 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing Challenging Handwritten Annotations with Fully Convolutional Networks
Jun 22, 2018


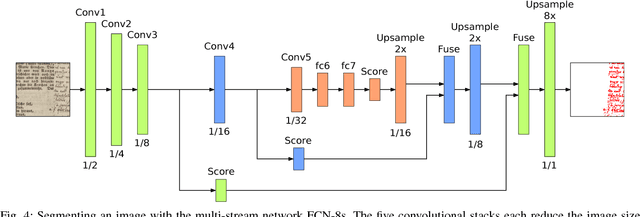
This paper introduces a very challenging dataset of historic German documents and evaluates Fully Convolutional Neural Network (FCNN) based methods to locate handwritten annotations of any kind in these documents. The handwritten annotations can appear in form of underlines and text by using various writing instruments, e.g., the use of pencils makes the data more challenging. We train and evaluate various end-to-end semantic segmentation approaches and report the results. The task is to classify the pixels of documents into two classes: background and handwritten annotation. The best model achieves a mean Intersection over Union (IoU) score of 95.6% on the test documents of the presented dataset. We also present a comparison of different strategies used for data augmentation and training on our presented dataset. For evaluation, we use the Layout Analysis Evaluator for the ICDAR 2017 Competition on Layout Analysis for Challenging Medieval Manuscripts.
Real-Time Document Image Classification using Deep CNN and Extreme Learning Machines
Nov 03, 2017


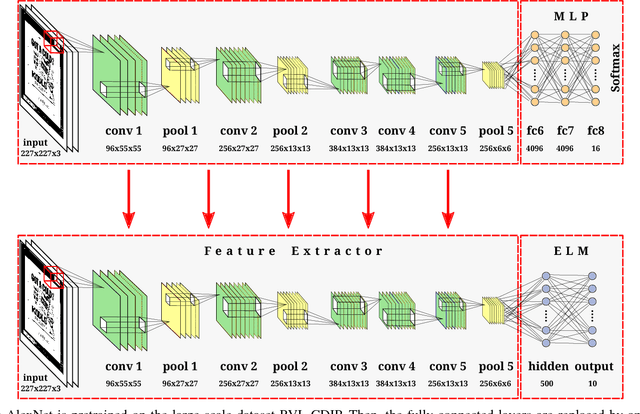
This paper presents an approach for real-time training and testing for document image classification. In production environments, it is crucial to perform accurate and (time-)efficient training. Existing deep learning approaches for classifying documents do not meet these requirements, as they require much time for training and fine-tuning the deep architectures. Motivated from Computer Vision, we propose a two-stage approach. The first stage trains a deep network that works as feature extractor and in the second stage, Extreme Learning Machines (ELMs) are used for classification. The proposed approach outperforms all previously reported structural and deep learning based methods with a final accuracy of 83.24% on Tobacco-3482 dataset, leading to a relative error reduction of 25% when compared to a previous Convolutional Neural Network (CNN) based approach (DeepDocClassifier). More importantly, the training time of the ELM is only 1.176 seconds and the overall prediction time for 2,482 images is 3.066 seconds. As such, this novel approach makes deep learning-based document classification suitable for large-scale real-time applications.
Cutting the Error by Half: Investigation of Very Deep CNN and Advanced Training Strategies for Document Image Classification
Apr 11, 2017

