 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization in Language Models through the Lens of Intrinsic Dimension
Jun 11, 2025Language Models (LMs) are prone to memorizing parts of their data during training and unintentionally emitting them at generation time, raising concerns about privacy leakage and disclosure of intellectual property. While previous research has identified properties such as context length, parameter size, and duplication frequency, as key drivers of unintended memorization, little is known about how the latent structure modulates this rate of memorization. We investigate the role of Intrinsic Dimension (ID), a geometric proxy for the structural complexity of a sequence in latent space, in modulating memorization. Our findings suggest that ID acts as a suppressive signal for memorization: compared to low-ID sequences, high-ID sequences are less likely to be memorized, particularly in overparameterized models and under sparse exposure. These findings highlight the interaction between scale, exposure, and complexity in shaping memorization.
Inspecting the Representation Manifold of Differentially-Private Text
Mar 19, 2025
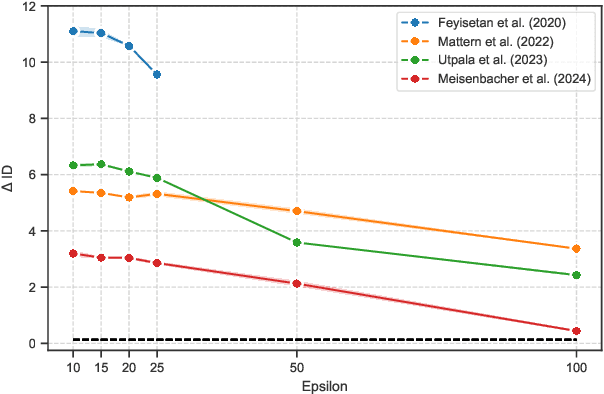

Differential Privacy (DP) for text has recently taken the form of text paraphrasing using language models and temperature sampling to better balance privacy and utility. However, the geometric distortion of DP regarding the structure and complexity in the representation space remains unexplored. By estimating the intrinsic dimension of paraphrased text across varying privacy budgets, we find that word-level methods severely raise the representation manifold, while sentence-level methods produce paraphrases whose manifolds are topologically more consistent with human-written paraphrases. Among sentence-level methods, masked paraphrasing, compared to causal paraphrasing, demonstrates superior preservation of structural complexity, suggesting that autoregressive generation propagates distortions from unnatural word choices that cascade and inflate the representation space.
Routing in Sparsely-gated Language Models responds to Context
Sep 21, 2024



Language Models (LMs) recently incorporate mixture-of-experts layers consisting of a router and a collection of experts to scale up their parameter count given a fixed computational budget. Building on previous efforts indicating that token-expert assignments are predominantly influenced by token identities and positions, we trace routing decisions of similarity-annotated text pairs to evaluate the context sensitivity of learned token-expert assignments. We observe that routing in encoder layers mainly depends on (semantic) associations, but contextual cues provide an additional layer of refinement. Conversely, routing in decoder layers is more variable and markedly less sensitive to context.
Characterizing Stereotypical Bias from Privacy-preserving Pre-Training
Jun 30, 2024Differential Privacy (DP) can be applied to raw text by exploiting the spatial arrangement of words in an embedding space. We investigate the implications of such text privatization on Language Models (LMs) and their tendency towards stereotypical associations. Since previous studies documented that linguistic proficiency correlates with stereotypical bias, one could assume that techniques for text privatization, which are known to degrade language modeling capabilities, would cancel out undesirable biases. By testing BERT models trained on texts containing biased statements primed with varying degrees of privacy, our study reveals that while stereotypical bias generally diminishes when privacy is tightened, text privatization does not uniformly equate to diminishing bias across all social domains. This highlights the need for careful diagnosis of bias in LMs that undergo text privatization.
Documentation Practices of Artificial Intelligence
Jun 26, 2024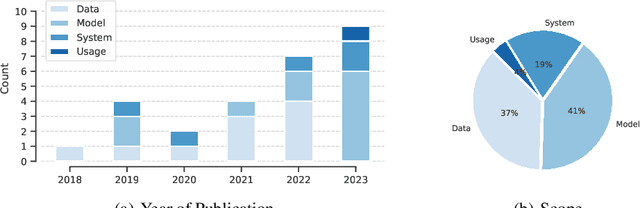
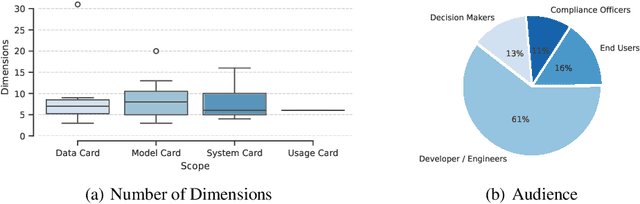
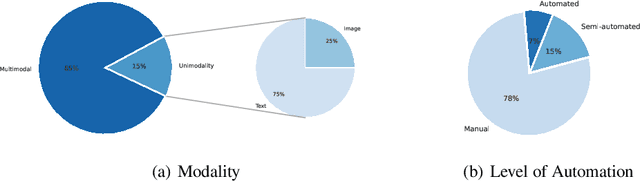
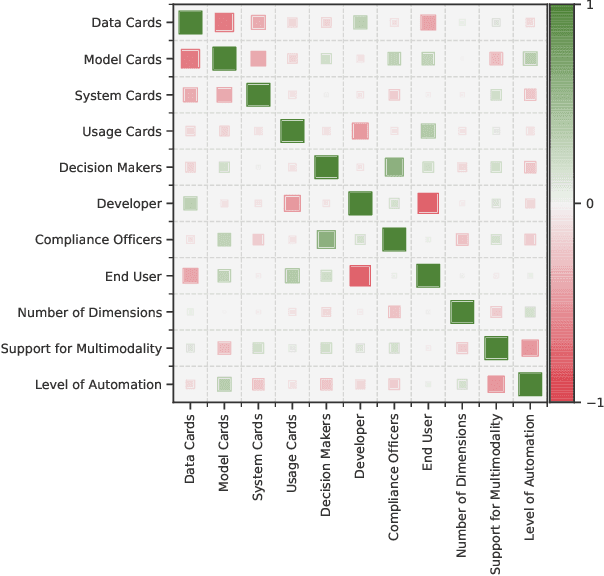
Artificial Intelligence (AI) faces persistent challenges in terms of transparency and accountability, which requires rigorous documentation. Through a literature review on documentation practices, we provide an overview of prevailing trends, persistent issues, and the multifaceted interplay of factors influencing the documentation. Our examination of key characteristics such as scope, target audiences, support for multimodality, and level of automation, highlights a dynamic evolution in documentation practices, underscored by a shift towards a more holistic, engaging, and automated documentation.
Disentangling the Linguistic Competence of Privacy-Preserving BERT
Oct 17, 2023



