 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Rashomon Effect: How Personalization Can Help Adjust Interpretable Machine Learning Models to Individual Users
May 11, 2025The Rashomon effect describes the observation that in machine learning (ML) multiple models often achieve similar predictive performance while explaining the underlying relationships in different ways. This observation holds even for intrinsically interpretable models, such as Generalized Additive Models (GAMs), which offer users valuable insights into the model's behavior. Given the existence of multiple GAM configurations with similar predictive performance, a natural question is whether we can personalize these configurations based on users' needs for interpretability. In our study, we developed an approach to personalize models based on contextual bandits. In an online experiment with 108 users in a personalized treatment and a non-personalized control group, we found that personalization led to individualized rather than one-size-fits-all configurations. Despite these individual adjustments, the interpretability remained high across both groups, with users reporting a strong understanding of the models. Our research offers initial insights into the potential for personalizing interpretable ML.
Beware of "Explanations" of AI
Apr 09, 2025Understanding the decisions made and actions taken by increasingly complex AI system remains a key challenge. This has led to an expanding field of research in explainable artificial intelligence (XAI), highlighting the potential of explanations to enhance trust, support adoption, and meet regulatory standards. However, the question of what constitutes a "good" explanation is dependent on the goals, stakeholders, and context. At a high level, psychological insights such as the concept of mental model alignment can offer guidance, but success in practice is challenging due to social and technical factors. As a result of this ill-defined nature of the problem, explanations can be of poor quality (e.g. unfaithful, irrelevant, or incoherent), potentially leading to substantial risks. Instead of fostering trust and safety, poorly designed explanations can actually cause harm, including wrong decisions, privacy violations, manipulation, and even reduced AI adoption. Therefore, we caution stakeholders to beware of explanations of AI: while they can be vital, they are not automatically a remedy for transparency or responsible AI adoption, and their misuse or limitations can exacerbate harm. Attention to these caveats can help guide future research to improve the quality and impact of AI explanations.
CareerBERT: Matching Resumes to ESCO Jobs in a Shared Embedding Space for Generic Job Recommendations
Mar 03, 2025The rapidly evolving labor market, driven by technological advancements and economic shifts, presents significant challenges for traditional job matching and consultation services. In response, we introduce an advanced support tool for career counselors and job seekers based on CareerBERT, a novel approach that leverages the power of unstructured textual data sources, such as resumes, to provide more accurate and comprehensive job recommendations. In contrast to previous approaches that primarily focus on job recommendations based on a fixed set of concrete job advertisements, our approach involves the creation of a corpus that combines data from the European Skills, Competences, and Occupations (ESCO) taxonomy and EURopean Employment Services (EURES) job advertisements, ensuring an up-to-date and well-defined representation of general job titles in the labor market. Our two-step evaluation approach, consisting of an application-grounded evaluation using EURES job advertisements and a human-grounded evaluation using real-world resumes and Human Resources (HR) expert feedback, provides a comprehensive assessment of CareerBERT's performance. Our experimental results demonstrate that CareerBERT outperforms both traditional and state-of-the-art embedding approaches while showing robust effectiveness in human expert evaluations. These results confirm the effectiveness of CareerBERT in supporting career consultants by generating relevant job recommendations based on resumes, ultimately enhancing the efficiency of job consultations and expanding the perspectives of job seekers. This research contributes to the field of NLP and job recommendation systems, offering valuable insights for both researchers and practitioners in the domain of career consulting and job matching.
The Impact of Transparency in AI Systems on Users' Data-Sharing Intentions: A Scenario-Based Experiment
Feb 27, 2025



Artificial Intelligence (AI) systems are frequently employed in online services to provide personalized experiences to users based on large collections of data. However, AI systems can be designed in different ways, with black-box AI systems appearing as complex data-processing engines and white-box AI systems appearing as fully transparent data-processors. As such, it is reasonable to assume that these different design choices also affect user perception and thus their willingness to share data. To this end, we conducted a pre-registered, scenario-based online experiment with 240 participants and investigated how transparent and non-transparent data-processing entities influenced data-sharing intentions. Surprisingly, our results revealed no significant difference in willingness to share data across entities, challenging the notion that transparency increases data-sharing willingness. Furthermore, we found that a general attitude of trust towards AI has a significant positive influence, especially in the transparent AI condition, whereas privacy concerns did not significantly affect data-sharing decisions.
