 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching in adverse scenes: a statistically feedback-driven threshold and mask adjustment teacher-student framework for object detection in UAV images under adverse scenes
Jun 12, 2025



Unsupervised Domain Adaptation (UDA) has shown promise in effectively alleviating the performance degradation caused by domain gaps between source and target domains, and it can potentially be generalized to UAV object detection in adverse scenes. However, existing UDA studies are based on natural images or clear UAV imagery, and research focused on UAV imagery in adverse conditions is still in its infancy. Moreover, due to the unique perspective of UAVs and the interference from adverse conditions, these methods often fail to accurately align features and are influenced by limited or noisy pseudo-labels. To address this, we propose the first benchmark for UAV object detection in adverse scenes, the Statistical Feedback-Driven Threshold and Mask Adjustment Teacher-Student Framework (SF-TMAT). Specifically, SF-TMAT introduces a design called Dynamic Step Feedback Mask Adjustment Autoencoder (DSFMA), which dynamically adjusts the mask ratio and reconstructs feature maps by integrating training progress and loss feedback. This approach dynamically adjusts the learning focus at different training stages to meet the model's needs for learning features at varying levels of granularity. Additionally, we propose a unique Variance Feedback Smoothing Threshold (VFST) strategy, which statistically computes the mean confidence of each class and dynamically adjusts the selection threshold by incorporating a variance penalty term. This strategy improves the quality of pseudo-labels and uncovers potentially valid labels, thus mitigating domain bias. Extensive experiments demonstrate the superiority and generalization capability of the proposed SF-TMAT in UAV object detection under adverse scene conditions. The Code is released at https://github.com/ChenHuyoo .
Learning Human Kinematics by Modeling Temporal Correlations between Joints for Video-based Human Pose Estimation
Jul 22, 2022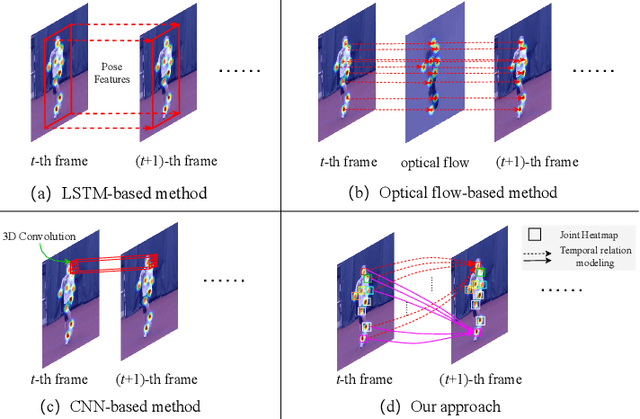

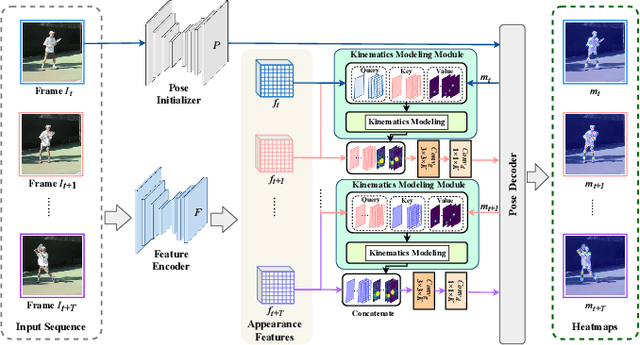

Estimating human poses from videos is critical in human-computer interaction. By precisely estimating human poses, the robot can provide an appropriate response to the human. Most existing approaches use the optical flow, RNNs, or CNNs to extract temporal features from videos. Despite the positive results of these attempts, most of them only straightforwardly integrate features along the temporal dimension, ignoring temporal correlations between joints. In contrast to previous methods, we propose a plug-and-play kinematics modeling module (KMM) based on the domain-cross attention mechanism to model the temporal correlation between joints across different frames explicitly. Specifically, the proposed KMM models the temporal correlation between any two joints by calculating their temporal similarity. In this way, KMM can learn the motion cues of each joint. Using the motion cues (temporal domain) and historical positions of joints (spatial domain), KMM can infer the initial positions of joints in the current frame in advance. In addition, we present a kinematics modeling network (KIMNet) based on the KMM for obtaining the final positions of joints by combining pose features and initial positions of joints. By explicitly modeling temporal correlations between joints, KIMNet can infer the occluded joints at present according to all joints at the previous moment. Furthermore, the KMM is achieved through an attention mechanism, which allows it to maintain the high resolution of features. Therefore, it can transfer rich historical pose information to the current frame, which provides effective pose information for locating occluded joints. Our approach achieves state-of-the-art results on two standard video-based pose estimation benchmarks. Moreover, the proposed KIMNet shows some robustness to the occlusion, demonstrating the effectiveness of the proposed method.