 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputer-aided Tumor Diagnosis in Automated Breast Ultrasound using 3D Detection Network
Jul 31, 2020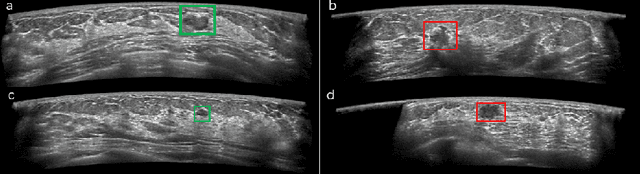
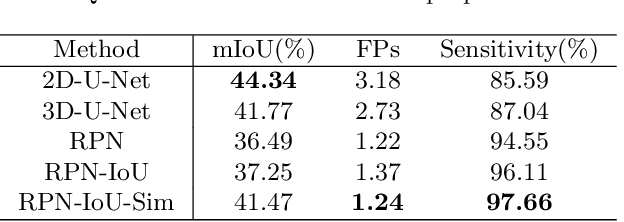
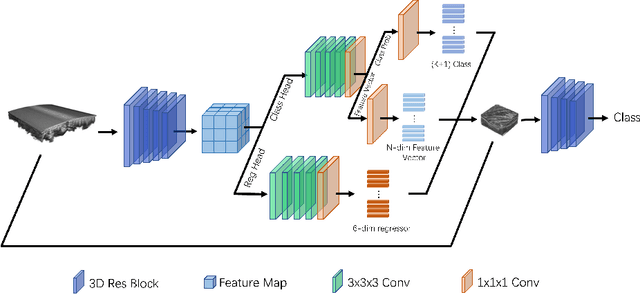
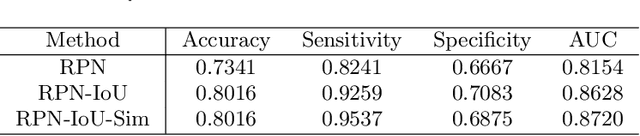
Automated breast ultrasound (ABUS) is a new and promising imaging modality for breast cancer detection and diagnosis, which could provide intuitive 3D information and coronal plane information with great diagnostic value. However, manually screening and diagnosing tumors from ABUS images is very time-consuming and overlooks of abnormalities may happen. In this study, we propose a novel two-stage 3D detection network for locating suspected lesion areas and further classifying lesions as benign or malignant tumors. Specifically, we propose a 3D detection network rather than frequently-used segmentation network to locate lesions in ABUS images, thus our network can make full use of the spatial context information in ABUS images. A novel similarity loss is designed to effectively distinguish lesions from background. Then a classification network is employed to identify the located lesions as benign or malignant. An IoU-balanced classification loss is adopted to improve the correlation between classification and localization task. The efficacy of our network is verified from a collected dataset of 418 patients with 145 benign tumors and 273 malignant tumors. Experiments show our network attains a sensitivity of 97.66% with 1.23 false positives (FPs), and has an area under the curve(AUC) value of 0.8720.
Feedback Graph Convolutional Network for Skeleton-based Action Recognition
Mar 17, 2020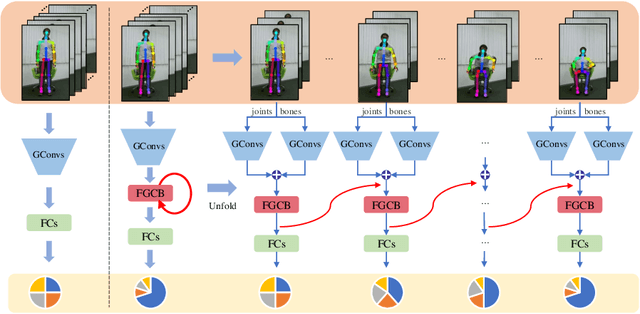



Skeleton-based action recognition has attracted considerable attention in computer vision since skeleton data is more robust to the dynamic circumstance and complicated background than other modalities. Recently, many researchers have used the Graph Convolutional Network (GCN) to model spatial-temporal features of skeleton sequences by an end-to-end optimization. However, conventional GCNs are feedforward networks which are impossible for low-level layers to access semantic information in the high-level layers. In this paper, we propose a novel network, named Feedback Graph Convolutional Network (FGCN). This is the first work that introduces the feedback mechanism into GCNs and action recognition. Compared with conventional GCNs, FGCN has the following advantages: (1) a multi-stage temporal sampling strategy is designed to extract spatial-temporal features for action recognition in a coarse-to-fine progressive process; (2) A dense connections based Feedback Graph Convolutional Block (FGCB) is proposed to introduce feedback connections into the GCNs. It transmits the high-level semantic features to the low-level layers and flows temporal information stage by stage to progressively model global spatial-temporal features for action recognition; (3) The FGCN model provides early predictions. In the early stages, the model receives partial information about actions. Naturally, its predictions are relatively coarse. The coarse predictions are treated as the prior to guide the feature learning of later stages for a accurate prediction. Extensive experiments on the datasets, NTU-RGB+D, NTU-RGB+D120 and Northwestern-UCLA, demonstrate that the proposed FGCN is effective for action recognition. It achieves the state-of-the-art performance on the three datasets.