 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVI-Net: Boosting Category-level 6D Object Pose Estimation via Learning Decoupled Rotations on the Spherical Representations
Aug 19, 2023



Rotation estimation of high precision from an RGB-D object observation is a huge challenge in 6D object pose estimation, due to the difficulty of learning in the non-linear space of SO(3). In this paper, we propose a novel rotation estimation network, termed as VI-Net, to make the task easier by decoupling the rotation as the combination of a viewpoint rotation and an in-plane rotation. More specifically, VI-Net bases the feature learning on the sphere with two individual branches for the estimates of two factorized rotations, where a V-Branch is employed to learn the viewpoint rotation via binary classification on the spherical signals, while another I-Branch is used to estimate the in-plane rotation by transforming the signals to view from the zenith direction. To process the spherical signals, a Spherical Feature Pyramid Network is constructed based on a novel design of SPAtial Spherical Convolution (SPA-SConv), which settles the boundary problem of spherical signals via feature padding and realizesviewpoint-equivariant feature extraction by symmetric convolutional operations. We apply the proposed VI-Net to the challenging task of category-level 6D object pose estimation for predicting the poses of unknown objects without available CAD models; experiments on the benchmarking datasets confirm the efficacy of our method, which outperforms the existing ones with a large margin in the regime of high precision.
Category-Level 6D Object Pose and Size Estimation using Self-Supervised Deep Prior Deformation Networks
Jul 12, 2022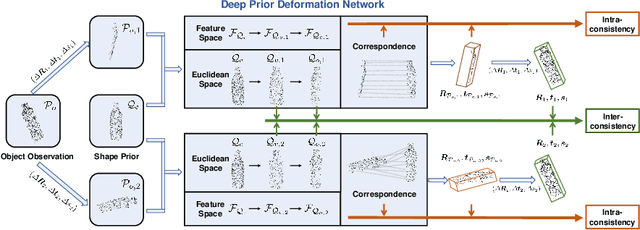
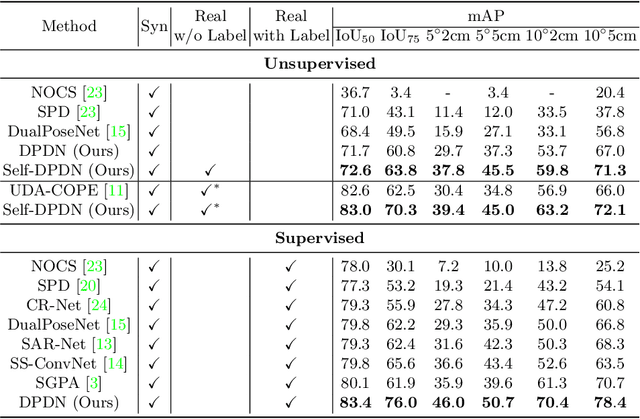
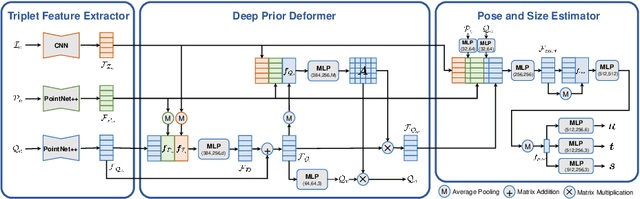
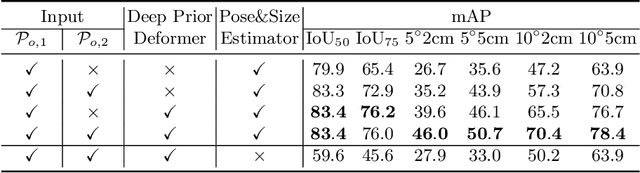
It is difficult to precisely annotate object instances and their semantics in 3D space, and as such, synthetic data are extensively used for these tasks, e.g., category-level 6D object pose and size estimation. However, the easy annotations in synthetic domains bring the downside effect of synthetic-to-real (Sim2Real) domain gap. In this work, we aim to address this issue in the task setting of Sim2Real, unsupervised domain adaptation for category-level 6D object pose and size estimation. We propose a method that is built upon a novel Deep Prior Deformation Network, shortened as DPDN. DPDN learns to deform features of categorical shape priors to match those of object observations, and is thus able to establish deep correspondence in the feature space for direct regression of object poses and sizes. To reduce the Sim2Real domain gap, we formulate a novel self-supervised objective upon DPDN via consistency learning; more specifically, we apply two rigid transformations to each object observation in parallel, and feed them into DPDN respectively to yield dual sets of predictions; on top of the parallel learning, an inter-consistency term is employed to keep cross consistency between dual predictions for improving the sensitivity of DPDN to pose changes, while individual intra-consistency ones are used to enforce self-adaptation within each learning itself. We train DPDN on both training sets of the synthetic CAMERA25 and real-world REAL275 datasets; our results outperform the existing methods on REAL275 test set under both the unsupervised and supervised settings. Ablation studies also verify the efficacy of our designs. Our code is released publicly at https://github.com/JiehongLin/Self-DPDN.
