 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoonBot: Modular and On-Demand Reconfigurable Robot Toward Moon Base Construction
Dec 26, 2025The allure of lunar surface exploration and development has recently captured widespread global attention. Robots have proved to be indispensable for exploring uncharted terrains, uncovering and leveraging local resources, and facilitating the construction of future human habitats. In this article, we introduce the modular and on-demand reconfigurable robot (MoonBot), a modular and reconfigurable robotic system engineered to maximize functionality while operating within the stringent mass constraints of lunar payloads and adapting to varying environmental conditions and task requirements. This article details the design and development of MoonBot and presents a preliminary field demonstration that validates the proof of concept through the execution of milestone tasks simulating the establishment of lunar infrastructure. These tasks include essential civil engineering operations, infrastructural component transportation and deployment, and assistive operations with inflatable modules. Furthermore, we systematically summarize the lessons learned during testing, focusing on the connector design and providing valuable insights for the advancement of modular robotic systems in future lunar missions.
Multi-Modal Decentralized Reinforcement Learning for Modular Reconfigurable Lunar Robots
Oct 23, 2025Modular reconfigurable robots suit task-specific space operations, but the combinatorial growth of morphologies hinders unified control. We propose a decentralized reinforcement learning (Dec-RL) scheme where each module learns its own policy: wheel modules use Soft Actor-Critic (SAC) for locomotion and 7-DoF limbs use Proximal Policy Optimization (PPO) for steering and manipulation, enabling zero-shot generalization to unseen configurations. In simulation, the steering policy achieved a mean absolute error of 3.63{\deg} between desired and induced angles; the manipulation policy plateaued at 84.6 % success on a target-offset criterion; and the wheel policy cut average motor torque by 95.4 % relative to baseline while maintaining 99.6 % success. Lunar-analogue field tests validated zero-shot integration for autonomous locomotion, steering, and preliminary alignment for reconfiguration. The system transitioned smoothly among synchronous, parallel, and sequential modes for Policy Execution, without idle states or control conflicts, indicating a scalable, reusable, and robust approach for modular lunar robots.
CoroNetGAN: Controlled Pruning of GANs via Hypernetworks
Mar 13, 2024



