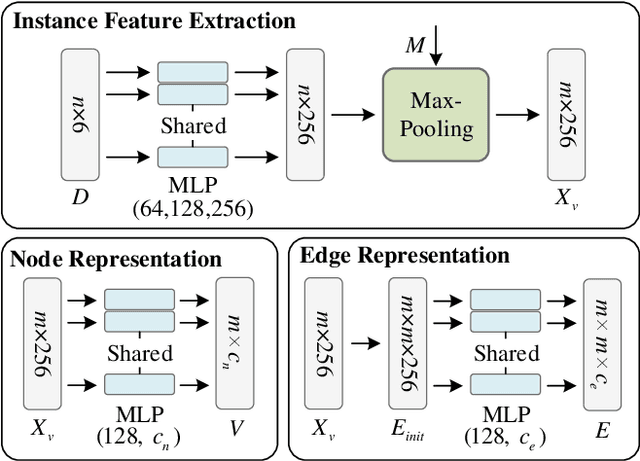
This work introduces a new task of instance-incremental scene graph generation: Given an empty room of the point cloud, representing it as a graph and automatically increasing novel instances. A graph denoting the object layout of the scene is finally generated. It is an important task since it helps to guide the insertion of novel 3D objects into a real-world scene in vision-based applications like augmented reality. It is also challenging because the complexity of the real-world point cloud brings difficulties in learning object layout experiences from the observation data (non-empty rooms with labeled semantics). We model this task as a conditional generation problem and propose a 3D autoregressive framework based on normalizing flows (3D-ANF) to address it. We first represent the point cloud as a graph by extracting the containing label semantics and contextual relationships. Next, a model based on normalizing flows is introduced to map the conditional generation of graphic elements into the Gaussian process. The mapping is invertible. Thus, the real-world experiences represented in the observation data can be modeled in the training phase, and novel instances can be sequentially generated based on the Gaussian process in the testing phase. We implement this new task on the dataset of 3D point-based scenes (3DSSG and 3RScan) and evaluate the performance of our method. Experiments show that our method generates reliable novel graphs from the real-world point cloud and achieves state-of-the-art performance on the benchmark dataset.