* This is the author's version of the paper presented at the 19th International Conference on Wirtschaftsinformatik (WI 2024). The official published version is available at https://aisel.aisnet.org/wi2024/38/
Quantifying Visual Properties of GAM Shape Plots: Impact on Perceived Cognitive Load and Interpretability
Sep 25, 2024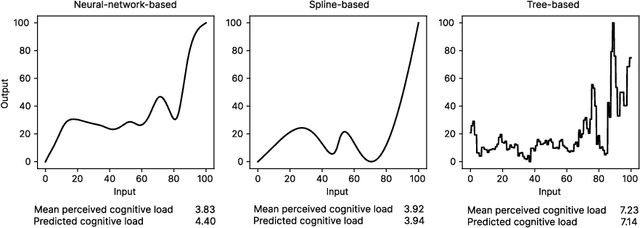
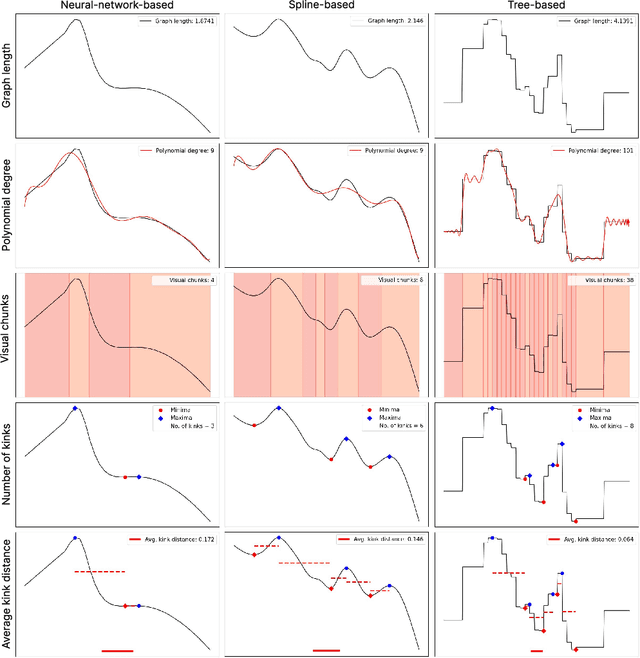

Generalized Additive Models (GAMs) offer a balance between performance and interpretability in machine learning. The interpretability aspect of GAMs is expressed through shape plots, representing the model's decision-making process. However, the visual properties of these plots, e.g. number of kinks (number of local maxima and minima), can impact their complexity and the cognitive load imposed on the viewer, compromising interpretability. Our study, including 57 participants, investigates the relationship between the visual properties of GAM shape plots and cognitive load they induce. We quantify various visual properties of shape plots and evaluate their alignment with participants' perceived cognitive load, based on 144 plots. Our results indicate that the number of kinks metric is the most effective, explaining 86.4% of the variance in users' ratings. We develop a simple model based on number of kinks that provides a practical tool for predicting cognitive load, enabling the assessment of one aspect of GAM interpretability without direct user involvement.
Challenging the Performance-Interpretability Trade-off: An Evaluation of Interpretable Machine Learning Models
Sep 22, 2024Machine learning is permeating every conceivable domain to promote data-driven decision support. The focus is often on advanced black-box models due to their assumed performance advantages, whereas interpretable models are often associated with inferior predictive qualities. More recently, however, a new generation of generalized additive models (GAMs) has been proposed that offer promising properties for capturing complex, non-linear patterns while remaining fully interpretable. To uncover the merits and limitations of these models, this study examines the predictive performance of seven different GAMs in comparison to seven commonly used machine learning models based on a collection of twenty tabular benchmark datasets. To ensure a fair and robust model comparison, an extensive hyperparameter search combined with cross-validation was performed, resulting in 68,500 model runs. In addition, this study qualitatively examines the visual output of the models to assess their level of interpretability. Based on these results, the paper dispels the misconception that only black-box models can achieve high accuracy by demonstrating that there is no strict trade-off between predictive performance and model interpretability for tabular data. Furthermore, the paper discusses the importance of GAMs as powerful interpretable models for the field of information systems and derives implications for future work from a socio-technical perspective.
