 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attack via Dual-Stage Network Erosion
Jan 01, 2022
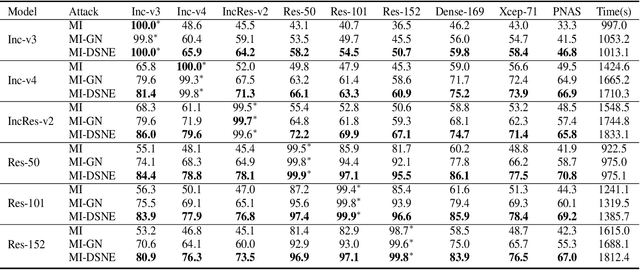
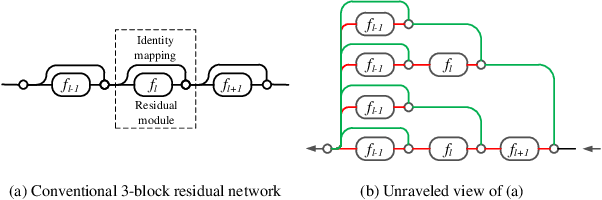
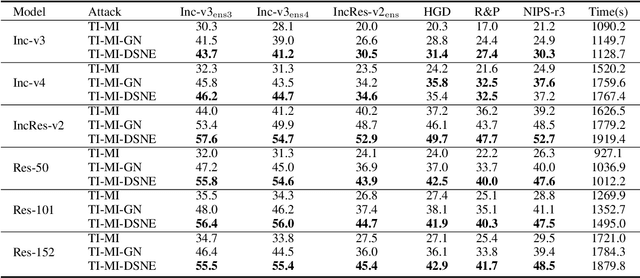
Deep neural networks are vulnerable to adversarial examples, which can fool deep models by adding subtle perturbations. Although existing attacks have achieved promising results, it still leaves a long way to go for generating transferable adversarial examples under the black-box setting. To this end, this paper proposes to improve the transferability of adversarial examples, and applies dual-stage feature-level perturbations to an existing model to implicitly create a set of diverse models. Then these models are fused by the longitudinal ensemble during the iterations. The proposed method is termed Dual-Stage Network Erosion (DSNE). We conduct comprehensive experiments both on non-residual and residual networks, and obtain more transferable adversarial examples with the computational cost similar to the state-of-the-art method. In particular, for the residual networks, the transferability of the adversarial examples can be significantly improved by biasing the residual block information to the skip connections. Our work provides new insights into the architectural vulnerability of neural networks and presents new challenges to the robustness of neural networks.
Improving the Transferability of Adversarial Examples with Resized-Diverse-Inputs, Diversity-Ensemble and Region Fitting
Dec 11, 2021
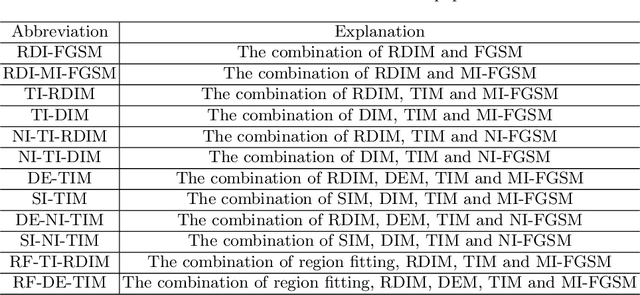


We introduce a three stage pipeline: resized-diverse-inputs (RDIM), diversity-ensemble (DEM) and region fitting, that work together to generate transferable adversarial examples. We first explore the internal relationship between existing attacks, and propose RDIM that is capable of exploiting this relationship. Then we propose DEM, the multi-scale version of RDIM, to generate multi-scale gradients. After the first two steps we transform value fitting into region fitting across iterations. RDIM and region fitting do not require extra running time and these three steps can be well integrated into other attacks. Our best attack fools six black-box defenses with a 93% success rate on average, which is higher than the state-of-the-art gradient-based attacks. Besides, we rethink existing attacks rather than simply stacking new methods on the old ones to get better performance. It is expected that our findings will serve as the beginning of exploring the internal relationship between attack methods. Codes are available at https://github.com/278287847/DEM.
DPA: Learning Robust Physical Adversarial Camouflages for Object Detectors
Sep 01, 2021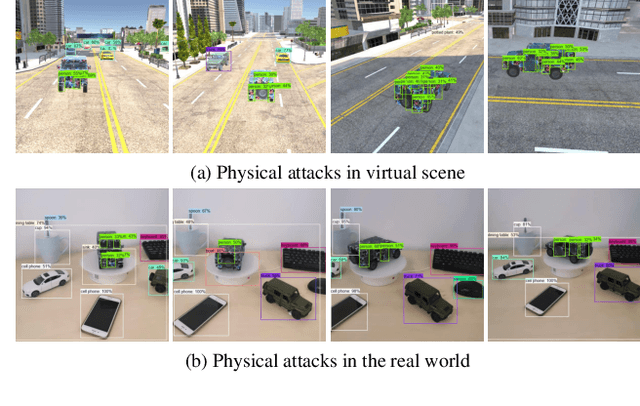

