 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairLoop: Software Support for Human-Centric Fairness in Predictive Business Process Monitoring
Aug 27, 2025Sensitive attributes like gender or age can lead to unfair predictions in machine learning tasks such as predictive business process monitoring, particularly when used without considering context. We present FairLoop1, a tool for human-guided bias mitigation in neural network-based prediction models. FairLoop distills decision trees from neural networks, allowing users to inspect and modify unfair decision logic, which is then used to fine-tune the original model towards fairer predictions. Compared to other approaches to fairness, FairLoop enables context-aware bias removal through human involvement, addressing the influence of sensitive attributes selectively rather than excluding them uniformly.
A Human-In-The-Loop Approach for Improving Fairness in Predictive Business Process Monitoring
Aug 24, 2025Predictive process monitoring enables organizations to proactively react and intervene in running instances of a business process. Given an incomplete process instance, predictions about the outcome, next activity, or remaining time are created. This is done by powerful machine learning models, which have shown impressive predictive performance. However, the data-driven nature of these models makes them susceptible to finding unfair, biased, or unethical patterns in the data. Such patterns lead to biased predictions based on so-called sensitive attributes, such as the gender or age of process participants. Previous work has identified this problem and offered solutions that mitigate biases by removing sensitive attributes entirely from the process instance. However, sensitive attributes can be used both fairly and unfairly in the same process instance. For example, during a medical process, treatment decisions could be based on gender, while the decision to accept a patient should not be based on gender. This paper proposes a novel, model-agnostic approach for identifying and rectifying biased decisions in predictive business process monitoring models, even when the same sensitive attribute is used both fairly and unfairly. The proposed approach uses a human-in-the-loop approach to differentiate between fair and unfair decisions through simple alterations on a decision tree model distilled from the original prediction model. Our results show that the proposed approach achieves a promising tradeoff between fairness and accuracy in the presence of biased data. All source code and data are publicly available at https://doi.org/10.5281/zenodo.15387576.
From Source to Target: Leveraging Transfer Learning for Predictive Process Monitoring in Organizations
Aug 11, 2025Event logs reflect the behavior of business processes that are mapped in organizational information systems. Predictive process monitoring (PPM) transforms these data into value by creating process-related predictions that provide the insights required for proactive interventions at process runtime. Existing PPM techniques require sufficient amounts of event data or other relevant resources that might not be readily available, preventing some organizations from utilizing PPM. The transfer learning-based PPM technique presented in this paper allows organizations without suitable event data or other relevant resources to implement PPM for effective decision support. The technique is instantiated in two real-life use cases, based on which numerical experiments are performed using event logs for IT service management processes in an intra- and inter-organizational setting. The results of the experiments suggest that knowledge of one business process can be transferred to a similar business process in the same or a different organization to enable effective PPM in the target context. With the proposed technique, organizations can benefit from transfer learning in an intra- and inter-organizational setting, where resources like pre-trained models are transferred within and across organizational boundaries.
CareerBERT: Matching Resumes to ESCO Jobs in a Shared Embedding Space for Generic Job Recommendations
Mar 03, 2025The rapidly evolving labor market, driven by technological advancements and economic shifts, presents significant challenges for traditional job matching and consultation services. In response, we introduce an advanced support tool for career counselors and job seekers based on CareerBERT, a novel approach that leverages the power of unstructured textual data sources, such as resumes, to provide more accurate and comprehensive job recommendations. In contrast to previous approaches that primarily focus on job recommendations based on a fixed set of concrete job advertisements, our approach involves the creation of a corpus that combines data from the European Skills, Competences, and Occupations (ESCO) taxonomy and EURopean Employment Services (EURES) job advertisements, ensuring an up-to-date and well-defined representation of general job titles in the labor market. Our two-step evaluation approach, consisting of an application-grounded evaluation using EURES job advertisements and a human-grounded evaluation using real-world resumes and Human Resources (HR) expert feedback, provides a comprehensive assessment of CareerBERT's performance. Our experimental results demonstrate that CareerBERT outperforms both traditional and state-of-the-art embedding approaches while showing robust effectiveness in human expert evaluations. These results confirm the effectiveness of CareerBERT in supporting career consultants by generating relevant job recommendations based on resumes, ultimately enhancing the efficiency of job consultations and expanding the perspectives of job seekers. This research contributes to the field of NLP and job recommendation systems, offering valuable insights for both researchers and practitioners in the domain of career consulting and job matching.
