 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Exploration in Actor-Critic Algorithms by Incentivizing Plausible Novel States
Oct 01, 2022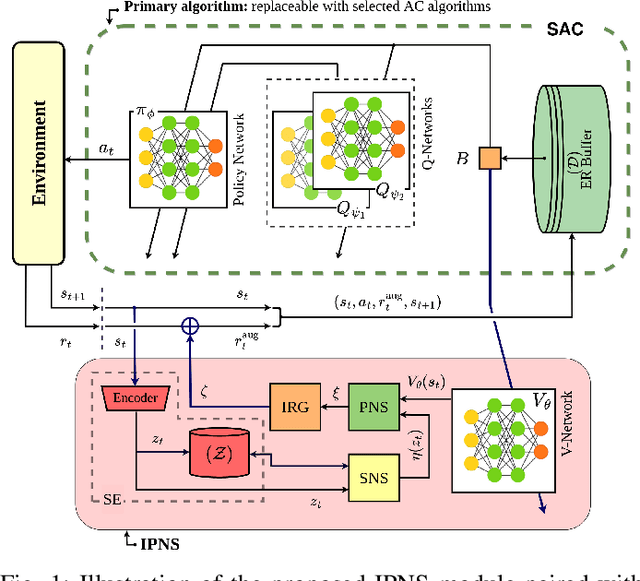
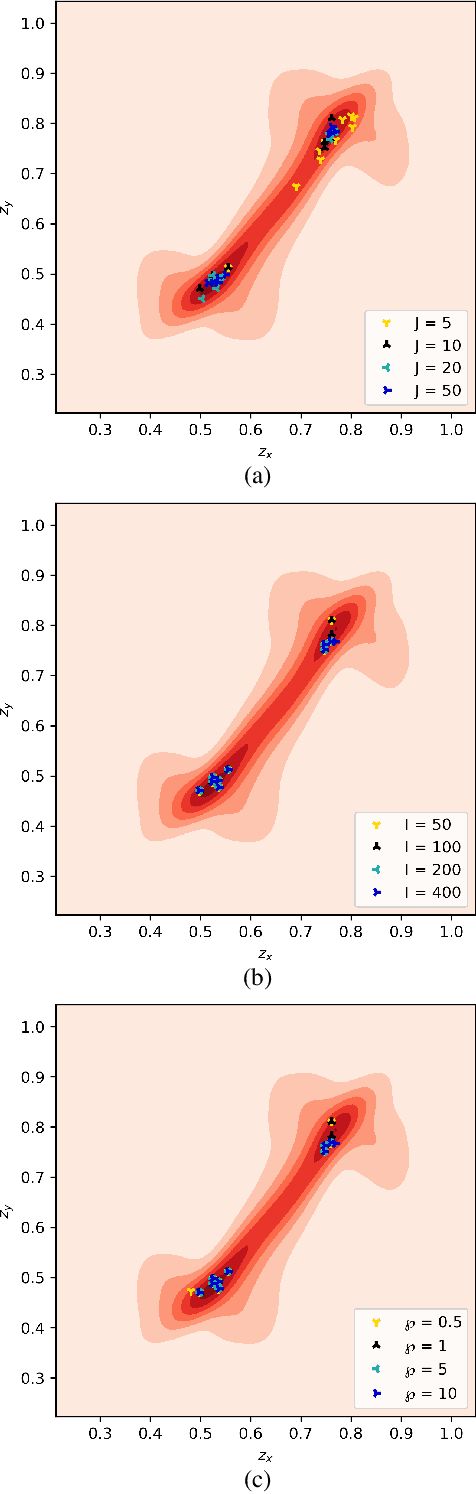
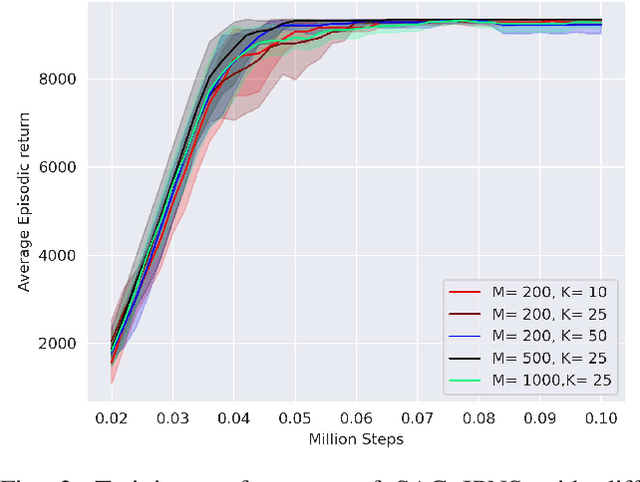
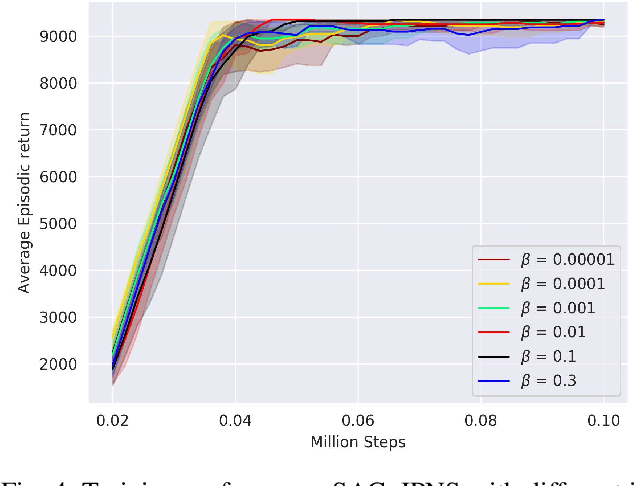
Actor-critic (AC) algorithms are a class of model-free deep reinforcement learning algorithms, which have proven their efficacy in diverse domains, especially in solving continuous control problems. Improvement of exploration (action entropy) and exploitation (expected return) using more efficient samples is a critical issue in AC algorithms. A basic strategy of a learning algorithm is to facilitate indiscriminately exploring all of the environment state space, as well as to encourage exploring rarely visited states rather than frequently visited