Differential Privacy (DP) has been tailored to address the unique challenges of text-to-text privatization. However, text-to-text privatization is known for degrading the performance of language models when trained on perturbed text. Employing a series of interpretation techniques on the internal representations extracted from BERT trained on perturbed pre-text, we intend to disentangle at the linguistic level the distortion induced by differential privacy. Experimental results from a representational similarity analysis indicate that the overall similarity of internal representations is substantially reduced. Using probing tasks to unpack this dissimilarity, we find evidence that text-to-text privatization affects the linguistic competence across several formalisms, encoding localized properties of words while falling short at encoding the contextual relationships between spans of words.
Guiding Text-to-Text Privatization by Syntax
Jun 02, 2023Metric Differential Privacy is a generalization of differential privacy tailored to address the unique challenges of text-to-text privatization. By adding noise to the representation of words in the geometric space of embeddings, words are replaced with words located in the proximity of the noisy representation. Since embeddings are trained based on word co-occurrences, this mechanism ensures that substitutions stem from a common semantic context. Without considering the grammatical category of words, however, this mechanism cannot guarantee that substitutions play similar syntactic roles. We analyze the capability of text-to-text privatization to preserve the grammatical category of words after substitution and find that surrogate texts consist almost exclusively of nouns. Lacking the capability to produce surrogate texts that correlate with the structure of the sensitive texts, we encompass our analysis by transforming the privatization step into a candidate selection problem in which substitutions are directed to words with matching grammatical properties. We demonstrate a substantial improvement in the performance of downstream tasks by up to $4.66\%$ while retaining comparative privacy guarantees.
Driving Context into Text-to-Text Privatization
Jun 02, 2023



