 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEIT: Efficiently Lead Inductive Biases to ViT
Paper and Code
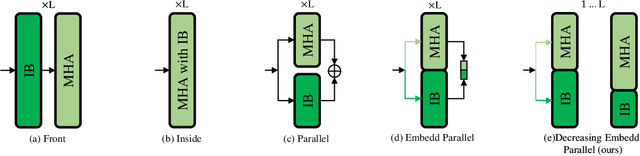
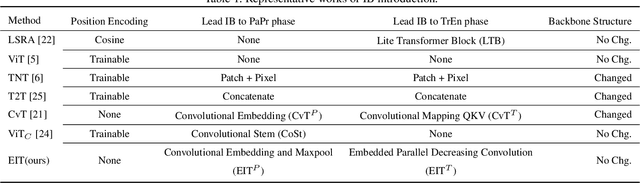
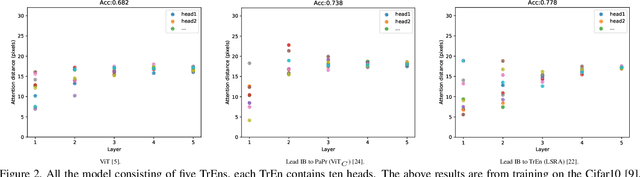

Vision Transformer (ViT) depends on properties similar to the inductive bias inherent in Convolutional Neural Networks to perform better on non-ultra-large scale datasets. In this paper, we propose an architecture called Efficiently lead Inductive biases to ViT (EIT), which can effectively lead the inductive biases to both phases of ViT. In the Patches Projection phase, a convolutional max-pooling structure is used to produce overlapping patches. In the Transformer Encoder phase, we design a novel inductive bias introduction structure called decreasing convolution, which is introduced parallel to the multi-headed attention module, by which the embedding's different channels are processed respectively. In four popular small-scale datasets, compared with ViT, EIT has an accuracy improvement of 12.6% on average with fewer parameters and FLOPs. Compared with ResNet, EIT exhibits higher accuracy with only 17.7% parameters and fewer FLOPs. Finally, ablation studies show that the EIT is efficient and does not require position embedding. Code is coming soon: https://github.com/MrHaiPi/EIT