 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEGIS: Exploring the Limit of World Knowledge Capabilities for Unified Mulitmodal Models
Jan 02, 2026The capability of Unified Multimodal Models (UMMs) to apply world knowledge across diverse tasks remains a critical, unresolved challenge. Existing benchmarks fall short, offering only siloed, single-task evaluations with limited diagnostic power. To bridge this gap, we propose AEGIS (\emph{i.e.}, \textbf{A}ssessing \textbf{E}diting, \textbf{G}eneration, \textbf{I}nterpretation-Understanding for \textbf{S}uper-intelligence), a comprehensive multi-task benchmark covering visual understanding, generation, editing, and interleaved generation. AEGIS comprises 1,050 challenging, manually-annotated questions spanning 21 topics (including STEM, humanities, daily life, etc.) and 6 reasoning types. To concretely evaluate the performance of UMMs in world knowledge scope without ambiguous metrics, we further propose Deterministic Checklist-based Evaluation (DCE), a protocol that replaces ambiguous prompt-based scoring with atomic ``Y/N'' judgments, to enhance evaluation reliability. Our extensive experiments reveal that most UMMs exhibit severe world knowledge deficits and that performance degrades significantly with complex reasoning. Additionally, simple plug-in reasoning modules can partially mitigate these vulnerabilities, highlighting a promising direction for future research. These results highlight the importance of world-knowledge-based reasoning as a critical frontier for UMMs.
VisionDirector: Vision-Language Guided Closed-Loop Refinement for Generative Image Synthesis
Dec 22, 2025Generative models can now produce photorealistic imagery, yet they still struggle with the long, multi-goal prompts that professional designers issue. To expose this gap and better evaluate models' performance in real-world settings, we introduce Long Goal Bench (LGBench), a 2,000-task suite (1,000 T2I and 1,000 I2I) whose average instruction contains 18 to 22 tightly coupled goals spanning global layout, local object placement, typography, and logo fidelity. We find that even state-of-the-art models satisfy fewer than 72 percent of the goals and routinely miss localized edits, confirming the brittleness of current pipelines. To address this, we present VisionDirector, a training-free vision-language supervisor that (i) extracts structured goals from long instructions, (ii) dynamically decides between one-shot generation and staged edits, (iii) runs micro-grid sampling with semantic verification and rollback after every edit, and (iv) logs goal-level rewards. We further fine-tune the planner with Group Relative Policy Optimization, yielding shorter edit trajectories (3.1 versus 4.2 steps) and stronger alignment. VisionDirector achieves new state of the art on GenEval (plus 7 percent overall) and ImgEdit (plus 0.07 absolute) while producing consistent qualitative improvements on typography, multi-object scenes, and pose editing.
MMMamba: A Versatile Cross-Modal In Context Fusion Framework for Pan-Sharpening and Zero-Shot Image Enhancement
Dec 17, 2025Pan-sharpening aims to generate high-resolution multispectral (HRMS) images by integrating a high-resolution panchromatic (PAN) image with its corresponding low-resolution multispectral (MS) image. To achieve effective fusion, it is crucial to fully exploit the complementary information between the two modalities. Traditional CNN-based methods typically rely on channel-wise concatenation with fixed convolutional operators, which limits their adaptability to diverse spatial and spectral variations. While cross-attention mechanisms enable global interactions, they are computationally inefficient and may dilute fine-grained correspondences, making it difficult to capture complex semantic relationships. Recent advances in the Multimodal Diffusion Transformer (MMDiT) architecture have demonstrated impressive success in image generation and editing tasks. Unlike cross-attention, MMDiT employs in-context conditioning to facilitate more direct and efficient cross-modal information exchange. In this paper, we propose MMMamba, a cross-modal in-context fusion framework for pan-sharpening, with the flexibility to support image super-resolution in a zero-shot manner. Built upon the Mamba architecture, our design ensures linear computational complexity while maintaining strong cross-modal interaction capacity. Furthermore, we introduce a novel multimodal interleaved (MI) scanning mechanism that facilitates effective information exchange between the PAN and MS modalities. Extensive experiments demonstrate the superior performance of our method compared to existing state-of-the-art (SOTA) techniques across multiple tasks and benchmarks.
