 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenging the Performance-Interpretability Trade-off: An Evaluation of Interpretable Machine Learning Models
Sep 22, 2024Machine learning is permeating every conceivable domain to promote data-driven decision support. The focus is often on advanced black-box models due to their assumed performance advantages, whereas interpretable models are often associated with inferior predictive qualities. More recently, however, a new generation of generalized additive models (GAMs) has been proposed that offer promising properties for capturing complex, non-linear patterns while remaining fully interpretable. To uncover the merits and limitations of these models, this study examines the predictive performance of seven different GAMs in comparison to seven commonly used machine learning models based on a collection of twenty tabular benchmark datasets. To ensure a fair and robust model comparison, an extensive hyperparameter search combined with cross-validation was performed, resulting in 68,500 model runs. In addition, this study qualitatively examines the visual output of the models to assess their level of interpretability. Based on these results, the paper dispels the misconception that only black-box models can achieve high accuracy by demonstrating that there is no strict trade-off between predictive performance and model interpretability for tabular data. Furthermore, the paper discusses the importance of GAMs as powerful interpretable models for the field of information systems and derives implications for future work from a socio-technical perspective.
IGANN Sparse: Bridging Sparsity and Interpretability with Non-linear Insight
Mar 17, 2024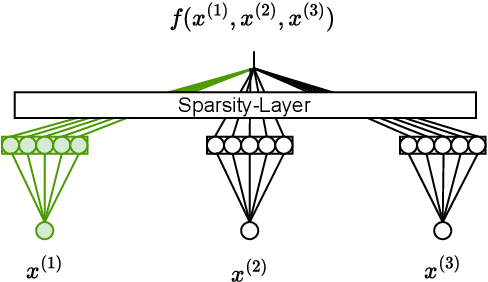
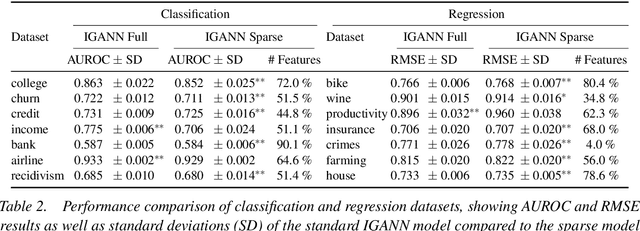
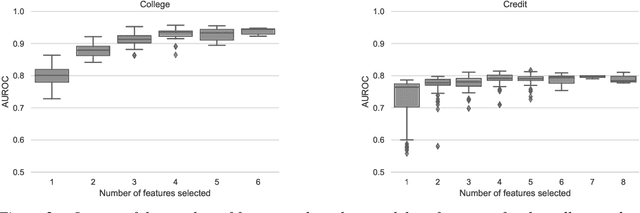
Feature selection is a critical component in predictive analytics that significantly affects the prediction accuracy and interpretability of models. Intrinsic methods for feature selection are built directly into model learning, providing a fast and attractive option for large amounts of data. Machine learning algorithms, such as penalized regression models (e.g., lasso) are the most common choice when it comes to in-built feature selection. However, they fail to capture non-linear relationships, which ultimately affects their ability to predict outcomes in intricate datasets. In this paper, we propose IGANN Sparse, a novel machine learning model from the family of generalized additive models, which promotes sparsity through a non-linear feature selection process during training. This ensures interpretability through improved model sparsity without sacrificing predictive performance. Moreover, IGANN Sparse serves as an exploratory tool for information systems researchers to unveil important non-linear relationships in domains that are characterized by complex patterns. Our ongoing research is directed at a thorough evaluation of the IGANN Sparse model, including user studies that allow to assess how well users of the model can benefit from the reduced number of features. This will allow for a deeper understanding of the interactions between linear vs. non-linear modeling, number of selected features, and predictive performance.
