 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Tensor Fusion
May 07, 2024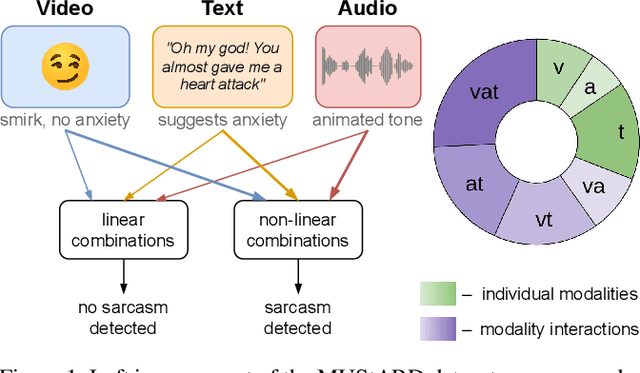
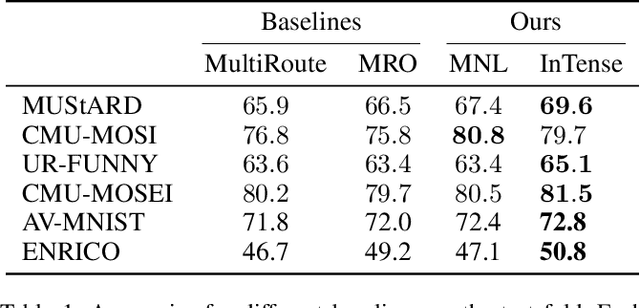
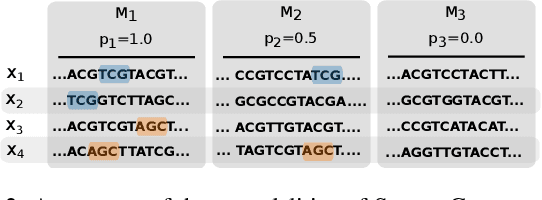
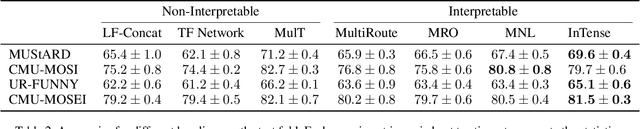
Conventional machine learning methods are predominantly designed to predict outcomes based on a single data type. However, practical applications may encompass data of diverse types, such as text, images, and audio. We introduce interpretable tensor fusion (InTense), a multimodal learning method for training neural networks to simultaneously learn multimodal data representations and their interpretable fusion. InTense can separately capture both linear combinations and multiplicative interactions of diverse data types, thereby disentangling higher-order interactions from the individual effects of each modality. InTense provides interpretability out of the box by assigning relevance scores to modalities and their associations. The approach is theoretically grounded and yields meaningful relevance scores on multiple synthetic and real-world datasets. Experiments on six real-world datasets show that InTense outperforms existing state-of-the-art multimodal interpretable approaches in terms of accuracy and interpretability.
Reimagining Anomalies: What If Anomalies Were Normal?
Feb 22, 2024Deep learning-based methods have achieved a breakthrough in image anomaly detection, but their complexity introduces a considerable challenge to understanding why an instance is predicted to be anomalous. We introduce a novel explanation method that generates multiple counterfactual examples for each anomaly, capturing diverse concepts of anomalousness. A counterfactual example is a modification of the anomaly that is perceived as normal by the anomaly detector. The method provides a high-level semantic explanation of the mechanism that triggered the anomaly detector, allowing users to explore "what-if scenarios." Qualitative and quantitative analyses across various image datasets show that the method applied to state-of-the-art anomaly detectors can achieve high-quality semantic explanations of detectors.