\textit{Metric Differential Privacy} enables text-to-text privatization by adding calibrated noise to the vector of a word derived from an embedding space and projecting this noisy vector back to a discrete vocabulary using a nearest neighbor search. Since words are substituted without context, this mechanism is expected to fall short at finding substitutes for words with ambiguous meanings, such as \textit{'bank'}. To account for these ambiguous words, we leverage a sense embedding and incorporate a sense disambiguation step prior to noise injection. We encompass our modification to the privatization mechanism with an estimation of privacy and utility. For word sense disambiguation on the \textit{Words in Context} dataset, we demonstrate a substantial increase in classification accuracy by $6.05\%$.
Demystifying the Effects of Non-Independence in Federated Learning
Mar 20, 2021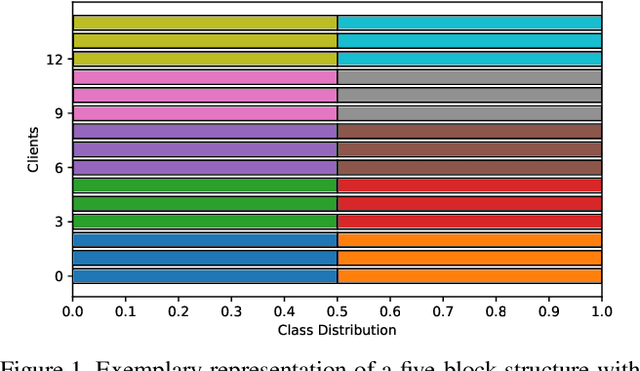
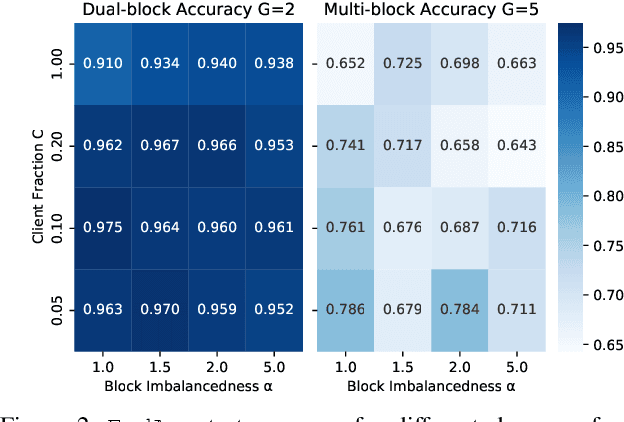
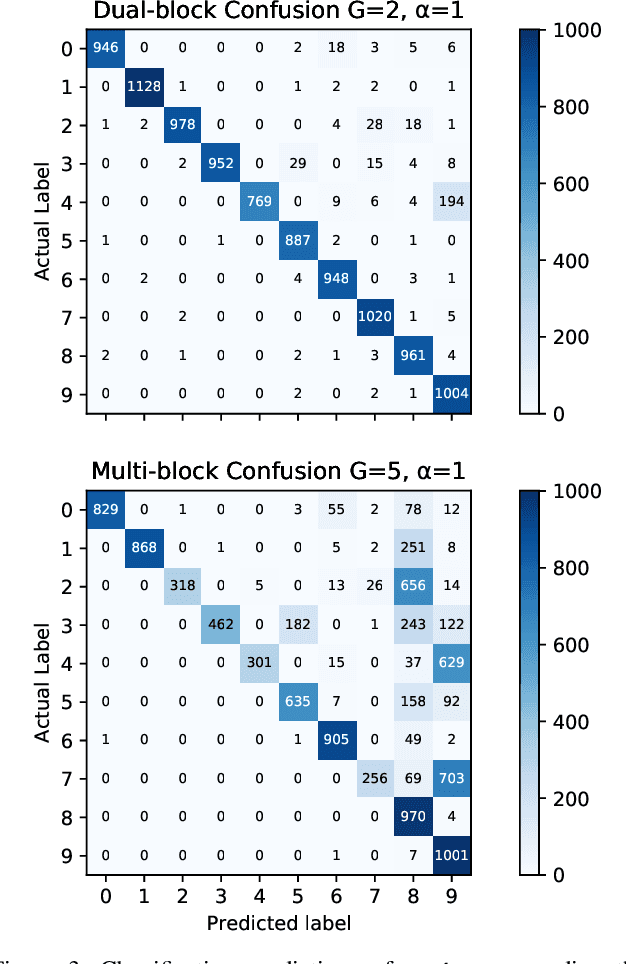

Federated Learning (FL) enables statistical models to be built on user-generated data without compromising data security and user privacy. For this reason, FL is well suited for on-device learning from mobile devices where data is abundant and highly privatized. Constrained by the temporal availability of mobile devices, only a subset of devices is accessible to participate in the iterative protocol consisting of training and aggregation. In this study, we take a step toward better understanding the effect of non-independent data distributions arising from block-cyclic sampling. By conducting extensive experiments on visual classification, we measure the effects of block-cyclic sampling (both standalone and in combination with non-balanced block distributions). Specifically, we measure the alterations induced by block-cyclic sampling from the perspective of accuracy, fairness, and convergence rate. Experimental results indicate robustness to cycling over a two-block structure, e.g., due to time zones. In contrast, drawing data samples dependently from a multi-block structure significantly degrades the performance and rate of convergence by up to 26%. Moreover, we find that this performance degeneration is further aggravated by unbalanced block distributions to a point that can no longer be adequately compensated by higher communication and more frequent synchronization.