one. Under this strategy, we propose a new method to boost exploration through an intrinsic reward, based on measurement of a state's novelty and the associated benefit of exploring the state (with regards to policy optimization), altogether called plausible novelty. With incentivized exploration of plausible novel states, an AC algorithm is able to improve its sample efficiency and hence training performance. The new method is verified by extensive simulations of continuous control tasks of MuJoCo environments on a variety of prominent off-policy AC algorithms.
Improved Soft Actor-Critic: Mixing Prioritized Off-Policy Samples with On-Policy Experience
Sep 24, 2021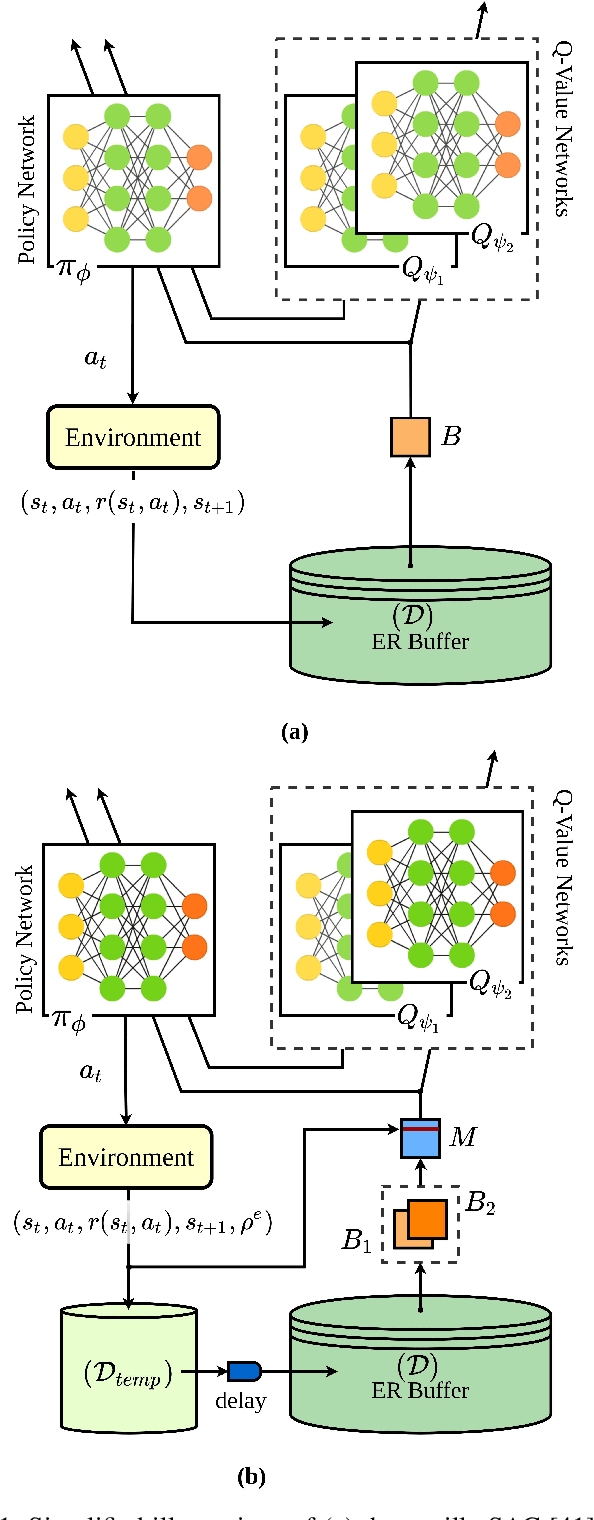
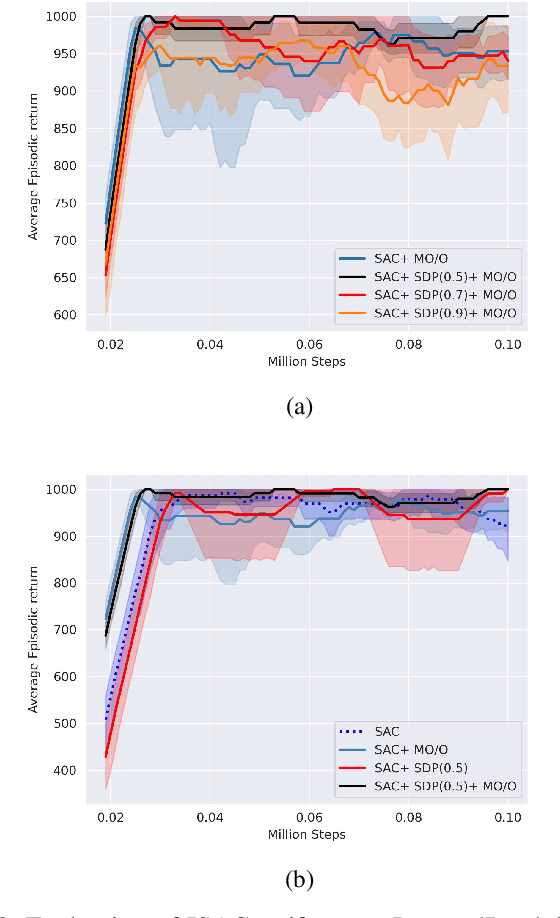
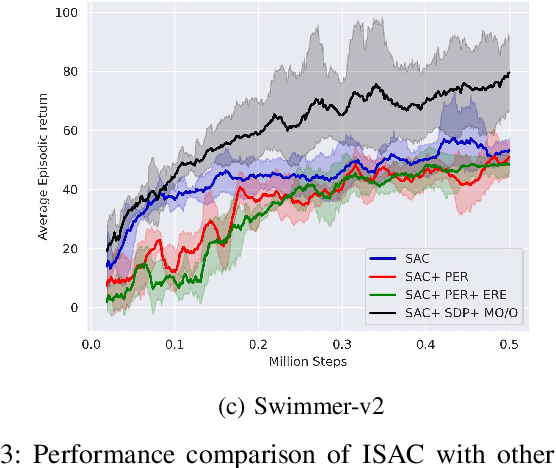
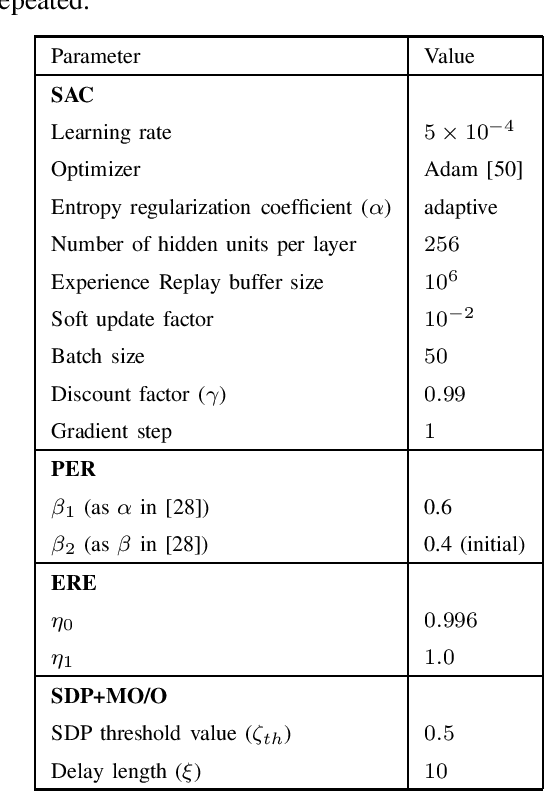