(Neural-Symbolic) Machine Learning for Inconsistency Measurement
Feb 05, 2025



We present machine-learning-based approaches for determining the \emph{degree} of inconsistency -- which is a numerical value -- for propositional logic knowledge bases. Specifically, we present regression- and neural-based models that learn to predict the values that the inconsistency measures $\incmi$ and $\incat$ would assign to propositional logic knowledge bases. Our main motivation is that computing these values conventionally can be hard complexity-wise. As an important addition, we use specific postulates, that is, properties, of the underlying inconsistency measures to infer symbolic rules, which we combine with the learning-based models in the form of constraints. We perform various experiments and show that a) predicting the degree values is feasible in many situations, and b) including the symbolic constraints deduced from the rationality postulates increases the prediction quality.
Challenging the Performance-Interpretability Trade-off: An Evaluation of Interpretable Machine Learning Models
Sep 22, 2024Machine learning is permeating every conceivable domain to promote data-driven decision support. The focus is often on advanced black-box models due to their assumed performance advantages, whereas interpretable models are often associated with inferior predictive qualities. More recently, however, a new generation of generalized additive models (GAMs) has been proposed that offer promising properties for capturing complex, non-linear patterns while remaining fully interpretable. To uncover the merits and limitations of these models, this study examines the predictive performance of seven different GAMs in comparison to seven commonly used machine learning models based on a collection of twenty tabular benchmark datasets. To ensure a fair and robust model comparison, an extensive hyperparameter search combined with cross-validation was performed, resulting in 68,500 model runs. In addition, this study qualitatively examines the visual output of the models to assess their level of interpretability. Based on these results, the paper dispels the misconception that only black-box models can achieve high accuracy by demonstrating that there is no strict trade-off between predictive performance and model interpretability for tabular data. Furthermore, the paper discusses the importance of GAMs as powerful interpretable models for the field of information systems and derives implications for future work from a socio-technical perspective.
Documentation Practices of Artificial Intelligence
Jun 26, 2024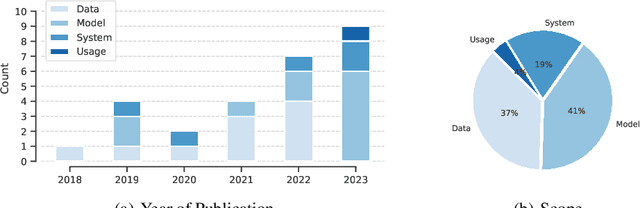
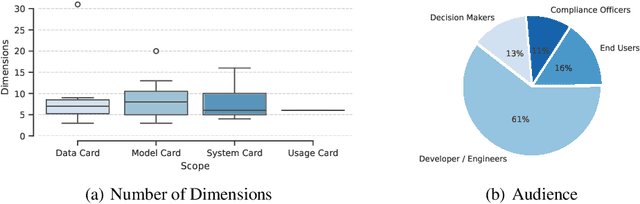
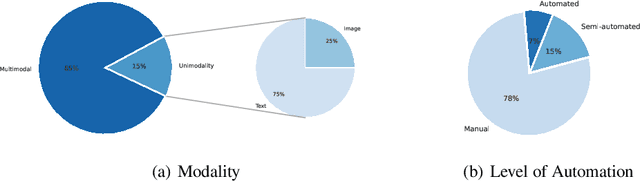
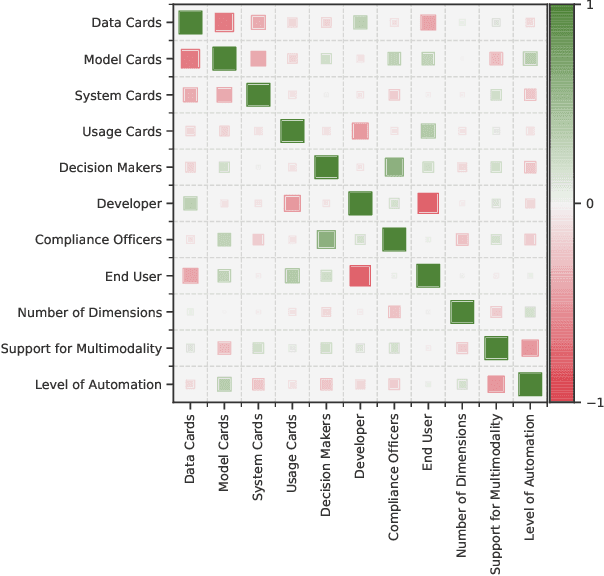
Artificial Intelligence (AI) faces persistent challenges in terms of transparency and accountability, which requires rigorous documentation. Through a literature review on documentation practices, we provide an overview of prevailing trends, persistent issues, and the multifaceted interplay of factors influencing the documentation. Our examination of key characteristics such as scope, target audiences, support for multimodality, and level of automation, highlights a dynamic evolution in documentation practices, underscored by a shift towards a more holistic, engaging, and automated documentation.
