 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalising In Complex Scenes Using Balanced Adversarial Adaptation
Paper and Code
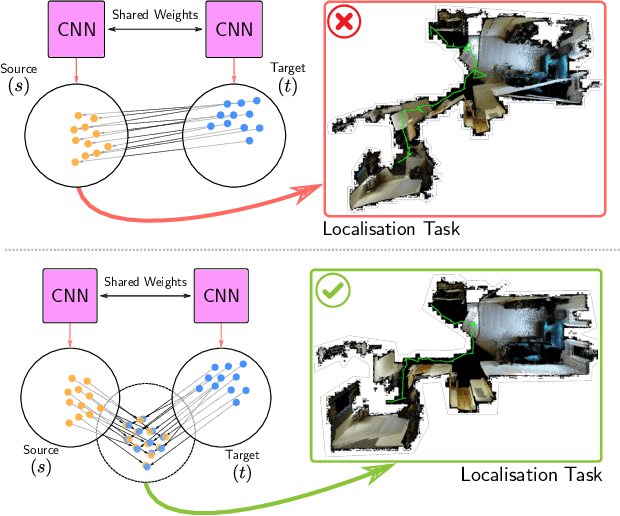
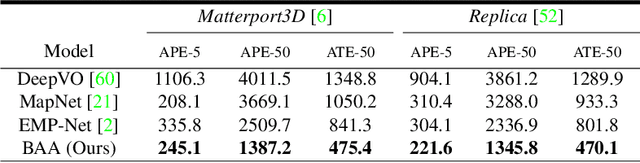
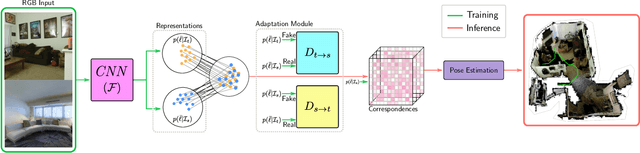
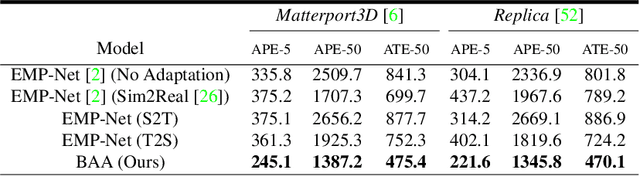
Domain adaptation and generative modelling have collectively mitigated the expensive nature of data collection and labelling by leveraging the rich abundance of accurate, labelled data in simulation environments. In this work, we study the performance gap that exists between representations optimised for localisation on simulation environments and the application of such representations in a real-world setting. Our method exploits the shared geometric similarities between simulation and real-world environments whilst maintaining invariance towards visual discrepancies. This is achieved by optimising a representation extractor to project both simulated and real representations into a shared representation space. Our method uses a symmetrical adversarial approach which encourages the representation extractor to conceal the domain that features are extracted from and simultaneously preserves robust attributes between source and target domains that are beneficial for localisation. We evaluate our method by adapting representations optimised for indoor Habitat simulated environments (Matterport3D and Replica) to a real-world indoor environment (Active Vision Dataset), showing that it compares favourably against fully-supervised approaches.