Soft Actor-Critic (SAC) is an off-policy actor-critic reinforcement learning algorithm, essentially based on entropy regularization. SAC trains a policy by maximizing the trade-off between expected return and entropy (randomness in the policy). It has achieved state-of-the-art performance on a range of continuous-control benchmark tasks, outperforming prior on-policy and off-policy methods. SAC works in an off-policy fashion where data are sampled uniformly from past experiences (stored in a buffer) using which parameters of the policy and value function networks are updated. We propose certain crucial modifications for boosting the performance of SAC and make it more sample efficient. In our proposed improved SAC, we firstly introduce a new prioritization scheme for selecting better samples from the experience replay buffer. Secondly we use a mixture of the prioritized off-policy data with the latest on-policy data for training the policy and the value function networks. We compare our approach with the vanilla SAC and some recent variants of SAC and show that our approach outperforms the said algorithmic benchmarks. It is comparatively more stable and sample efficient when tested on a number of continuous control tasks in MuJoCo environments.
Optimal Actor-Critic Policy with Optimized Training Datasets
Aug 16, 2021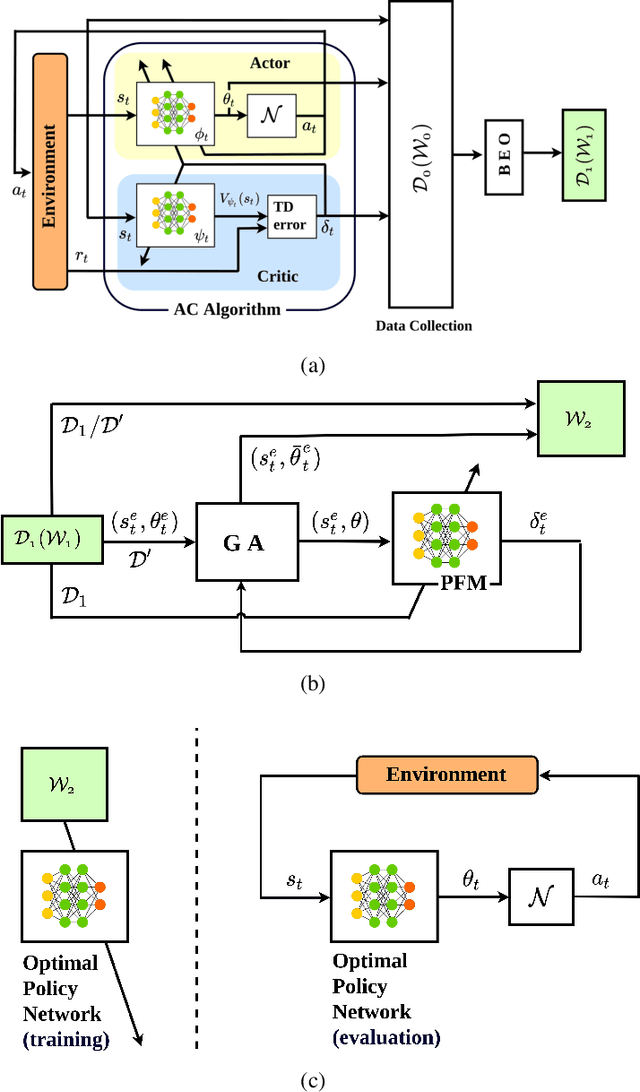

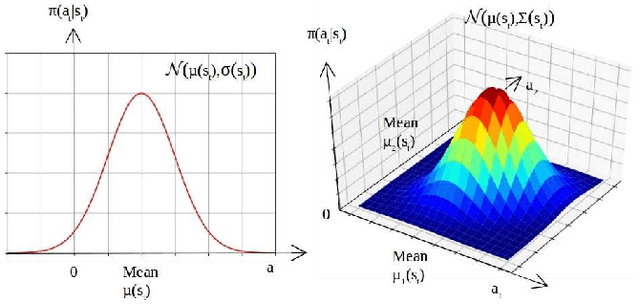
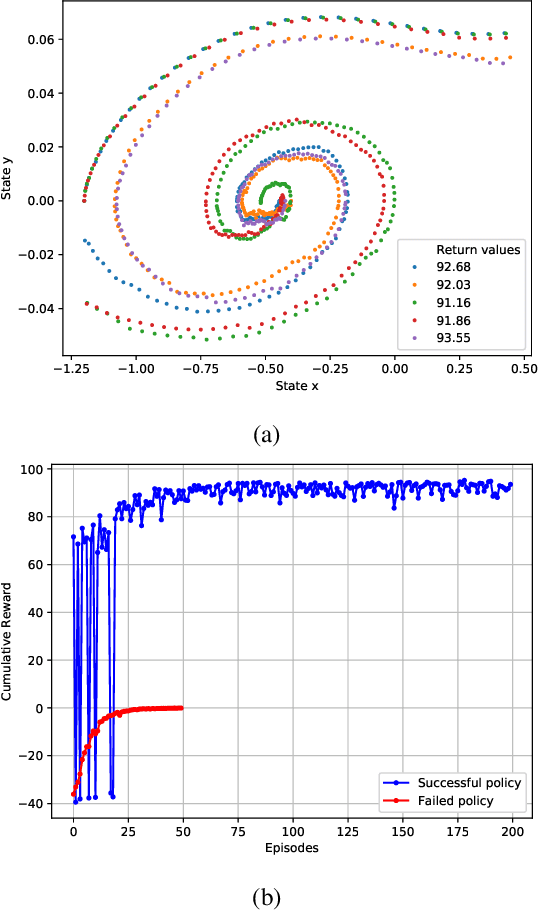
Actor-critic (AC) algorithms are known for their efficacy and high performance in solving reinforcement learning problems, but they also suffer from low sampling efficiency. An AC based policy optimization process is iterative and needs to frequently access the agent-environment system to evaluate and update the policy by rolling out the policy, collecting rewards and states (i.e. samples), and learning from them. It ultimately requires a huge number of samples to learn an optimal policy. To improve sampling efficiency, we propose a strategy to optimize the training dataset that contains significantly less samples collected from the AC process. The dataset optimization is made of a best episode only operation, a policy parameter-fitness model, and a genetic algorithm module. The optimal policy network trained by the optimized training dataset exhibits superior performance compared to many contemporary AC algorithms in controlling autonomous dynamical systems. Evaluation on standard benchmarks show that the method improves sampling efficiency, ensures faster convergence to optima, and is more data-efficient than its counterparts.