 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTISE: A Toolbox for Text-to-Image Synthesis Evaluation
Paper and Code
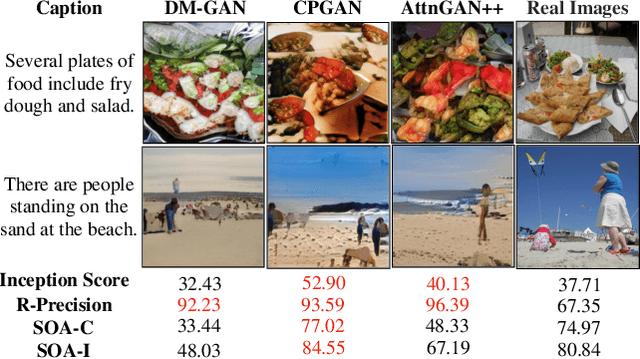
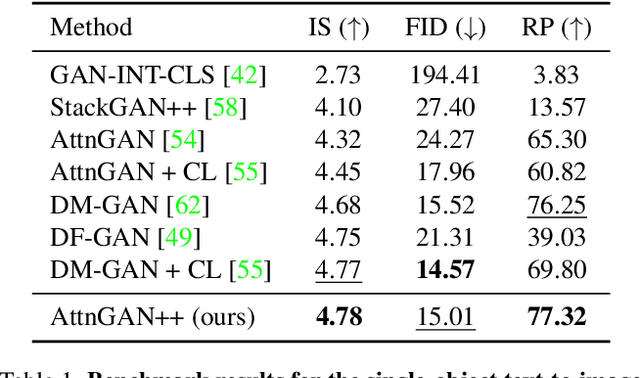

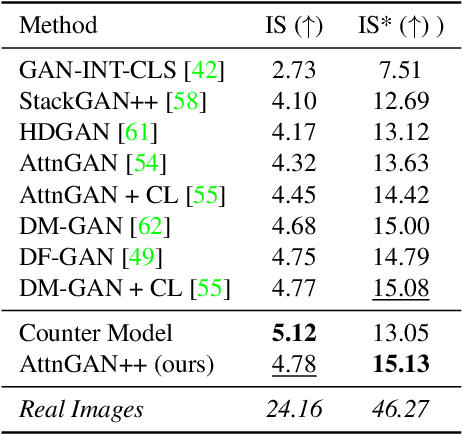
In this paper, we conduct a study on state-of-the-art methods for single- and multi-object text-to-image synthesis and propose a common framework for evaluating these methods. We first identify several common issues in the current evaluation of text-to-image models, which are: (i) a commonly used metric for image quality assessment, e.g., Inception Score (IS), is often either miscalibrated for the single-object case or misused for the multi-object case; (ii) the overfitting phenomenon appears in the existing R-precision (RP) and SOA metrics, which are used to assess text relevance and object accuracy aspects, respectively; (iii) many vital factors in the evaluation of the multi-object case are primarily dismissed, e.g., object fidelity, positional alignment, counting alignment; (iv) the ranking of the methods based on current metrics is highly inconsistent with real images. Then, to overcome these limitations, we propose a combined set of existing and new metrics to systematically evaluate the methods. For existing metrics, we develop an improved version of IS named IS* by using temperature scaling to calibrate the confidence of the classifier used by IS; we also propose a solution to mitigate the overfitting issues of RP and SOA. Regarding a set of new metrics compensating for the lacking of vital evaluating factors in the multi-object case, we develop CA for counting alignment, PA for positional alignment, object-centric IS (O-IS), object-centric FID (O-FID) for object fidelity. Our benchmark, therefore, results in a highly consistent ranking among existing methods, being well-aligned to human evaluation. We also create a strong baseline model (AttnGAN++) for the benchmark by a simple modification from the well-known AttnGAN. We will release this toolbox for unified evaluation, so-called TISE, to standardize the evaluation of the text-to-image synthesis models.