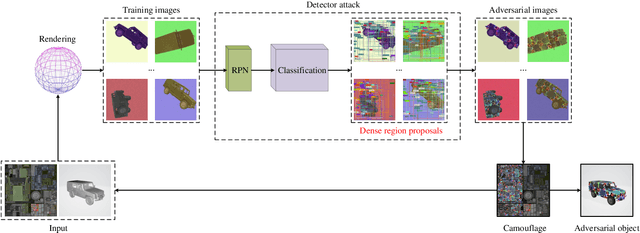

Adversarial attacks are feasible in the real world for object detection. However, most of the previous works have tried to learn "patches" applied to an object to fool detectors, which become less effective or even ineffective in squint view angles. To address this issue, we propose the Dense Proposals Attack (DPA) to learn robust, physical and targeted adversarial camouflages for detectors. The camouflages are robust because they remain adversarial when filmed under arbitrary viewpoint and different illumination conditions, physical because they function well both in the 3D virtual scene and the real world, and targeted because they can cause detectors to misidentify an object as a specific target class. In order to make the generated camouflages robust in the physical world, we introduce a combination of viewpoint shifts, lighting and other natural transformations to model the physical phenomena. In addition, to improve the attacks, DPA substantially attacks all the classifications in the fixed region proposals. Moreover, we build a virtual 3D scene using the Unity simulation engine to fairly and reproducibly evaluate different physical attacks. Extensive experiments demonstrate that DPA outperforms the state-of-the-art methods significantly, and generalizes well to the real world, posing a potential threat to the security-critical computer vision systems.
Making Adversarial Examples More Transferable and Indistinguishable
Jul 08, 2020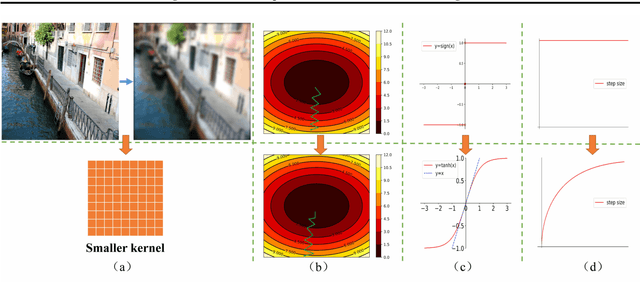


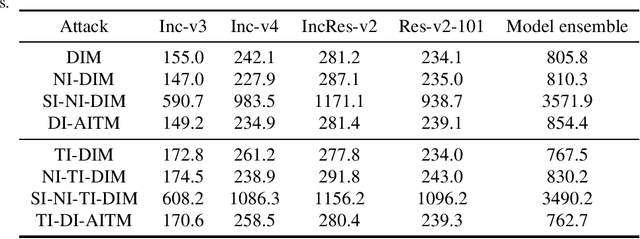
Many previous methods generate adversarial examples based on the fast gradient sign attack series. However, these methods cannot balance the indistinguishability and transferability due to the limitations of the basic sign structure. To address this problem, we propose an ADAM iterative fast gradient tanh method (AI-FGTM) to generate indistinguishable adversarial examples with high transferability. Extensive experiments on the ImageNet dataset show that our method generates more indistinguishable adversarial examples and achieves higher black-box attack success rates without extra running time and resource. Our best attack, TI-DI-AITM, can fool six black-box defense models with an average success rate of 88.0\%. We expect that our method will serve as a new baseline for generating adversarial examples with more transferability and indistinguishability.