 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePM-KVQ: Progressive Mixed-precision KV Cache Quantization for Long-CoT LLMs
May 24, 2025



Recently, significant progress has been made in developing reasoning-capable Large Language Models (LLMs) through long Chain-of-Thought (CoT) techniques. However, this long-CoT reasoning process imposes substantial memory overhead due to the large Key-Value (KV) Cache memory overhead. Post-training KV Cache quantization has emerged as a promising compression technique and has been extensively studied in short-context scenarios. However, directly applying existing methods to long-CoT LLMs causes significant performance degradation due to the following two reasons: (1) Large cumulative error: Existing methods fail to adequately leverage available memory, and they directly quantize the KV Cache during each decoding step, leading to large cumulative quantization error. (2) Short-context calibration: Due to Rotary Positional Embedding (RoPE), the use of short-context data during calibration fails to account for the distribution of less frequent channels in the Key Cache, resulting in performance loss. We propose Progressive Mixed-Precision KV Cache Quantization (PM-KVQ) for long-CoT LLMs to address the above issues in two folds: (1) To reduce cumulative error, we design a progressive quantization strategy to gradually lower the bit-width of KV Cache in each block. Then, we propose block-wise memory allocation to assign a higher bit-width to more sensitive transformer blocks. (2) To increase the calibration length without additional overhead, we propose a new calibration strategy with positional interpolation that leverages short calibration data with positional interpolation to approximate the data distribution of long-context data. Extensive experiments on 7B-70B long-CoT LLMs show that PM-KVQ improves reasoning benchmark performance by up to 8% over SOTA baselines under the same memory budget. Our code is available at https://github.com/thu-nics/PM-KVQ.
FrameFusion: Combining Similarity and Importance for Video Token Reduction on Large Visual Language Models
Dec 30, 2024
The increasing demand to process long and high-resolution videos significantly burdens Large Vision-Language Models (LVLMs) due to the enormous number of visual tokens. Existing token reduction methods primarily focus on importance-based token pruning, which overlooks the redundancy caused by frame resemblance and repetitive visual elements. In this paper, we analyze the high vision token similarities in LVLMs. We reveal that token similarity distribution condenses as layers deepen while maintaining ranking consistency. Leveraging the unique properties of similarity over importance, we introduce FrameFusion, a novel approach that combines similarity-based merging with importance-based pruning for better token reduction in LVLMs. FrameFusion identifies and merges similar tokens before pruning, opening up a new perspective for token reduction. We evaluate FrameFusion on diverse LVLMs, including Llava-Video-{7B,32B,72B}, and MiniCPM-V-8B, on video understanding, question-answering, and retrieval benchmarks. Experiments show that FrameFusion reduces vision tokens by 70$\%$, achieving 3.4-4.4x LLM speedups and 1.6-1.9x end-to-end speedups, with an average performance impact of less than 3$\%$. Our code is available at https://github.com/thu-nics/FrameFusion.
Evaluating Quantized Large Language Models
Feb 28, 2024


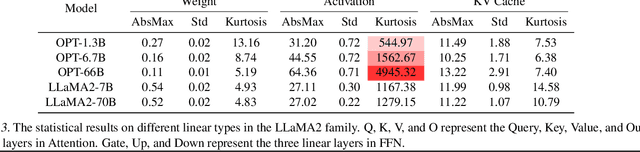
Post-training quantization (PTQ) has emerged as a promising technique to reduce the cost of large language models (LLMs). Specifically, PTQ can effectively mitigate memory consumption and reduce computational overhead in LLMs. To meet the requirements of both high efficiency and performance across diverse scenarios, a comprehensive evaluation of quantized LLMs is essential to guide the selection of quantization methods. This paper presents a thorough evaluation of these factors by evaluating the effect of PTQ on Weight, Activation, and KV Cache on 11 model families, including OPT, LLaMA2, Falcon, Bloomz, Mistral, ChatGLM, Vicuna, LongChat, StableLM, Gemma, and Mamba, with parameters ranging from 125M to 180B. The evaluation encompasses five types of tasks: basic NLP, emergent ability, trustworthiness, dialogue, and long-context tasks. Moreover, we also evaluate the state-of-the-art (SOTA) quantization methods to demonstrate their applicability. Based on the extensive experiments, we systematically summarize the effect of quantization, provide recommendations to apply quantization techniques, and point out future directions.