Learning Interpretable Concept Groups in CNNs
Sep 21, 2021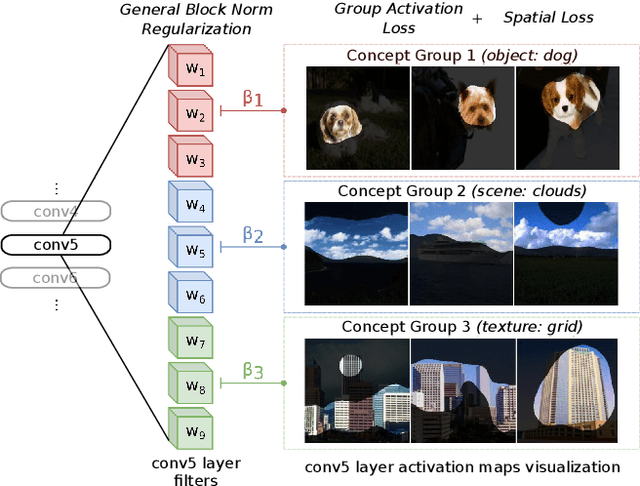
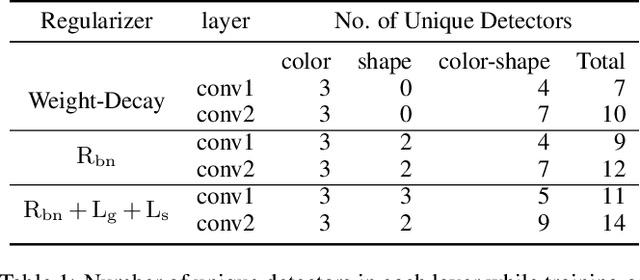
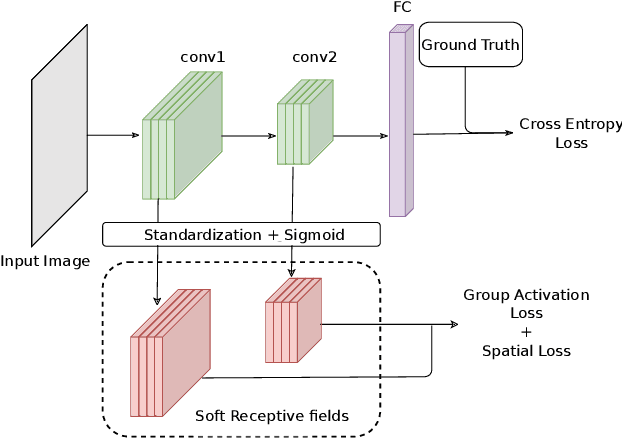
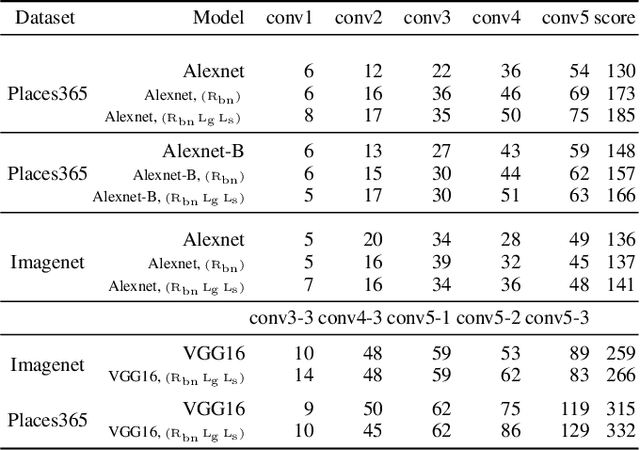
We propose a novel training methodology -- Concept Group Learning (CGL) -- that encourages training of interpretable CNN filters by partitioning filters in each layer into concept groups, each of which is trained to learn a single visual concept. We achieve this through a novel regularization strategy that forces filters in the same group to be active in similar image regions for a given layer. We additionally use a regularizer to encourage a sparse weighting of the concept groups in each layer so that a few concept groups can have greater importance than others. We quantitatively evaluate CGL's model interpretability using standard interpretability evaluation techniques and find that our method increases interpretability scores in most cases. Qualitatively we compare the image regions that are most active under filters learned using CGL versus filters learned without CGL and find that CGL activation regions more strongly concentrate around semantically relevant features.
Recognizing Challenging Handwritten Annotations with Fully Convolutional Networks
Jun 22, 2018


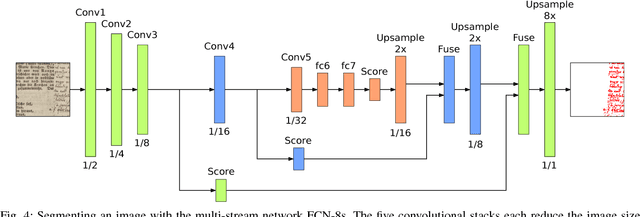
This paper introduces a very challenging dataset of historic German documents and evaluates Fully Convolutional Neural Network (FCNN) based methods to locate handwritten annotations of any kind in these documents. The handwritten annotations can appear in form of underlines and text by using various writing instruments, e.g., the use of pencils makes the data more challenging. We train and evaluate various end-to-end semantic segmentation approaches and report the results. The task is to classify the pixels of documents into two classes: background and handwritten annotation. The best model achieves a mean Intersection over Union (IoU) score of 95.6% on the test documents of the presented dataset. We also present a comparison of different strategies used for data augmentation and training on our presented dataset. For evaluation, we use the Layout Analysis Evaluator for the ICDAR 2017 Competition on Layout Analysis for Challenging Medieval Manuscripts.