 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedOpenClaw: Auditable Medical Imaging Agents Reasoning over Uncurated Full Studies
Mar 25, 2026Currently, evaluating vision-language models (VLMs) in medical imaging tasks oversimplifies clinical reality by relying on pre-selected 2D images that demand significant manual labor to curate. This setup misses the core challenge of realworld diagnostics: a true clinical agent must actively navigate full 3D volumes across multiple sequences or modalities to gather evidence and ultimately support a final decision. To address this, we propose MEDOPENCLAW, an auditable runtime designed to let VLMs operate dynamically within standard medical tools or viewers (e.g., 3D Slicer). On top of this runtime, we introduce MEDFLOWBENCH, a full-study medical imaging benchmark covering multi-sequence brain MRI and lung CT/PET. It systematically evaluates medical agentic capabilities across viewer-only, tool-use, and open-method tracks. Initial results reveal a critical insight: while state-of-the-art LLMs/VLMs (e.g., Gemini 3.1 Pro and GPT-5.4) can successfully navigate the viewer to solve basic study-level tasks, their performance paradoxically degrades when given access to professional support tools due to a lack of precise spatial grounding. By bridging the gap between static-image perception and interactive clinical workflows, MEDOPENCLAW and MEDFLOWBENCH establish a reproducible foundation for developing auditable, full-study medical imaging agents.
DHRNet: A Dual-Path Hierarchical Relation Network for Multi-Person Pose Estimation
Apr 27, 2024


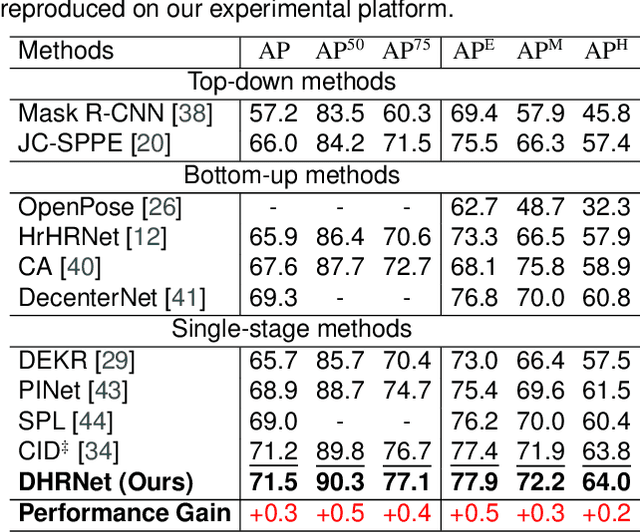
Multi-person pose estimation (MPPE) presents a formidable yet crucial challenge in computer vision. Most existing methods predominantly concentrate on isolated interaction either between instances or joints, which is inadequate for scenarios demanding concurrent localization of both instances and joints. This paper introduces a novel CNN-based single-stage method, named Dual-path Hierarchical Relation Network (DHRNet), to extract instance-to-joint and joint-to-instance interactions concurrently. Specifically, we design a dual-path interaction modeling module (DIM) that strategically organizes cross-instance and cross-joint interaction modeling modules in two complementary orders, enriching interaction information by integrating merits from different correlation modeling branches. Notably, DHRNet excels in joint localization by leveraging information from other instances and joints. Extensive evaluations on challenging datasets, including COCO, CrowdPose, and OCHuman datasets, showcase DHRNet's state-of-the-art performance. The code will be released at https://github.com/YHDang/dhrnet-multi-pose-estimation.
Learning Human Kinematics by Modeling Temporal Correlations between Joints for Video-based Human Pose Estimation
Jul 22, 2022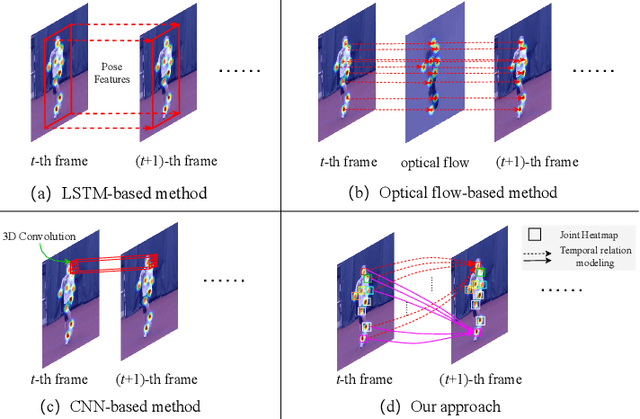

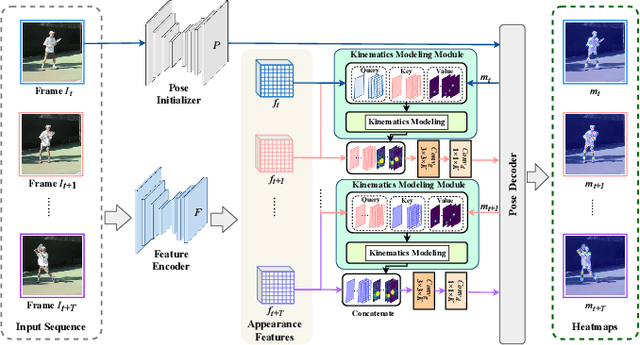

Estimating human poses from videos is critical in human-computer interaction. By precisely estimating human poses, the robot can provide an appropriate response to the human. Most existing approaches use the optical flow, RNNs, or CNNs to extract temporal features from videos. Despite the positive results of these attempts, most of them only straightforwardly integrate features along the temporal dimension, ignoring temporal correlations between joints. In contrast to previous methods, we propose a plug-and-play kinematics modeling module (KMM) based on the domain-cross attention mechanism to model the temporal correlation between joints across different frames explicitly. Specifically, the proposed KMM models the temporal correlation between any two joints by calculating their temporal similarity. In this way, KMM can learn the motion cues of each joint. Using the motion cues (temporal domain) and historical positions of joints (spatial domain), KMM can infer the initial positions of joints in the current frame in advance. In addition, we present a kinematics modeling network (KIMNet) based on the KMM for obtaining the final positions of joints by combining pose features and initial positions of joints. By explicitly modeling temporal correlations between joints, KIMNet can infer the occluded joints at present according to all joints at the previous moment. Furthermore, the KMM is achieved through an attention mechanism, which allows it to maintain the high resolution of features. Therefore, it can transfer rich historical pose information to the current frame, which provides effective pose information for locating occluded joints. Our approach achieves state-of-the-art results on two standard video-based pose estimation benchmarks. Moreover, the proposed KIMNet shows some robustness to the occlusion, demonstrating the effectiveness of the proposed method.