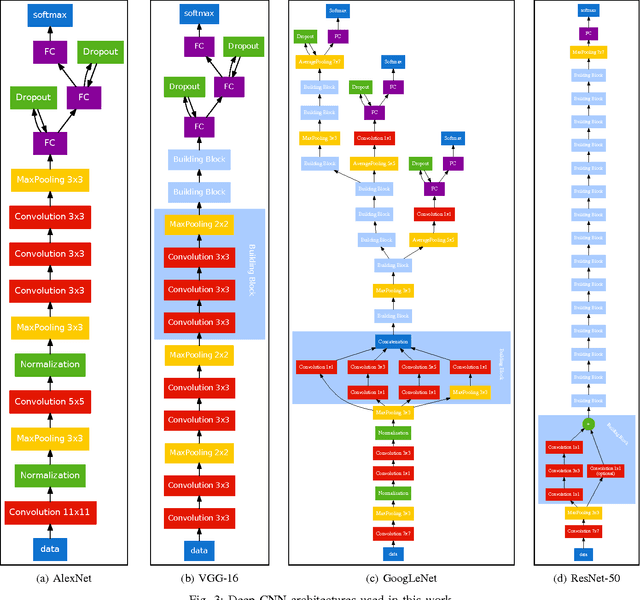
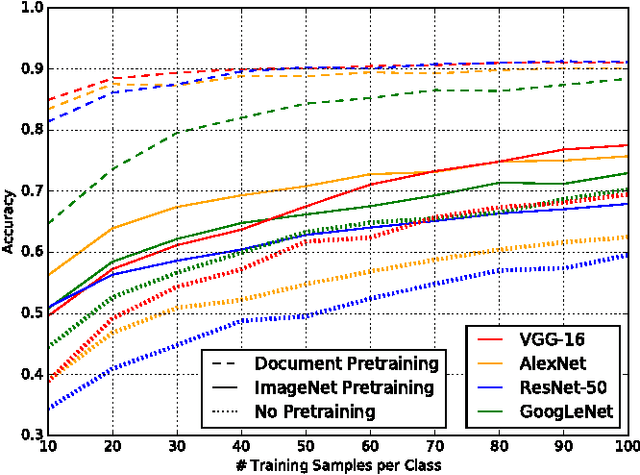
We present an exhaustive investigation of recent Deep Learning architectures, algorithms, and strategies for the task of document image classification to finally reduce the error by more than half. Existing approaches, such as the DeepDocClassifier, apply standard Convolutional Network architectures with transfer learning from the object recognition domain. The contribution of the paper is threefold: First, it investigates recently introduced very deep neural network architectures (GoogLeNet, VGG, ResNet) using transfer learning (from real images). Second, it proposes transfer learning from a huge set of document images, i.e. 400,000 documents. Third, it analyzes the impact of the amount of training data (document images) and other parameters to the classification abilities. We use two datasets, the Tobacco-3482 and the large-scale RVL-CDIP dataset. We achieve an accuracy of 91.13% for the Tobacco-3482 dataset while earlier approaches reach only 77.6%. Thus, a relative error reduction of more than 60% is achieved. For the large dataset RVL-CDIP, an accuracy of 90.97% is achieved, corresponding to a relative error reduction of 11.5%.
Multilevel Context Representation for Improving Object Recognition
Mar 19, 2017
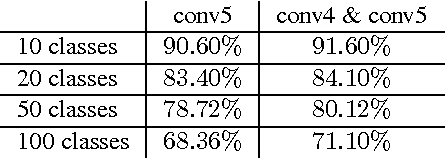

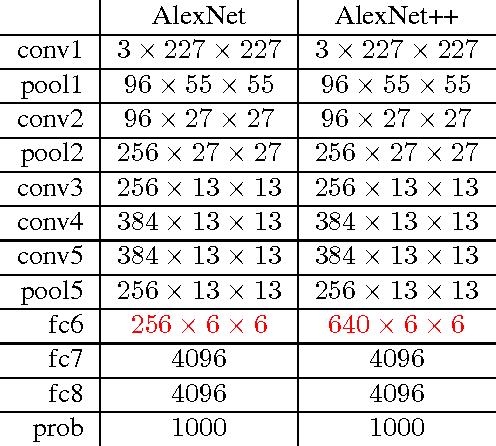
In this work, we propose the combined usage of low- and high-level blocks of convolutional neural networks (CNNs) for improving object recognition. While recent research focused on either propagating the context from all layers, e.g. ResNet, (including the very low-level layers) or having multiple loss layers (e.g. GoogLeNet), the importance of the features close to the higher layers is ignored. This paper postulates that the use of context closer to the high-level layers provides the scale and translation invariance and works better than using the top layer only. In particular, we extend AlexNet and GoogLeNet by additional connections in the top $n$ layers. In order to demonstrate the effectiveness of the proposed approach, we evaluated it on the standard ImageNet task. The relative reduction of the classification error is around 1-2% without affecting the computational cost. Furthermore, we show that this approach is orthogonal to typical test data augmentation techniques, as recently introduced by Szegedy et al. (leading to a runtime reduction of 144 during test time).