GAM changer or not? An evaluation of interpretable machine learning models based on additive model constraints
Apr 19, 2022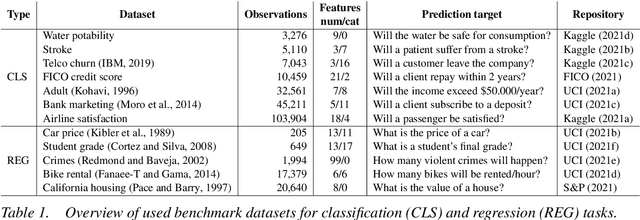
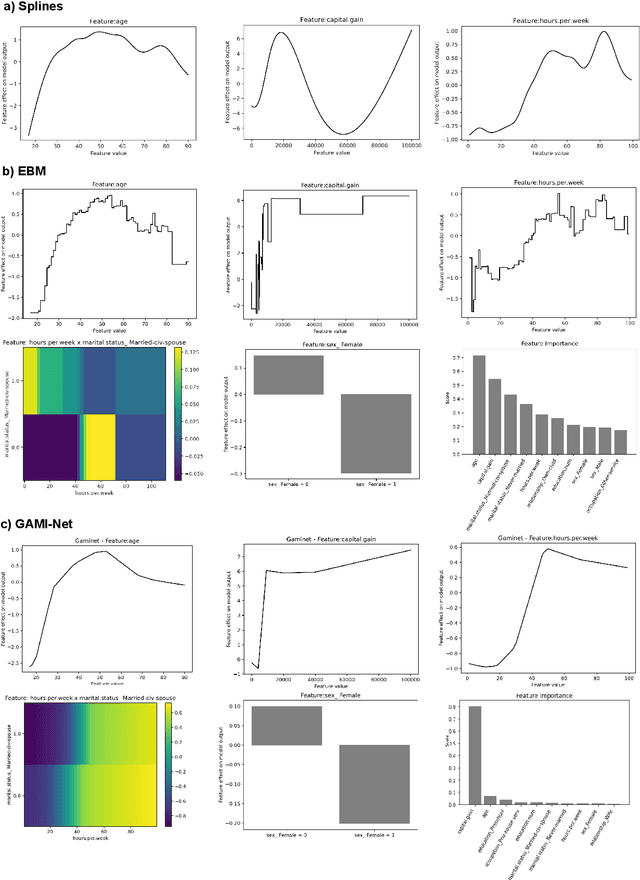
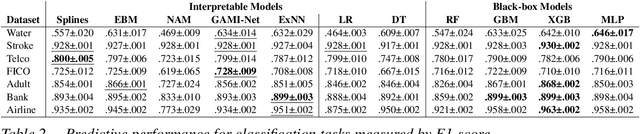
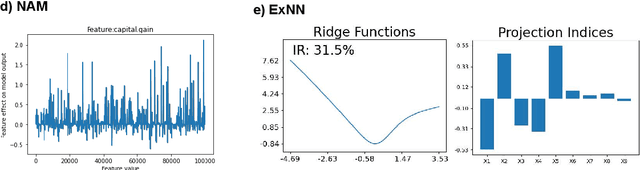
The number of information systems (IS) studies dealing with explainable artificial intelligence (XAI) is currently exploding as the field demands more transparency about the internal decision logic of machine learning (ML) models. However, most techniques subsumed under XAI provide post-hoc-analytical explanations, which have to be considered with caution as they only use approximations of the underlying ML model. Therefore, our paper investigates a series of intrinsically interpretable ML models and discusses their suitability for the IS community. More specifically, our focus is on advanced extensions of generalized additive models (GAM) in which predictors are modeled independently in a non-linear way to generate shape functions that can capture arbitrary patterns but remain fully interpretable. In our study, we evaluate the prediction qualities of five GAMs as compared to six traditional ML models and assess their visual outputs for model interpretability. On this basis, we investigate their merits and limitations and derive design implications for further improvements.
A Light in the Dark: Deep Learning Practices for Industrial Computer Vision
Jan 06, 2022
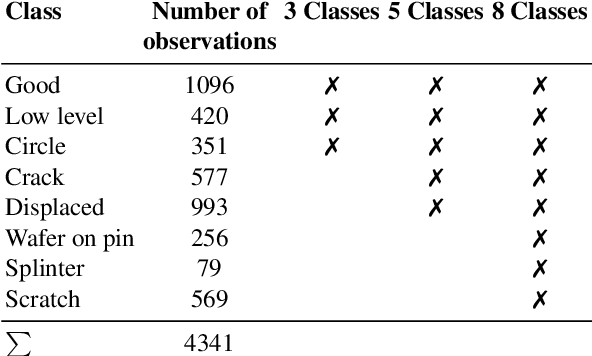
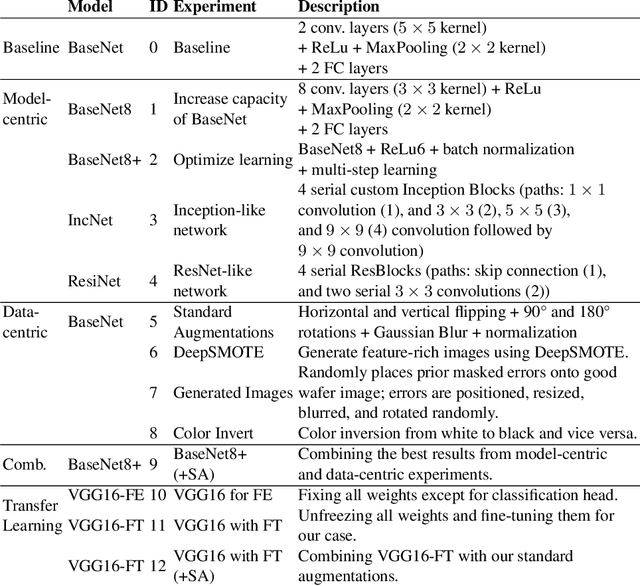
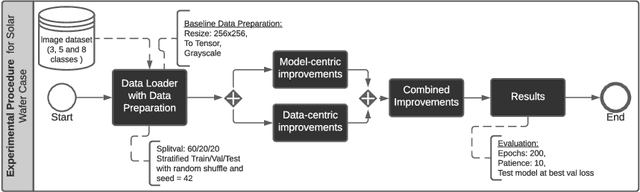
In recent years, large pre-trained deep neural networks (DNNs) have revolutionized the field of computer vision (CV). Although these DNNs have been shown to be very well suited for general image recognition tasks, application in industry is often precluded for three reasons: 1) large pre-trained DNNs are built on hundreds of millions of parameters, making deployment on many devices impossible, 2) the underlying dataset for pre-training consists of general objects, while industrial cases often consist of very specific objects, such as structures on solar wafers, 3) potentially biased pre-trained DNNs raise legal issues for companies. As a remedy, we study neural networks for CV that we train from scratch. For this purpose, we use a real-world case from a solar wafer manufacturer. We find that our neural networks achieve similar performances as pre-trained DNNs, even though they consist of far fewer parameters and do not rely on third-party datasets.