 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models for Natural Language Processing -- Pre-trained Language Models Integrating Media
Feb 16, 2023This open access book provides a comprehensive overview of the state of the art in research and applications of Foundation Models and is intended for readers familiar with basic Natural Language Processing (NLP) concepts. Over the recent years, a revolutionary new paradigm has been developed for training models for NLP. These models are first pre-trained on large collections of text documents to acquire general syntactic knowledge and semantic information. Then, they are fine-tuned for specific tasks, which they can often solve with superhuman accuracy. When the models are large enough, they can be instructed by prompts to solve new tasks without any fine-tuning. Moreover, they can be applied to a wide range of different media and problem domains, ranging from image and video processing to robot control learning. Because they provide a blueprint for solving many tasks in artificial intelligence, they have been called Foundation Models. After a brief introduction to basic NLP models the main pre-trained language models BERT, GPT and sequence-to-sequence transformer are described, as well as the concepts of self-attention and context-sensitive embedding. Then, different approaches to improving these models are discussed, such as expanding the pre-training criteria, increasing the length of input texts, or including extra knowledge. An overview of the best-performing models for about twenty application areas is then presented, e.g., question answering, translation, story generation, dialog systems, generating images from text, etc. For each application area, the strengths and weaknesses of current models are discussed, and an outlook on further developments is given. In addition, links are provided to freely available program code. A concluding chapter summarizes the economic opportunities, mitigation of risks, and potential developments of AI.
Second Order Probabilities for Uncertain and Conflicting Evidence
Mar 27, 2013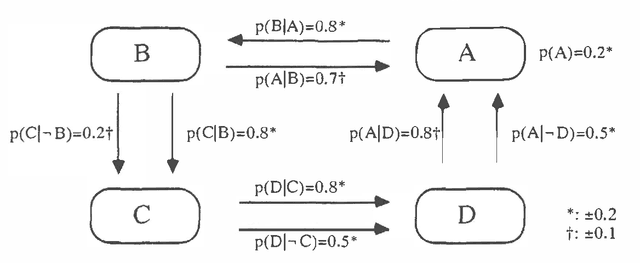
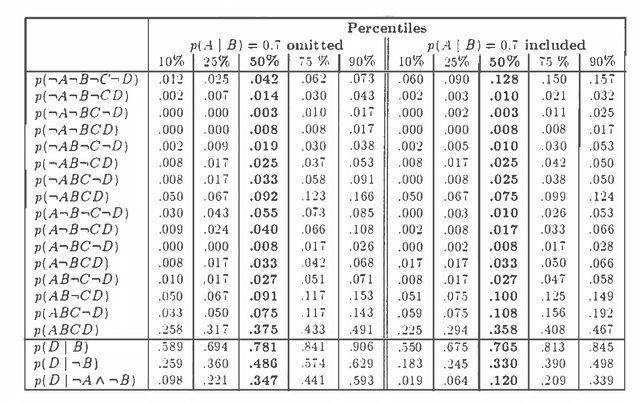
In this paper the elicitation of probabilities from human experts is considered as a measurement process, which may be disturbed by random 'measurement noise'. Using Bayesian concepts a second order probability distribution is derived reflecting the uncertainty of the input probabilities. The algorithm is based on an approximate sample representation of the basic probabilities. This sample is continuously modified by a stochastic simulation procedure, the Metropolis algorithm, such that the sequence of successive samples corresponds to the desired posterior distribution. The procedure is able to combine inconsistent probabilities according to their reliability and is applicable to general inference networks with arbitrary structure. Dempster-Shafer probability mass functions may be included using specific measurement distributions. The properties of the approach are demonstrated by numerical experiments.
MESA: Maximum Entropy by Simulated Annealing
Mar 13, 2013Probabilistic reasoning systems combine different probabilistic rules and probabilistic facts to arrive at the desired probability values of consequences. In this paper we describe the MESA-algorithm (Maximum Entropy by Simulated Annealing) that derives a joint distribution of variables or propositions. It takes into account the reliability of probability values and can resolve conflicts between contradictory statements. The joint distribution is represented in terms of marginal distributions and therefore allows to process large inference networks and to determine desired probability values with high precision. The procedure derives a maximum entropy distribution subject to the given constraints. It can be applied to inference networks of arbitrary topology and may be extended into a number of directions.