 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoVe: Training Interactive Tool-Use Agents via Constraint-Guided Verification
Mar 02, 2026Developing multi-turn interactive tool-use agents is challenging because real-world user needs are often complex and ambiguous, yet agents must execute deterministic actions to satisfy them. To address this gap, we introduce \textbf{CoVe} (\textbf{Co}nstraint-\textbf{Ve}rification), a post-training data synthesis framework designed for training interactive tool-use agents while ensuring both data complexity and correctness. CoVe begins by defining explicit task constraints, which serve a dual role: they guide the generation of complex trajectories and act as deterministic verifiers for assessing trajectory quality. This enables the creation of high-quality training trajectories for supervised fine-tuning (SFT) and the derivation of accurate reward signals for reinforcement learning (RL). Our evaluation on the challenging $τ^2$-bench benchmark demonstrates the effectiveness of the framework. Notably, our compact \textbf{CoVe-4B} model achieves success rates of 43.0\% and 59.4\% in the Airline and Retail domains, respectively; its overall performance significantly outperforms strong baselines of similar scale and remains competitive with models up to $17\times$ its size. These results indicate that CoVe provides an effective and efficient pathway for synthesizing training data for state-of-the-art interactive tool-use agents. To support future research, we open-source our code, trained model, and the full set of 12K high-quality trajectories used for training.
Improve Sentence Alignment by Divide-and-conquer
Jan 18, 2022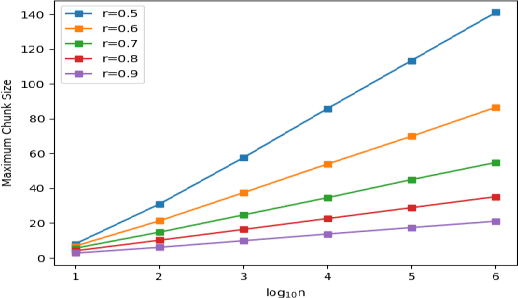
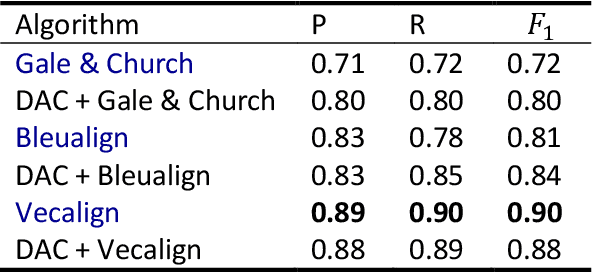
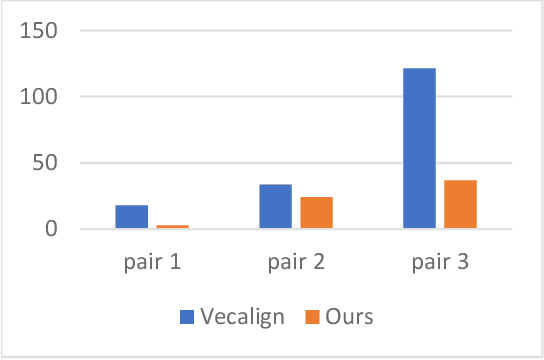
In this paper, we introduce a divide-and-conquer algorithm to improve sentence alignment speed. We utilize external bilingual sentence embeddings to find accurate hard delimiters for the parallel texts to be aligned. We use Monte Carlo simulation to show experimentally that using this divide-and-conquer algorithm, we can turn any quadratic time complexity sentence alignment algorithm into an algorithm with average time complexity of O(NlogN). On a standard OCR-generated dataset, our method improves the Bleualign baseline by 3 F1 points. Besides, when computational resources are restricted, our algorithm is faster than Vecalign in practice.
