 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruGen: Automatic Instruction Generation for Vision-and-Language Navigation Via Large Multimodal Models
Paper and Code
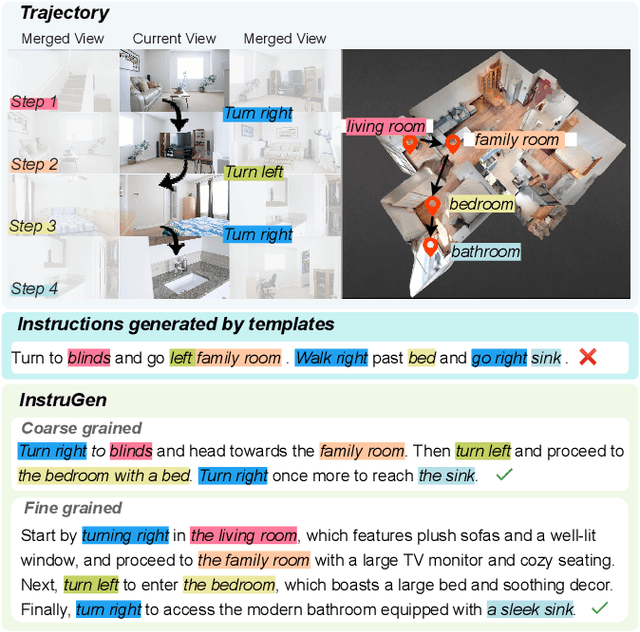
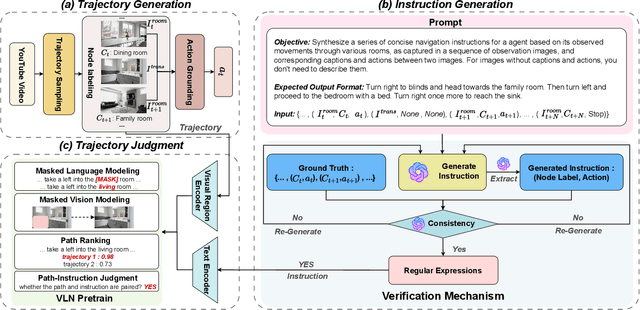


Recent research on Vision-and-Language Navigation (VLN) indicates that agents suffer from poor generalization in unseen environments due to the lack of realistic training environments and high-quality path-instruction pairs. Most existing methods for constructing realistic navigation scenes have high costs, and the extension of instructions mainly relies on predefined templates or rules, lacking adaptability. To alleviate the issue, we propose InstruGen, a VLN path-instruction pairs generation paradigm. Specifically, we use YouTube house tour videos as realistic navigation scenes and leverage the powerful visual understanding and generation abilities of large multimodal models (LMMs) to automatically generate diverse and high-quality VLN path-instruction pairs. Our method generates navigation instructions with different granularities and achieves fine-grained alignment between instructions and visual observations, which was difficult to achieve with previous methods. Additionally, we design a multi-stage verification mechanism to reduce hallucinations and inconsistency of LMMs. Experimental results demonstrate that agents trained with path-instruction pairs generated by InstruGen achieves state-of-the-art performance on the R2R and RxR benchmarks, particularly in unseen environments. Code is available at https://github.com/yanyu0526/InstruGen.