DualPoseNet: Category-level 6D Object Pose and Size Estimation using Dual Pose Network with Refined Learning of Pose Consistency
Apr 06, 2021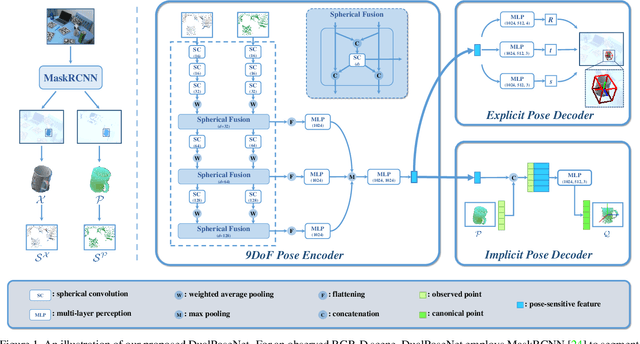
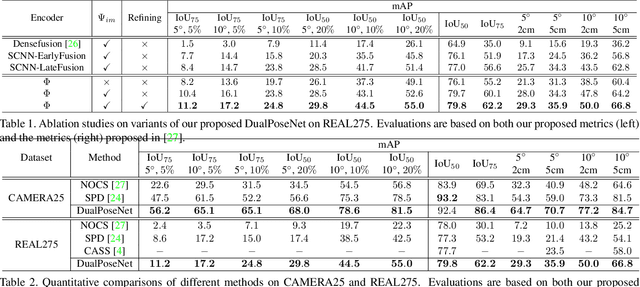
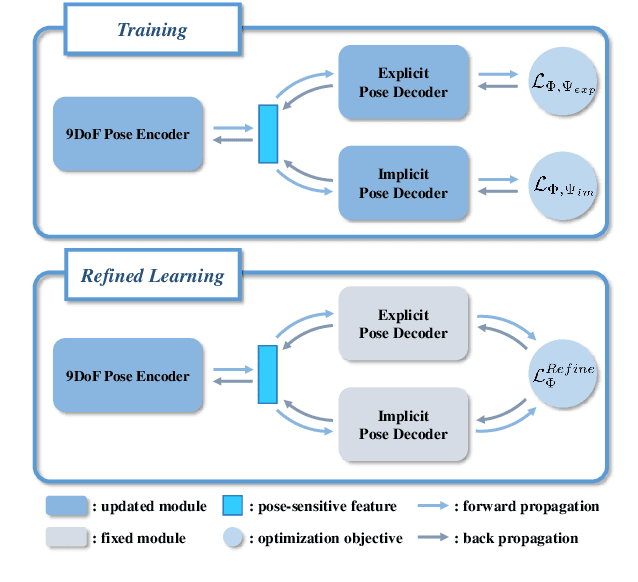
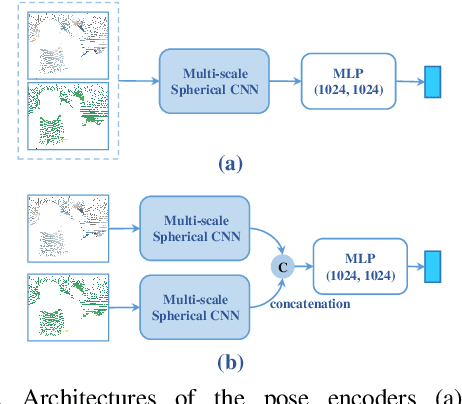
Category-level 6D object pose and size estimation is to predict 9 degrees-of-freedom (9DoF) pose configurations of rotation, translation, and size for object instances observed in single, arbitrary views of cluttered scenes. It extends previous related tasks with learning of the two additional rotation angles. This seemingly small difference poses technical challenges due to the learning and prediction in the full rotation space of SO(3). In this paper, we propose a new method of Dual Pose Network with refined learning of pose consistency for this task, shortened as DualPoseNet. DualPoseNet stacks two parallel pose decoders on top of a shared pose encoder, where the implicit decoder predicts object poses with a working mechanism different from that of the explicit one; they thus impose complementary supervision on the training of pose encoder. We construct the encoder based on spherical convolutions, and design a module of Spherical Fusion wherein for a better embedding of pose-sensitive features from the appearance and shape observations. Given no the testing CAD models, it is the novel introduction of the implicit decoder that enables the refined pose prediction during testing, by enforcing the predicted pose consistency between the two decoders using a self-adaptive loss term. Thorough experiments on the benchmark 9DoF object pose datasets of CAMERA25 and REAL275 confirm efficacy of our designs. DualPoseNet outperforms existing methods with a large margin in the regime of high precision.