 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Soft Actor-Critic: Mixing Prioritized Off-Policy Samples with On-Policy Experience
Paper and Code
Sep 24, 2021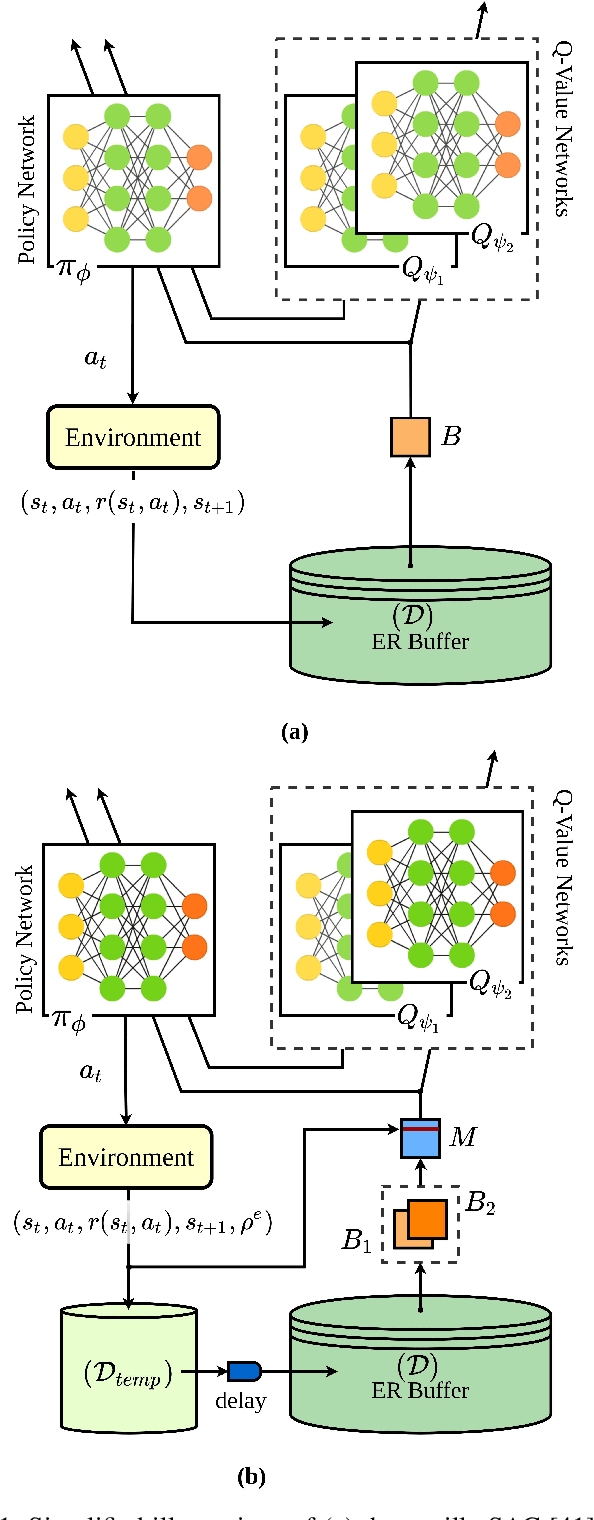
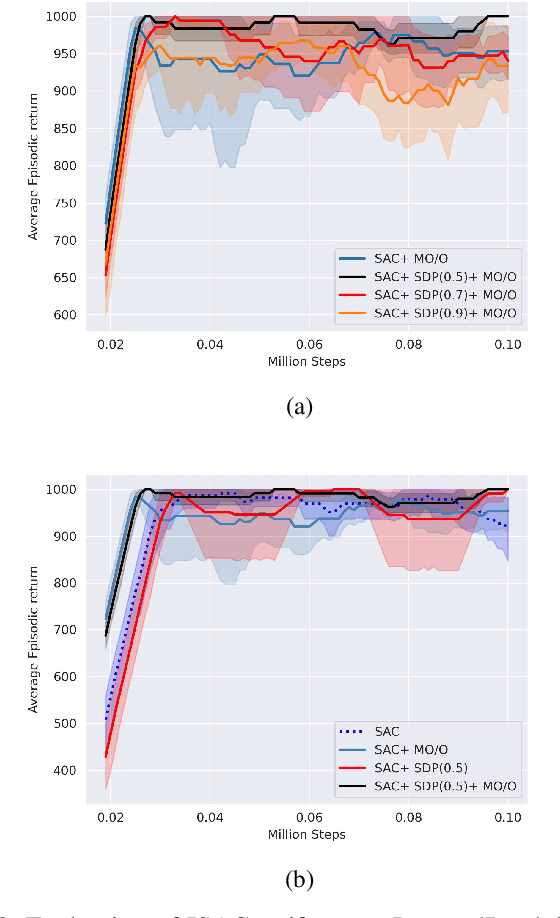
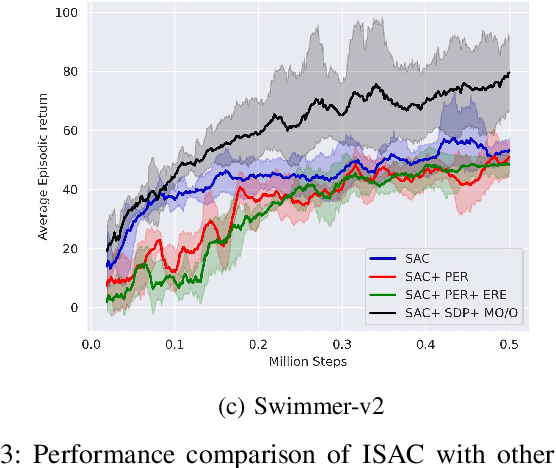
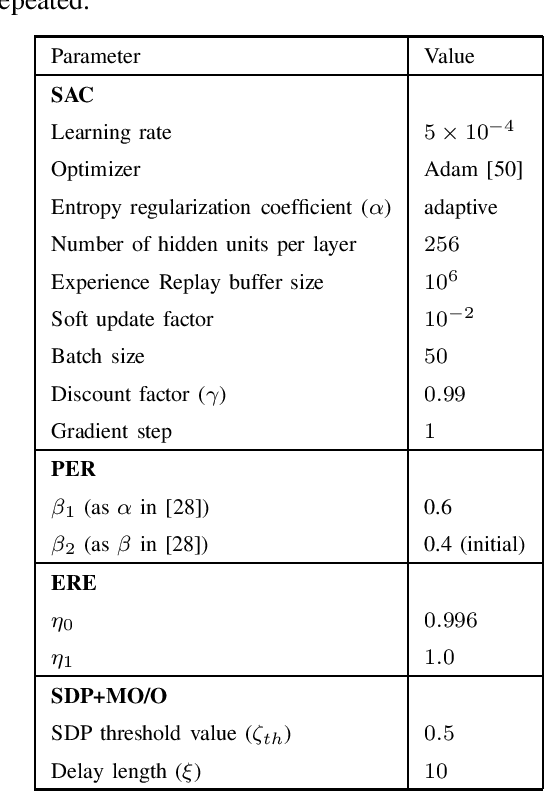
Soft Actor-Critic (SAC) is an off-policy actor-critic reinforcement learning algorithm, essentially based on entropy regularization. SAC trains a policy by maximizing the trade-off between expected return and entropy (randomness in the policy). It has achieved state-of-the-art performance on a range of continuous-control benchmark tasks, outperforming prior on-policy and off-policy methods. SAC works in an off-policy fashion where data are sampled uniformly from past experiences (stored in a buffer) using which parameters of the policy and value function networks are updated. We propose certain crucial modifications for boosting the performance of SAC and make it more sample efficient. In our proposed improved SAC, we firstly introduce a new prioritization scheme for selecting better samples from the experience replay buffer. Secondly we use a mixture of the prioritized off-policy data with the latest on-policy data for training the policy and the value function networks. We compare our approach with the vanilla SAC and some recent variants of SAC and show that our approach outperforms the said algorithmic benchmarks. It is comparatively more stable and sample efficient when tested on a number of continuous control tasks in MuJoCo environments.