 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAM changer or not? An evaluation of interpretable machine learning models based on additive model constraints
Paper and Code
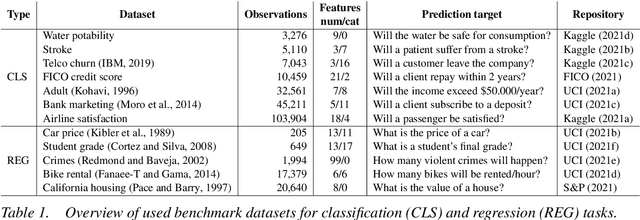
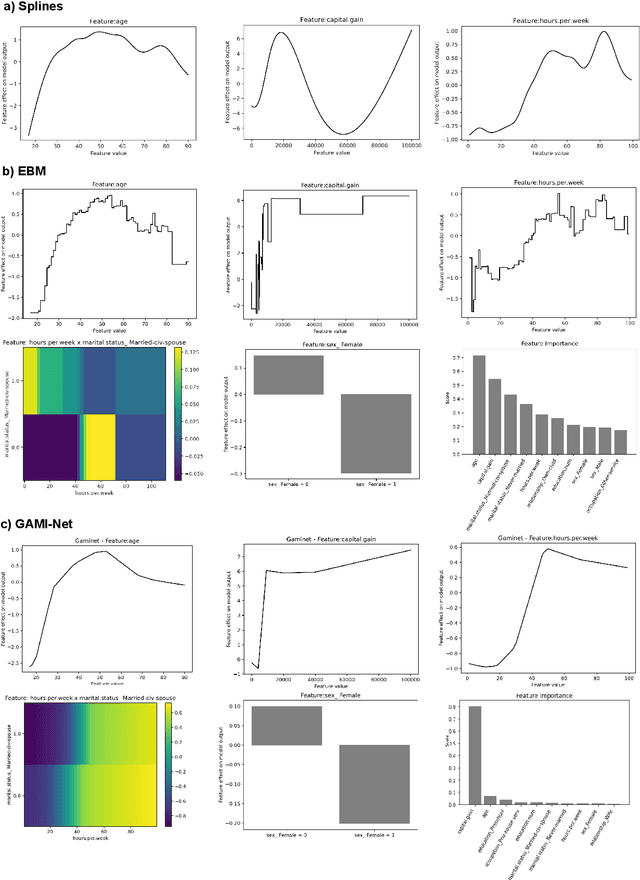
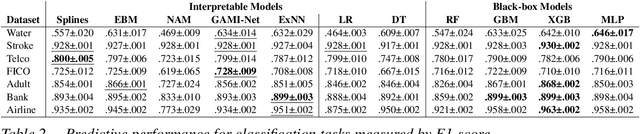
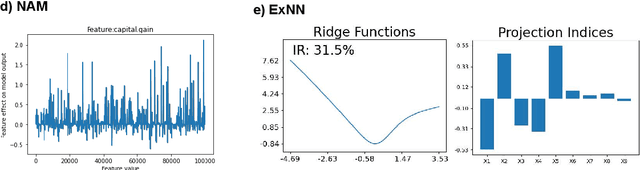
The number of information systems (IS) studies dealing with explainable artificial intelligence (XAI) is currently exploding as the field demands more transparency about the internal decision logic of machine learning (ML) models. However, most techniques subsumed under XAI provide post-hoc-analytical explanations, which have to be considered with caution as they only use approximations of the underlying ML model. Therefore, our paper investigates a series of intrinsically interpretable ML models and discusses their suitability for the IS community. More specifically, our focus is on advanced extensions of generalized additive models (GAM) in which predictors are modeled independently in a non-linear way to generate shape functions that can capture arbitrary patterns but remain fully interpretable. In our study, we evaluate the prediction qualities of five GAMs as compared to six traditional ML models and assess their visual outputs for model interpretability. On this basis, we investigate their merits and limitations and derive design implications for further improvements.