Generative Adversarial Networks (GANs) have proven to exhibit remarkable performance and are widely used across many generative computer vision applications. However, the unprecedented demand for the deployment of GANs on resource-constrained edge devices still poses a challenge due to huge number of parameters involved in the generation process. This has led to focused attention on the area of compressing GANs. Most of the existing works use knowledge distillation with the overhead of teacher dependency. Moreover, there is no ability to control the degree of compression in these methods. Hence, we propose CoroNet-GAN for compressing GAN using the combined strength of differentiable pruning method via hypernetworks. The proposed method provides the advantage of performing controllable compression while training along with reducing training time by a substantial factor. Experiments have been done on various conditional GAN architectures (Pix2Pix and CycleGAN) to signify the effectiveness of our approach on multiple benchmark datasets such as Edges-to-Shoes, Horse-to-Zebra and Summer-to-Winter. The results obtained illustrate that our approach succeeds to outperform the baselines on Zebra-to-Horse and Summer-to-Winter achieving the best FID score of 32.3 and 72.3 respectively, yielding high-fidelity images across all the datasets. Additionally, our approach also outperforms the state-of-the-art methods in achieving better inference time on various smart-phone chipsets and data-types making it a feasible solution for deployment on edge devices.
Chaurah: A Smart Raspberry Pi based Parking System
Dec 28, 2023The widespread usage of cars and other large, heavy vehicles necessitates the development of an effective parking infrastructure. Additionally, algorithms for detection and recognition of number plates are often used to identify automobiles all around the world where standardized plate sizes and fonts are enforced, making recognition an effortless task. As a result, both kinds of data can be combined to develop an intelligent parking system focuses on the technology of Automatic Number Plate Recognition (ANPR). Retrieving characters from an inputted number plate image is the sole purpose of ANPR which is a costly procedure. In this article, we propose Chaurah, a minimal cost ANPR system that relies on a Raspberry Pi 3 that was specifically created for parking facilities. The system employs a dual-stage methodology, with the first stage being an ANPR system which makes use of two convolutional neural networks (CNNs). The primary locates and recognises license plates from a vehicle image, while the secondary performs Optical Character Recognition (OCR) to identify individualized numbers from the number plate. An application built with Flutter and Firebase for database administration and license plate record comparison makes up the second component of the overall solution. The application also acts as an user-interface for the billing mechanism based on parking time duration resulting in an all-encompassing software deployment of the study.
A Survey on Deep Reinforcement Learning-based Approaches for Adaptation and Generalization
Feb 17, 2022
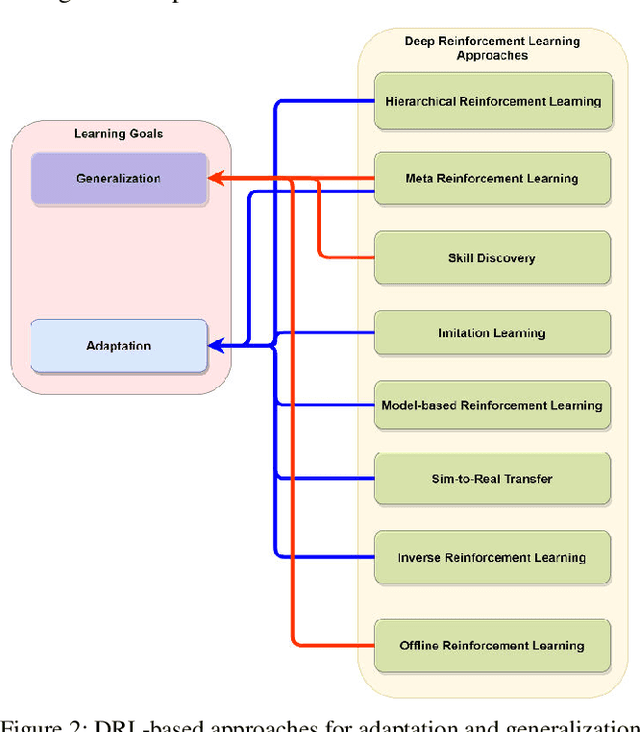
Deep Reinforcement Learning (DRL) aims to create intelligent agents that can learn to solve complex problems efficiently in a real-world environment. Typically, two learning goals: adaptation and generalization are used for baselining DRL algorithm's performance on different tasks and domains. This paper presents a survey on the recent developments in DRL-based approaches for adaptation and generalization. We begin by formulating these goals in the context of task and domain. Then we review the recent works under those approaches and discuss future research directions through which DRL algorithms' adaptability and generalizability can be enhanced and potentially make them applicable to a broad range of real-world problems.
Using Deep Object Features for Image Descriptions
Feb 25, 2019



Inspired by recent advances in leveraging multiple modalities in machine translation, we introduce an encoder-decoder pipeline that uses (1) specific objects within an image and their object labels, (2) a language model for decoding joint embedding of object features and the object labels. Our pipeline merges prior detected objects from the image and their object labels and then learns the sequences of captions describing the particular image. The decoder model learns to extract descriptions for the image from scratch by decoding the joint representation of the object visual features and their object classes conditioned by the encoder component. The idea of the model is to concentrate only on the specific objects of the image and their labels for generating descriptions of the image rather than visual feature of the entire image. The model needs to be calibrated more by adjusting the parameters and settings to result in better accuracy and performance.
Recognizing Challenging Handwritten Annotations with Fully Convolutional Networks
Jun 22, 2018