IGANN Sparse: Bridging Sparsity and Interpretability with Non-linear Insight
Mar 17, 2024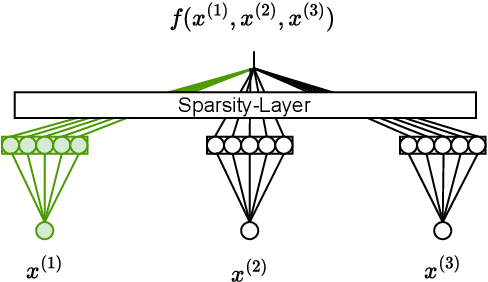
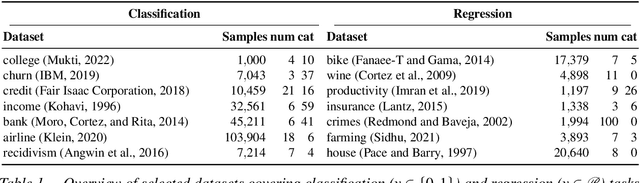
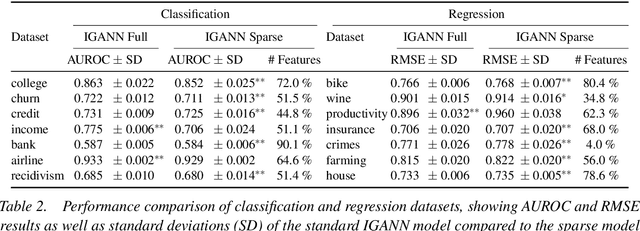
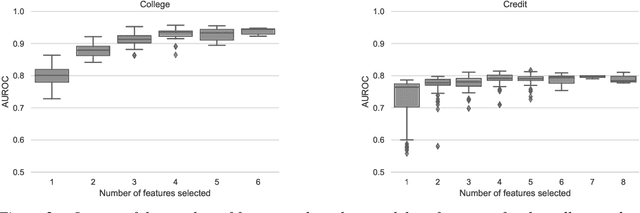
Feature selection is a critical component in predictive analytics that significantly affects the prediction accuracy and interpretability of models. Intrinsic methods for feature selection are built directly into model learning, providing a fast and attractive option for large amounts of data. Machine learning algorithms, such as penalized regression models (e.g., lasso) are the most common choice when it comes to in-built feature selection. However, they fail to capture non-linear relationships, which ultimately affects their ability to predict outcomes in intricate datasets. In this paper, we propose IGANN Sparse, a novel machine learning model from the family of generalized additive models, which promotes sparsity through a non-linear feature selection process during training. This ensures interpretability through improved model sparsity without sacrificing predictive performance. Moreover, IGANN Sparse serves as an exploratory tool for information systems researchers to unveil important non-linear relationships in domains that are characterized by complex patterns. Our ongoing research is directed at a thorough evaluation of the IGANN Sparse model, including user studies that allow to assess how well users of the model can benefit from the reduced number of features. This will allow for a deeper understanding of the interactions between linear vs. non-linear modeling, number of selected features, and predictive performance.
Generative AI
Sep 13, 2023The term "generative AI" refers to computational techniques that are capable of generating seemingly new, meaningful content such as text, images, or audio from training data. The widespread diffusion of this technology with examples such as Dall-E 2, GPT-4, and Copilot is currently revolutionizing the way we work and communicate with each other. In this article, we provide a conceptualization of generative AI as an entity in socio-technical systems and provide examples of models, systems, and applications. Based on that, we introduce limitations of current generative AI and provide an agenda for Business & Information Systems Engineering (BISE) research. Different from previous works, we focus on generative AI in the context of information systems, and, to this end, we discuss several opportunities and challenges that are unique to the BISE community and make suggestions for impactful directions for BISE research.
A Survey of Text Representation Methods and Their Genealogy
Nov 26, 2022In recent years, with the advent of highly scalable artificial-neural-network-based text representation methods the field of natural language processing has seen unprecedented growth and sophistication. It has become possible to distill complex linguistic information of text into multidimensional dense numeric vectors with the use of the distributional hypothesis. As a consequence, text representation methods have been evolving at such a quick pace that the research community is struggling to retain knowledge of the methods and their interrelations. We contribute threefold to this lack of compilation, composition, and systematization by providing a survey of current approaches, by arranging them in a genealogy, and by conceptualizing a taxonomy of text representation methods to examine and explain the state-of-the-art. Our research is a valuable guide and reference for artificial intelligence researchers and practitioners interested in natural language processing applications such as recommender systems, chatbots, and sentiment analysis.
