 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring Image Matting
Paper and Code



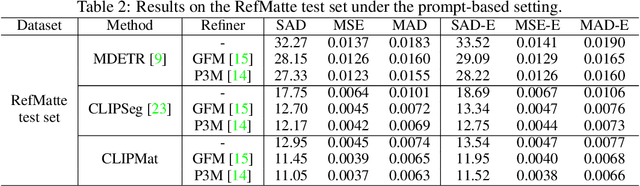
Image matting refers to extracting the accurate foregrounds in the image. Current automatic methods tend to extract all the salient objects in the image indiscriminately. In this paper, we propose a new task named Referring Image Matting (RIM), referring to extracting the meticulous alpha matte of the specific object that can best match the given natural language description. However, prevalent visual grounding methods are all limited to the segmentation level, probably due to the lack of high-quality datasets for RIM. To fill the gap, we establish the first large-scale challenging dataset RefMatte by designing a comprehensive image composition and expression generation engine to produce synthetic images on top of current public high-quality matting foregrounds with flexible logics and re-labelled diverse attributes. RefMatte consists of 230 object categories, 47,500 images, 118,749 expression-region entities, and 474,996 expressions, which can be further extended easily in the future. Besides this, we also construct a real-world test set with manually generated phrase annotations consisting of 100 natural images to further evaluate the generalization of RIM models. We first define the task of RIM in two settings, i.e., prompt-based and expression-based, and then benchmark several representative methods together with specific model designs for image matting. The results provide empirical insights into the limitations of existing methods as well as possible solutions. We believe the new task RIM along with the RefMatte dataset will open new research directions in this area and facilitate future studies. The dataset and code will be made publicly available at https://github.com/JizhiziLi/RIM.