 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQC-StyleGAN -- Quality Controllable Image Generation and Manipulation
Dec 07, 2022



The introduction of high-quality image generation models, particularly the StyleGAN family, provides a powerful tool to synthesize and manipulate images. However, existing models are built upon high-quality (HQ) data as desired outputs, making them unfit for in-the-wild low-quality (LQ) images, which are common inputs for manipulation. In this work, we bridge this gap by proposing a novel GAN structure that allows for generating images with controllable quality. The network can synthesize various image degradation and restore the sharp image via a quality control code. Our proposed QC-StyleGAN can directly edit LQ images without altering their quality by applying GAN inversion and manipulation techniques. It also provides for free an image restoration solution that can handle various degradations, including noise, blur, compression artifacts, and their mixtures. Finally, we demonstrate numerous other applications such as image degradation synthesis, transfer, and interpolation. The code is available at https://github.com/VinAIResearch/QC-StyleGAN.
TISE: A Toolbox for Text-to-Image Synthesis Evaluation
Dec 02, 2021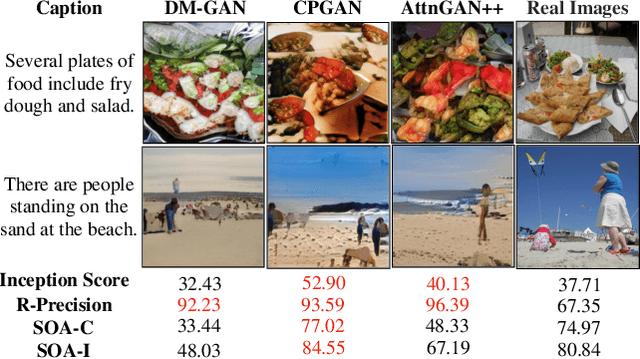
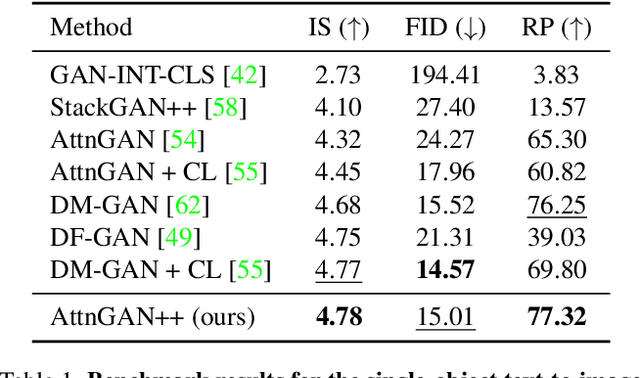

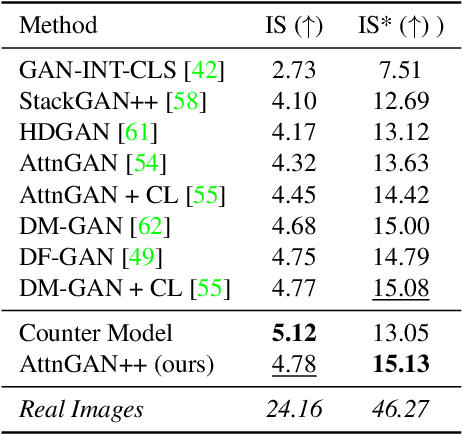
In this paper, we conduct a study on state-of-the-art methods for single- and multi-object text-to-image synthesis and propose a common framework for evaluating these methods. We first identify several common issues in the current evaluation of text-to-image models, which are: (i) a commonly used metric for image quality assessment, e.g., Inception Score (IS), is often either miscalibrated for the single-object case or misused for the multi-object case; (ii) the overfitting phenomenon appears in the existing R-precision (RP) and SOA metrics, which are used to assess text relevance and object accuracy aspects, respectively; (iii) many vital factors in the evaluation of the multi-object case are primarily dismissed, e.g., object fidelity, positional alignment, counting alignment; (iv) the ranking of the methods based on current metrics is highly inconsistent with real images. Then, to overcome these limitations, we propose a combined set of existing and new metrics to systematically evaluate the methods. For existing metrics, we develop an improved version of IS named IS* by using temperature scaling to calibrate the confidence of the classifier used by IS; we also propose a solution to mitigate the overfitting issues of RP and SOA. Regarding a set of new metrics compensating for the lacking of vital evaluating factors in the multi-object case, we develop CA for counting alignment, PA for positional alignment, object-centric IS (O-IS), object-centric FID (O-FID) for object fidelity. Our benchmark, therefore, results in a highly consistent ranking among existing methods, being well-aligned to human evaluation. We also create a strong baseline model (AttnGAN++) for the benchmark by a simple modification from the well-known AttnGAN. We will release this toolbox for unified evaluation, so-called TISE, to standardize the evaluation of the text-to-image synthesis models.