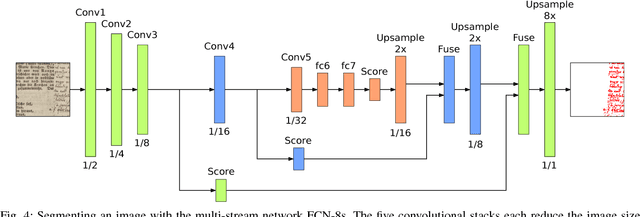
This paper introduces a very challenging dataset of historic German documents and evaluates Fully Convolutional Neural Network (FCNN) based methods to locate handwritten annotations of any kind in these documents. The handwritten annotations can appear in form of underlines and text by using various writing instruments, e.g., the use of pencils makes the data more challenging. We train and evaluate various end-to-end semantic segmentation approaches and report the results. The task is to classify the pixels of documents into two classes: background and handwritten annotation. The best model achieves a mean Intersection over Union (IoU) score of 95.6% on the test documents of the presented dataset. We also present a comparison of different strategies used for data augmentation and training on our presented dataset. For evaluation, we use the Layout Analysis Evaluator for the ICDAR 2017 Competition on Layout Analysis for Challenging Medieval Manuscripts.
A Low Complexity VLSI Architecture for Multi-Focus Image Fusion in DCT Domain
Sep 15, 2015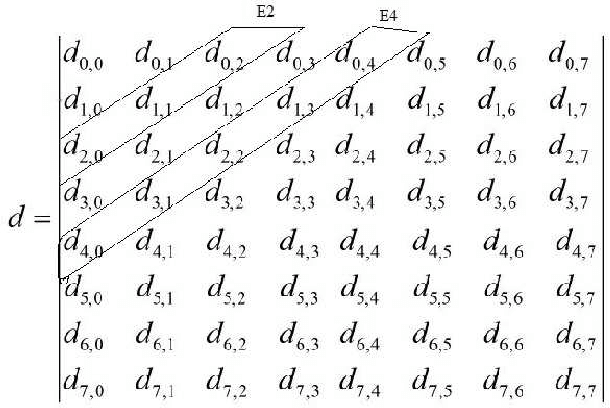

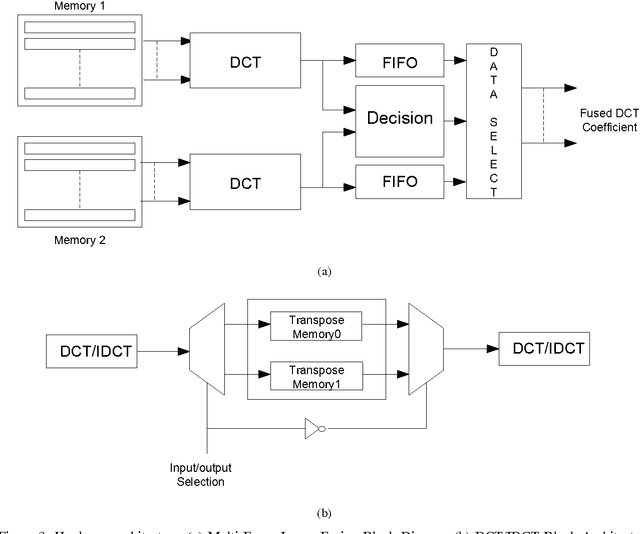

Due to the confined focal length of optical sensors, focusing all objects in a scene with a single sensor is a difficult task. To handle such a situation, image fusion methods are used in multi-focus environment. Discrete Cosine Transform (DCT) is a widely used image compression transform, image fusion in DCT domain is an efficient method. This paper presents a low complexity approach for multi-focus image fusion and its VLSI implementation using DCT. The proposed method is evaluated using reference/non-reference fusion measure criteria and the obtained results asserts it's effectiveness. The maximum synthesized frequency on FPGA is found to be 221 MHz and consumes 42% of FPGA resources. The proposed method consumes very less power and can process 4K resolution images at the rate of 60 frames per second which makes the hardware suitable for handheld portable devices such as camera module and wireless image sensors.