 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Episodic Memory with a Soft Constraint for Continual Learning
Paper and Code
Nov 16, 2020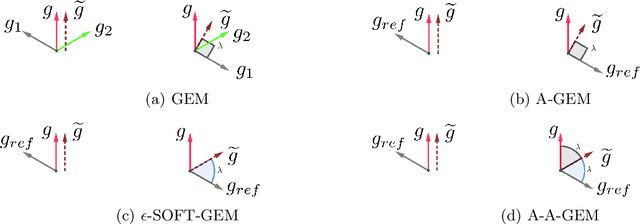

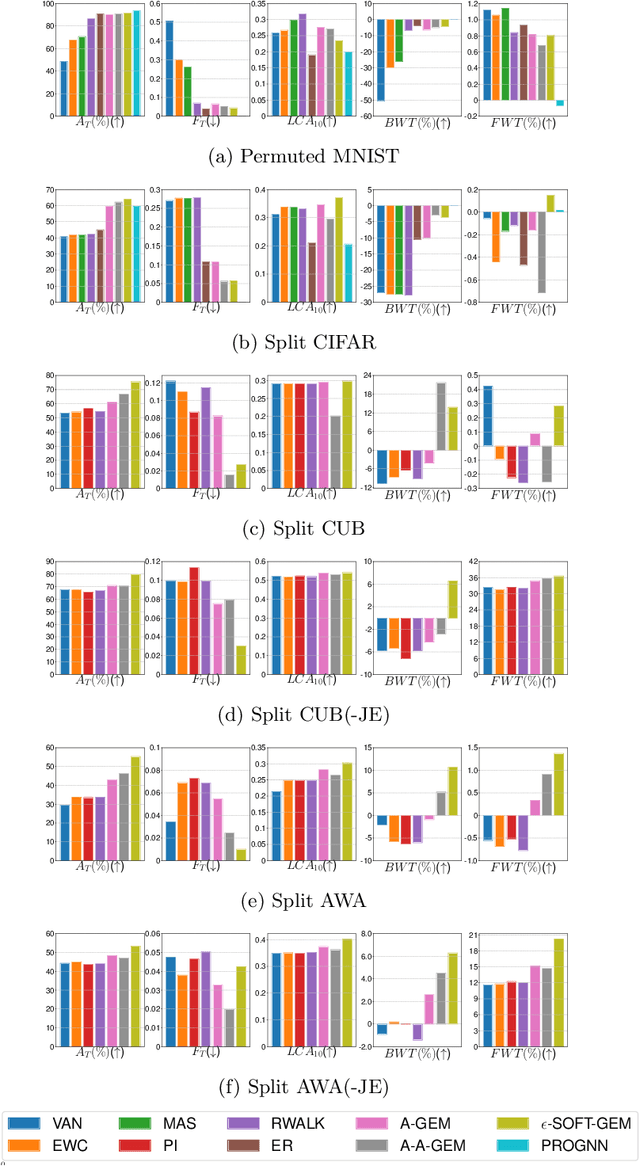

Catastrophic forgetting in continual learning is a common destructive phenomenon in gradient-based neural networks that learn sequential tasks, and it is much different from forgetting in humans, who can learn and accumulate knowledge throughout their whole lives. Catastrophic forgetting is the fatal shortcoming of a large decrease in performance on previous tasks when the model is learning a novel task. To alleviate this problem, the model should have the capacity to learn new knowledge and preserve learned knowledge. We propose an average gradient episodic memory (A-GEM) with a soft constraint $\epsilon \in [0, 1]$, which is a balance factor between learning new knowledge and preserving learned knowledge; our method is called gradient episodic memory with a soft constraint $\epsilon$ ($\epsilon$-SOFT-GEM). $\epsilon$-SOFT-GEM outperforms A-GEM and several continual learning benchmarks in a single training epoch; additionally, it has state-of-the-art average accuracy and efficiency for computation and memory, like A-GEM, and provides a better trade-off between the stability of preserving learned knowledge and the plasticity of learning new knowledge.