* Published online in IEEE Access
GAM changer or not? An evaluation of interpretable machine learning models based on additive model constraints
Apr 19, 2022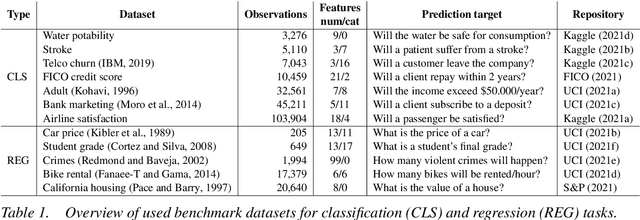
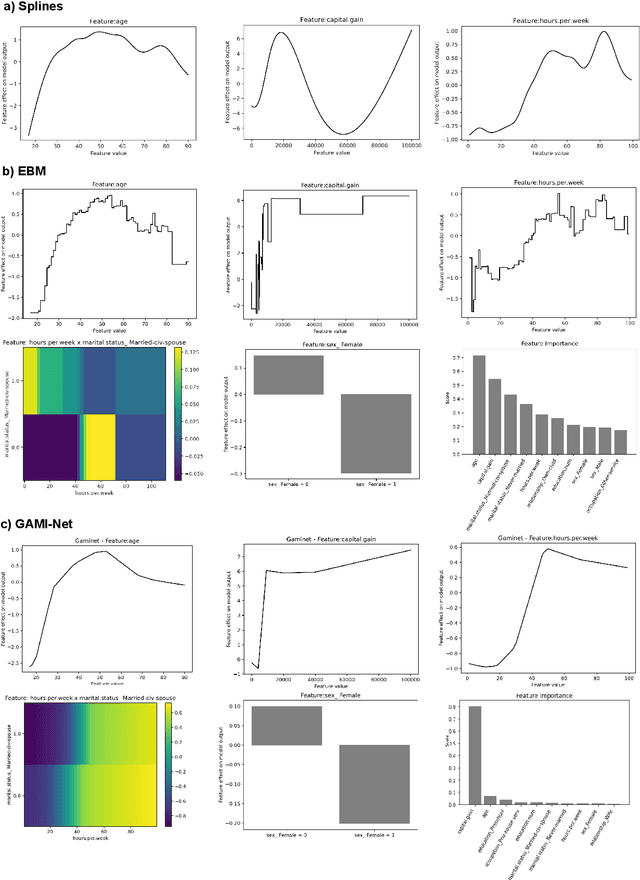
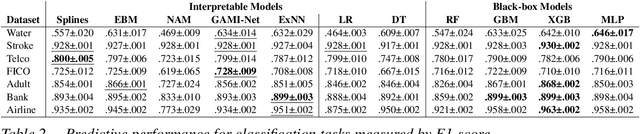
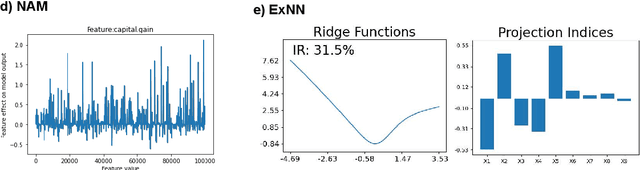
The number of information systems (IS) studies dealing with explainable artificial intelligence (XAI) is currently exploding as the field demands more transparency about the internal decision logic of machine learning (ML) models. However, most techniques subsumed under XAI provide post-hoc-analytical explanations, which have to be considered with caution as they only use approximations of the underlying ML model. Therefore, our paper investigates a series of intrinsically interpretable ML models and discusses their suitability for the IS community. More specifically, our focus is on advanced extensions of generalized additive models (GAM) in which predictors are modeled independently in a non-linear way to generate shape functions that can capture arbitrary patterns but remain fully interpretable. In our study, we evaluate the prediction qualities of five GAMs as compared to six traditional ML models and assess their visual outputs for model interpretability. On this basis, we investigate their merits and limitations and derive design implications for further improvements.