 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing Challenging Handwritten Annotations with Fully Convolutional Networks
Paper and Code



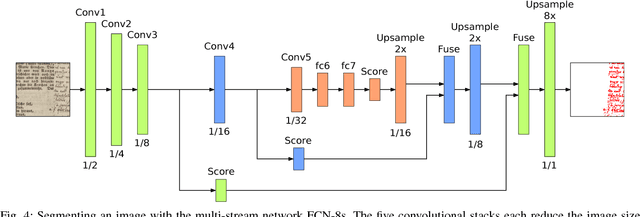
This paper introduces a very challenging dataset of historic German documents and evaluates Fully Convolutional Neural Network (FCNN) based methods to locate handwritten annotations of any kind in these documents. The handwritten annotations can appear in form of underlines and text by using various writing instruments, e.g., the use of pencils makes the data more challenging. We train and evaluate various end-to-end semantic segmentation approaches and report the results. The task is to classify the pixels of documents into two classes: background and handwritten annotation. The best model achieves a mean Intersection over Union (IoU) score of 95.6% on the test documents of the presented dataset. We also present a comparison of different strategies used for data augmentation and training on our presented dataset. For evaluation, we use the Layout Analysis Evaluator for the ICDAR 2017 Competition on Layout Analysis for Challenging Medieval Manuscripts.