Recent Advances in Data-Driven Business Process Management
Jun 03, 2024



The rapid development of cutting-edge technologies, the increasing volume of data and also the availability and processability of new types of data sources has led to a paradigm shift in data-based management and decision-making. Since business processes are at the core of organizational work, these developments heavily impact BPM as a crucial success factor for organizations. In view of this emerging potential, data-driven business process management has become a relevant and vibrant research area. Given the complexity and interdisciplinarity of the research field, this position paper therefore presents research insights regarding data-driven BPM.
Machine learning in business process management: A systematic literature review
May 26, 2024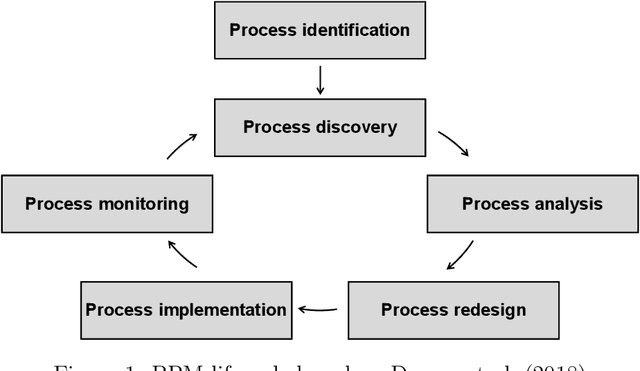

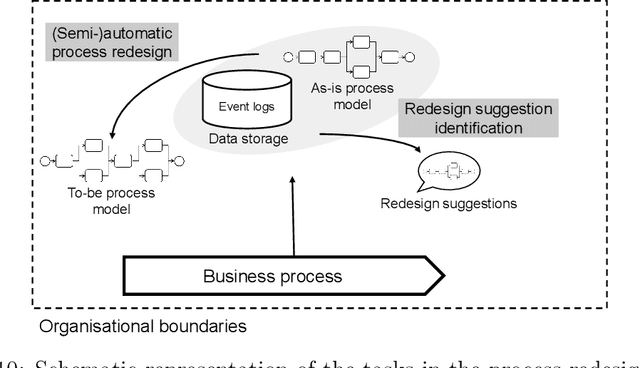
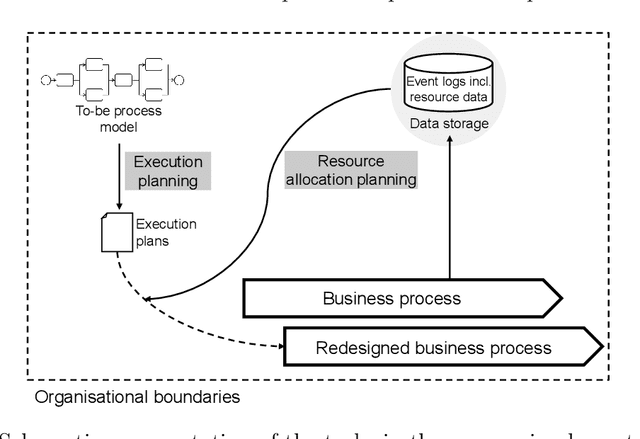
Machine learning (ML) provides algorithms to create computer programs based on data without explicitly programming them. In business process management (BPM), ML applications are used to analyse and improve processes efficiently. Three frequent examples of using ML are providing decision support through predictions, discovering accurate process models, and improving resource allocation. This paper organises the body of knowledge on ML in BPM. We extract BPM tasks from different literature streams, summarise them under the phases of a process`s lifecycle, explain how ML helps perform these tasks and identify technical commonalities in ML implementations across tasks. This study is the first exhaustive review of how ML has been used in BPM. We hope that it can open the door for a new era of cumulative research by helping researchers to identify relevant preliminary work and then combine and further develop existing approaches in a focused fashion. Our paper helps managers and consultants to find ML applications that are relevant in the current project phase of a BPM initiative, like redesigning a business process. We also offer - as a synthesis of our review - a research agenda that spreads ten avenues for future research, including applying novel ML concepts like federated learning, addressing less regarded BPM lifecycle phases like process identification, and delivering ML applications with a focus on end-users.
Driving Context into Text-to-Text Privatization
Jun 02, 2023\textit{Metric Differential Privacy} enables text-to-text privatization by adding calibrated noise to the vector of a word derived from an embedding space and projecting this noisy vector back to a discrete vocabulary using a nearest neighbor search. Since words are substituted without context, this mechanism is expected to fall short at finding substitutes for words with ambiguous meanings, such as \textit{'bank'}. To account for these ambiguous words, we leverage a sense embedding and incorporate a sense disambiguation step prior to noise injection. We encompass our modification to the privatization mechanism with an estimation of privacy and utility. For word sense disambiguation on the \textit{Words in Context} dataset, we demonstrate a substantial increase in classification accuracy by $6.05\%$.