 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Rashomon Effect: How Personalization Can Help Adjust Interpretable Machine Learning Models to Individual Users
May 11, 2025The Rashomon effect describes the observation that in machine learning (ML) multiple models often achieve similar predictive performance while explaining the underlying relationships in different ways. This observation holds even for intrinsically interpretable models, such as Generalized Additive Models (GAMs), which offer users valuable insights into the model's behavior. Given the existence of multiple GAM configurations with similar predictive performance, a natural question is whether we can personalize these configurations based on users' needs for interpretability. In our study, we developed an approach to personalize models based on contextual bandits. In an online experiment with 108 users in a personalized treatment and a non-personalized control group, we found that personalization led to individualized rather than one-size-fits-all configurations. Despite these individual adjustments, the interpretability remained high across both groups, with users reporting a strong understanding of the models. Our research offers initial insights into the potential for personalizing interpretable ML.
CareerBERT: Matching Resumes to ESCO Jobs in a Shared Embedding Space for Generic Job Recommendations
Mar 03, 2025The rapidly evolving labor market, driven by technological advancements and economic shifts, presents significant challenges for traditional job matching and consultation services. In response, we introduce an advanced support tool for career counselors and job seekers based on CareerBERT, a novel approach that leverages the power of unstructured textual data sources, such as resumes, to provide more accurate and comprehensive job recommendations. In contrast to previous approaches that primarily focus on job recommendations based on a fixed set of concrete job advertisements, our approach involves the creation of a corpus that combines data from the European Skills, Competences, and Occupations (ESCO) taxonomy and EURopean Employment Services (EURES) job advertisements, ensuring an up-to-date and well-defined representation of general job titles in the labor market. Our two-step evaluation approach, consisting of an application-grounded evaluation using EURES job advertisements and a human-grounded evaluation using real-world resumes and Human Resources (HR) expert feedback, provides a comprehensive assessment of CareerBERT's performance. Our experimental results demonstrate that CareerBERT outperforms both traditional and state-of-the-art embedding approaches while showing robust effectiveness in human expert evaluations. These results confirm the effectiveness of CareerBERT in supporting career consultants by generating relevant job recommendations based on resumes, ultimately enhancing the efficiency of job consultations and expanding the perspectives of job seekers. This research contributes to the field of NLP and job recommendation systems, offering valuable insights for both researchers and practitioners in the domain of career consulting and job matching.
The Impact of Transparency in AI Systems on Users' Data-Sharing Intentions: A Scenario-Based Experiment
Feb 27, 2025Artificial Intelligence (AI) systems are frequently employed in online services to provide personalized experiences to users based on large collections of data. However, AI systems can be designed in different ways, with black-box AI systems appearing as complex data-processing engines and white-box AI systems appearing as fully transparent data-processors. As such, it is reasonable to assume that these different design choices also affect user perception and thus their willingness to share data. To this end, we conducted a pre-registered, scenario-based online experiment with 240 participants and investigated how transparent and non-transparent data-processing entities influenced data-sharing intentions. Surprisingly, our results revealed no significant difference in willingness to share data across entities, challenging the notion that transparency increases data-sharing willingness. Furthermore, we found that a general attitude of trust towards AI has a significant positive influence, especially in the transparent AI condition, whereas privacy concerns did not significantly affect data-sharing decisions.
* This is the author's version of the paper presented at the 19th International Conference on Wirtschaftsinformatik (WI 2024). The official published version is available at https://aisel.aisnet.org/wi2024/38/
Quantifying Visual Properties of GAM Shape Plots: Impact on Perceived Cognitive Load and Interpretability
Sep 25, 2024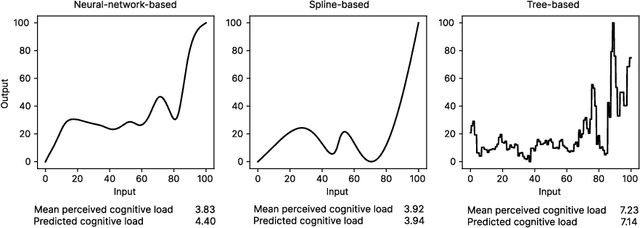
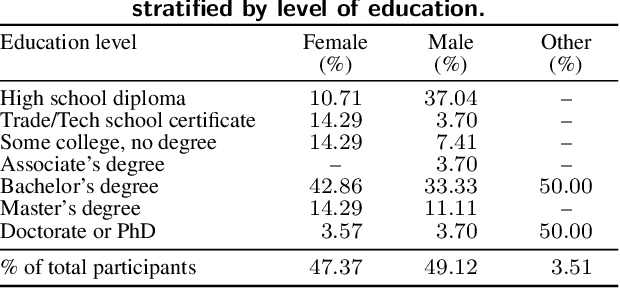
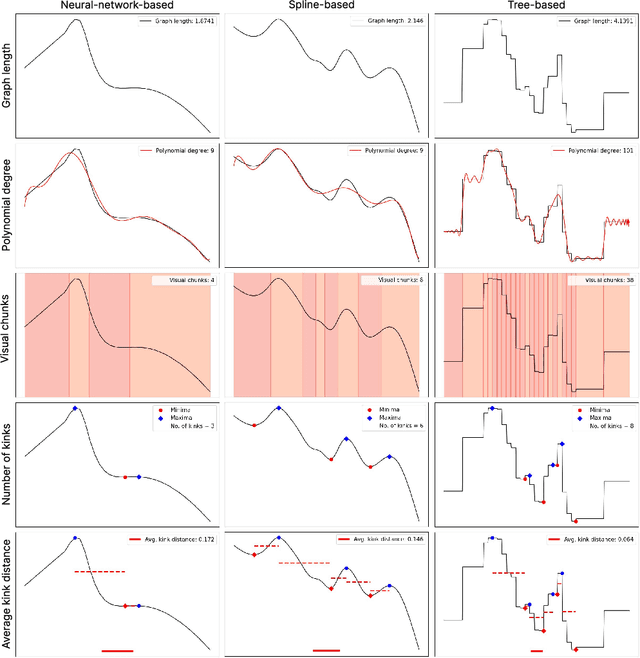

Generalized Additive Models (GAMs) offer a balance between performance and interpretability in machine learning. The interpretability aspect of GAMs is expressed through shape plots, representing the model's decision-making process. However, the visual properties of these plots, e.g. number of kinks (number of local maxima and minima), can impact their complexity and the cognitive load imposed on the viewer, compromising interpretability. Our study, including 57 participants, investigates the relationship between the visual properties of GAM shape plots and cognitive load they induce. We quantify various visual properties of shape plots and evaluate their alignment with participants' perceived cognitive load, based on 144 plots. Our results indicate that the number of kinks metric is the most effective, explaining 86.4% of the variance in users' ratings. We develop a simple model based on number of kinks that provides a practical tool for predicting cognitive load, enabling the assessment of one aspect of GAM interpretability without direct user involvement.