Efficient Reasoning via Reward Model
Nov 12, 2025Reinforcement learning with verifiable rewards (RLVR) has been shown to enhance the reasoning capabilities of large language models (LLMs), enabling the development of large reasoning models (LRMs). However, LRMs such as DeepSeek-R1 and OpenAI o1 often generate verbose responses containing redundant or irrelevant reasoning step-a phenomenon known as overthinking-which substantially increases computational costs. Prior efforts to mitigate this issue commonly incorporate length penalties into the reward function, but we find they frequently suffer from two critical issues: length collapse and training collapse, resulting in sub-optimal performance. To address them, we propose a pipeline for training a Conciseness Reward Model (CRM) that scores the conciseness of reasoning path. Additionally, we introduce a novel reward formulation named Conciseness Reward Function (CRF) with explicit dependency between the outcome reward and conciseness score, thereby fostering both more effective and more efficient reasoning. From a theoretical standpoint, we demonstrate the superiority of the new reward from the perspective of variance reduction and improved convergence properties. Besides, on the practical side, extensive experiments on five mathematical benchmark datasets demonstrate the method's effectiveness and token efficiency, which achieves an 8.1% accuracy improvement and a 19.9% reduction in response token length on Qwen2.5-7B. Furthermore, the method generalizes well to other LLMs including Llama and Mistral. The implementation code and datasets are publicly available for reproduction: https://anonymous.4open.science/r/CRM.
Disentangling Instruction Influence in Diffusion Transformers for Parallel Multi-Instruction-Guided Image Editing
Apr 07, 2025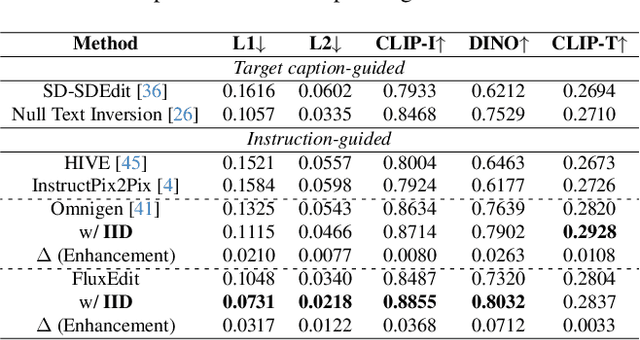
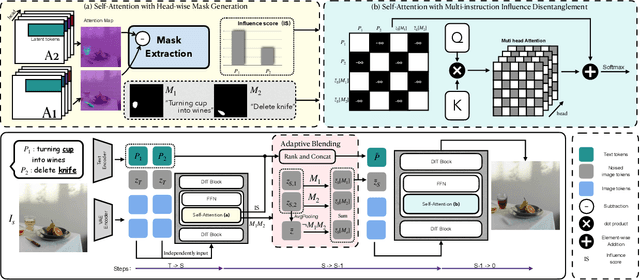
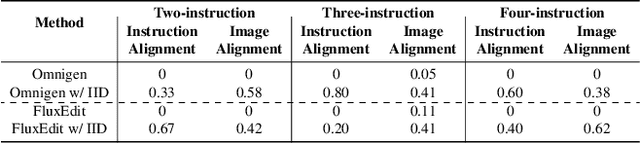

Instruction-guided image editing enables users to specify modifications using natural language, offering more flexibility and control. Among existing frameworks, Diffusion Transformers (DiTs) outperform U-Net-based diffusion models in scalability and performance. However, while real-world scenarios often require concurrent execution of multiple instructions, step-by-step editing suffers from accumulated errors and degraded quality, and integrating multiple instructions with a single prompt usually results in incomplete edits due to instruction conflicts. We propose Instruction Influence Disentanglement (IID), a novel framework enabling parallel execution of multiple instructions in a single denoising process, designed for DiT-based models. By analyzing self-attention mechanisms in DiTs, we identify distinctive attention patterns in multi-instruction settings and derive instruction-specific attention masks to disentangle each instruction's influence. These masks guide the editing process to ensure localized modifications while preserving consistency in non-edited regions. Extensive experiments on open-source and custom datasets demonstrate that IID reduces diffusion steps while improving fidelity and instruction completion compared to existing baselines. The codes will be publicly released upon the acceptance of the paper.