HyperInverter: Improving StyleGAN Inversion via Hypernetwork
Dec 01, 2021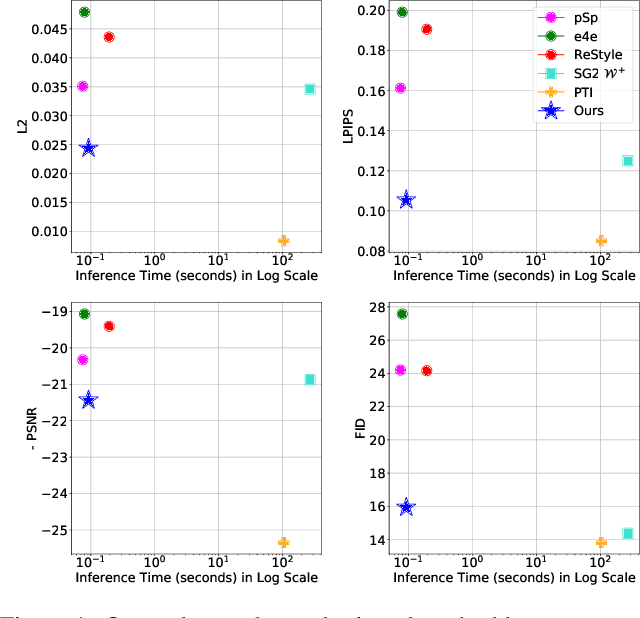
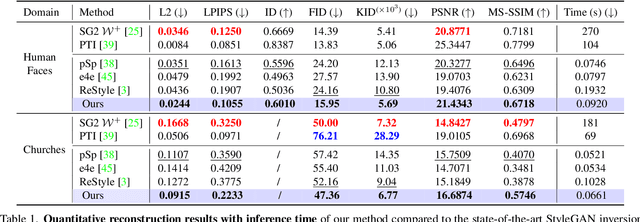
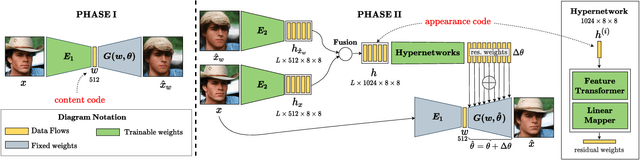
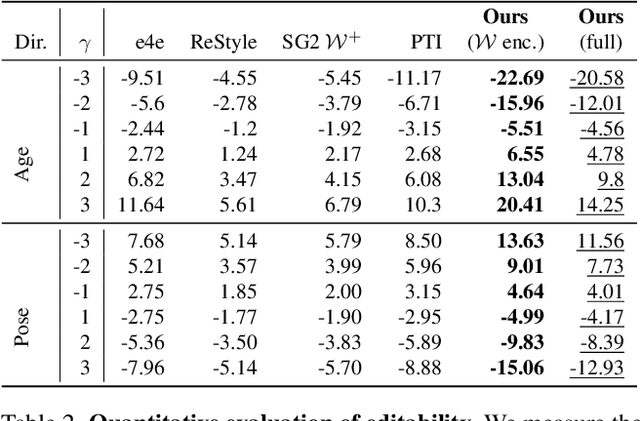
Real-world image manipulation has achieved fantastic progress in recent years as a result of the exploration and utilization of GAN latent spaces. GAN inversion is the first step in this pipeline, which aims to map the real image to the latent code faithfully. Unfortunately, the majority of existing GAN inversion methods fail to meet at least one of the three requirements listed below: high reconstruction quality, editability, and fast inference. We present a novel two-phase strategy in this research that fits all requirements at the same time. In the first phase, we train an encoder to map the input image to StyleGAN2 $\mathcal{W}$-space, which was proven to have excellent editability but lower reconstruction quality. In the second phase, we supplement the reconstruction ability in the initial phase by leveraging a series of hypernetworks to recover the missing information during inversion. These two steps complement each other to yield high reconstruction quality thanks to the hypernetwork branch and excellent editability due to the inversion done in the $\mathcal{W}$-space. Our method is entirely encoder-based, resulting in extremely fast inference. Extensive experiments on two challenging datasets demonstrate the superiority of our method.