Adversarial Attack via Dual-Stage Network Erosion
Jan 01, 2022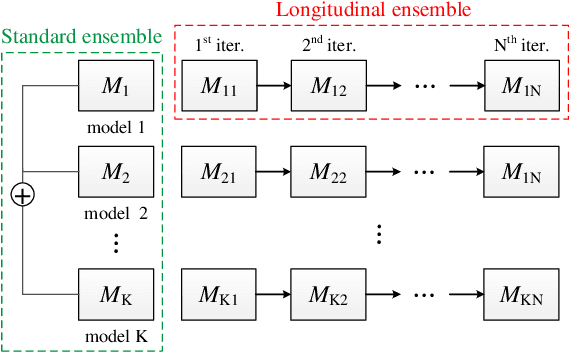
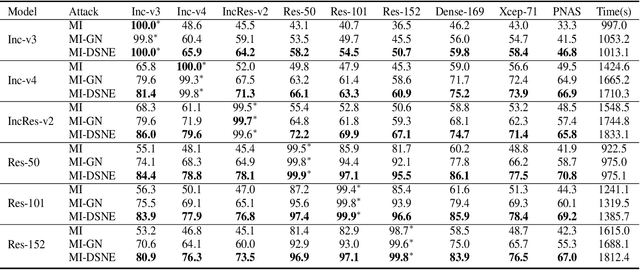
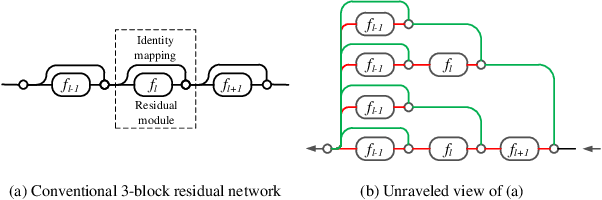
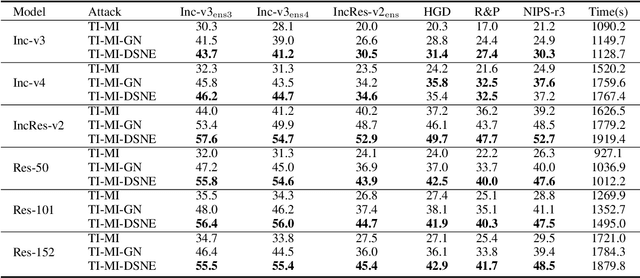
Deep neural networks are vulnerable to adversarial examples, which can fool deep models by adding subtle perturbations. Although existing attacks have achieved promising results, it still leaves a long way to go for generating transferable adversarial examples under the black-box setting. To this end, this paper proposes to improve the transferability of adversarial examples, and applies dual-stage feature-level perturbations to an existing model to implicitly create a set of diverse models. Then these models are fused by the longitudinal ensemble during the iterations. The proposed method is termed Dual-Stage Network Erosion (DSNE). We conduct comprehensive experiments both on non-residual and residual networks, and obtain more transferable adversarial examples with the computational cost similar to the state-of-the-art method. In particular, for the residual networks, the transferability of the adversarial examples can be significantly improved by biasing the residual block information to the skip connections. Our work provides new insights into the architectural vulnerability of neural networks and presents new challenges to the robustness of neural networks.
DPA: Learning Robust Physical Adversarial Camouflages for Object Detectors
Sep 01, 2021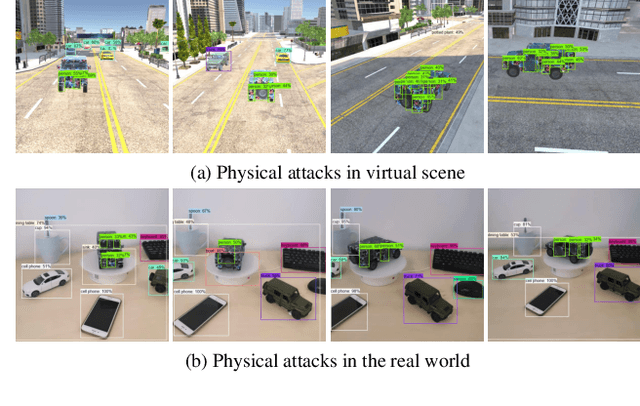

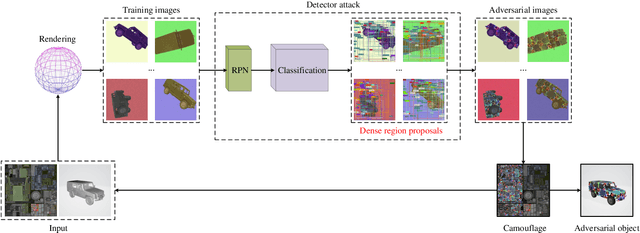

Adversarial attacks are feasible in the real world for object detection. However, most of the previous works have tried to learn "patches" applied to an object to fool detectors, which become less effective or even ineffective in squint view angles. To address this issue, we propose the Dense Proposals Attack (DPA) to learn robust, physical and targeted adversarial camouflages for detectors. The camouflages are robust because they remain adversarial when filmed under arbitrary viewpoint and different illumination conditions, physical because they function well both in the 3D virtual scene and the real world, and targeted because they can cause detectors to misidentify an object as a specific target class. In order to make the generated camouflages robust in the physical world, we introduce a combination of viewpoint shifts, lighting and other natural transformations to model the physical phenomena. In addition, to improve the attacks, DPA substantially attacks all the classifications in the fixed region proposals. Moreover, we build a virtual 3D scene using the Unity simulation engine to fairly and reproducibly evaluate different physical attacks. Extensive experiments demonstrate that DPA outperforms the state-of-the-art methods significantly, and generalizes well to the real world, posing a potential threat to the security-critical computer vision systems.
