 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilevel Context Representation for Improving Object Recognition
Paper and Code
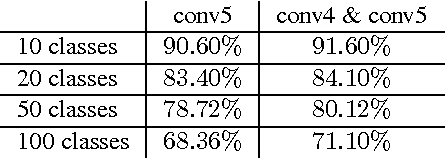

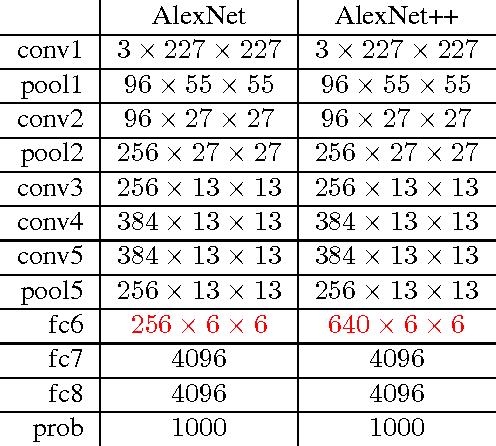
In this work, we propose the combined usage of low- and high-level blocks of convolutional neural networks (CNNs) for improving object recognition. While recent research focused on either propagating the context from all layers, e.g. ResNet, (including the very low-level layers) or having multiple loss layers (e.g. GoogLeNet), the importance of the features close to the higher layers is ignored. This paper postulates that the use of context closer to the high-level layers provides the scale and translation invariance and works better than using the top layer only. In particular, we extend AlexNet and GoogLeNet by additional connections in the top $n$ layers. In order to demonstrate the effectiveness of the proposed approach, we evaluated it on the standard ImageNet task. The relative reduction of the classification error is around 1-2% without affecting the computational cost. Furthermore, we show that this approach is orthogonal to typical test data augmentation techniques, as recently introduced by Szegedy et al. (leading to a runtime reduction of 144 during test time).