 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving In-context Learning via Bidirectional Alignment
Paper and Code
Dec 28, 2023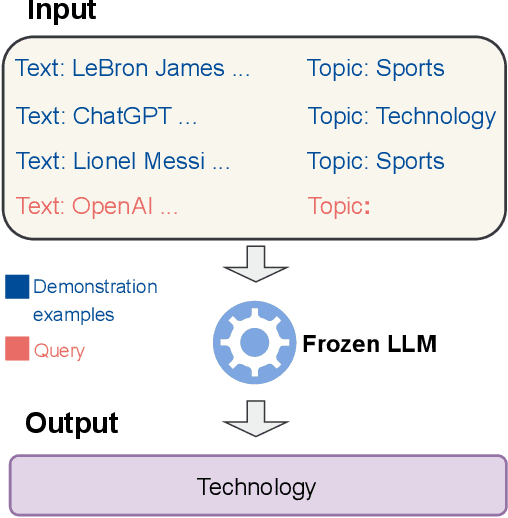

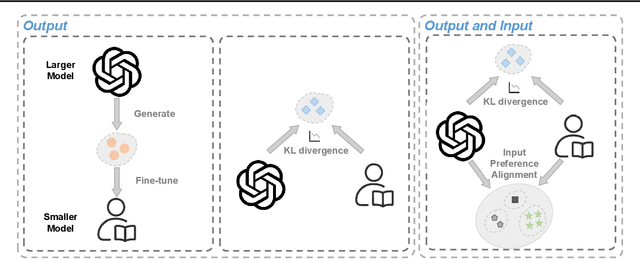
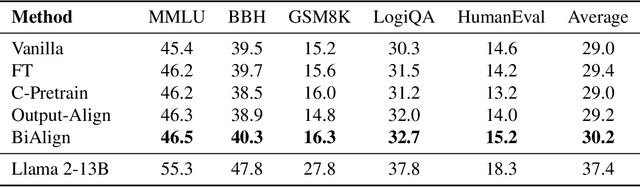
Large language models (LLMs) have shown impressive few-shot generalization on many tasks via in-context learning (ICL). Despite their success in showing such emergent abilities, the scale and complexity of larger models also lead to unprecedentedly high computational demands and deployment challenges. In reaction, researchers explore transferring the powerful capabilities of larger models to more efficient and compact models by typically aligning the output of smaller models with that of larger models. Existing methods either train smaller models on the generated outputs of larger models or to imitate their token-level probability distributions. However, these distillation methods pay little to no attention to the input part, which also plays a crucial role in ICL. Based on the finding that the performance of ICL is highly sensitive to the selection of demonstration examples, we propose Bidirectional Alignment (BiAlign) to fully leverage the models' preferences for ICL examples to improve the ICL abilities of smaller models. Specifically, we introduce the alignment of input preferences between smaller and larger models by incorporating a novel ranking loss, in addition to aligning the token-level output distribution. With extensive experiments and analysis, we demonstrate that BiAlign can consistently outperform existing baselines on a variety of tasks including language understanding, reasoning, and coding.