Gradient Episodic Memory with a Soft Constraint for Continual Learning
Nov 16, 2020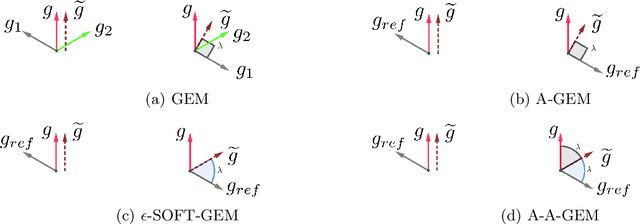

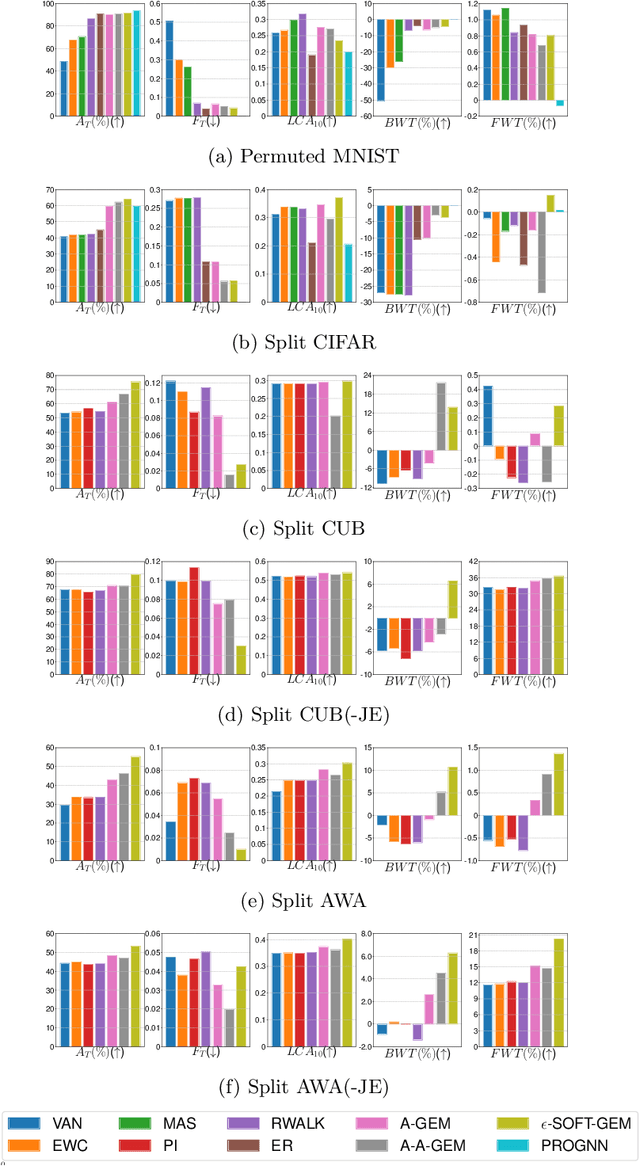

Catastrophic forgetting in continual learning is a common destructive phenomenon in gradient-based neural networks that learn sequential tasks, and it is much different from forgetting in humans, who can learn and accumulate knowledge throughout their whole lives. Catastrophic forgetting is the fatal shortcoming of a large decrease in performance on previous tasks when the model is learning a novel task. To alleviate this problem, the model should have the capacity to learn new knowledge and preserve learned knowledge. We propose an average gradient episodic memory (A-GEM) with a soft constraint $\epsilon \in [0, 1]$, which is a balance factor between learning new knowledge and preserving learned knowledge; our method is called gradient episodic memory with a soft constraint $\epsilon$ ($\epsilon$-SOFT-GEM). $\epsilon$-SOFT-GEM outperforms A-GEM and several continual learning benchmarks in a single training epoch; additionally, it has state-of-the-art average accuracy and efficiency for computation and memory, like A-GEM, and provides a better trade-off between the stability of preserving learned knowledge and the plasticity of learning new knowledge.