 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePicoPose: Progressive Pixel-to-Pixel Correspondence Learning for Novel Object Pose Estimation
Apr 03, 2025Novel object pose estimation from RGB images presents a significant challenge for zero-shot generalization, as it involves estimating the relative 6D transformation between an RGB observation and a CAD model of an object that was not seen during training. In this paper, we introduce PicoPose, a novel framework designed to tackle this task using a three-stage pixel-to-pixel correspondence learning process. Firstly, PicoPose matches features from the RGB observation with those from rendered object templates, identifying the best-matched template and establishing coarse correspondences. Secondly, PicoPose smooths the correspondences by globally regressing a 2D affine transformation, including in-plane rotation, scale, and 2D translation, from the coarse correspondence map. Thirdly, PicoPose applies the affine transformation to the feature map of the best-matched template and learns correspondence offsets within local regions to achieve fine-grained correspondences. By progressively refining the correspondences, PicoPose significantly improves the accuracy of object poses computed via PnP/RANSAC. PicoPose achieves state-of-the-art performance on the seven core datasets of the BOP benchmark, demonstrating exceptional generalization to novel objects represented by CAD models or object reference images. Code and models are available at https://github.com/foollh/PicoPose.
GRFormer: Grouped Residual Self-Attention for Lightweight Single Image Super-Resolution
Aug 14, 2024


Previous works have shown that reducing parameter overhead and computations for transformer-based single image super-resolution (SISR) models (e.g., SwinIR) usually leads to a reduction of performance. In this paper, we present GRFormer, an efficient and lightweight method, which not only reduces the parameter overhead and computations, but also greatly improves performance. The core of GRFormer is Grouped Residual Self-Attention (GRSA), which is specifically oriented towards two fundamental components. Firstly, it introduces a novel grouped residual layer (GRL) to replace the Query, Key, Value (QKV) linear layer in self-attention, aimed at efficiently reducing parameter overhead, computations, and performance loss at the same time. Secondly, it integrates a compact Exponential-Space Relative Position Bias (ES-RPB) as a substitute for the original relative position bias to improve the ability to represent position information while further minimizing the parameter count. Extensive experimental results demonstrate that GRFormer outperforms state-of-the-art transformer-based methods for $\times$2, $\times$3 and $\times$4 SISR tasks, notably outperforming SOTA by a maximum PSNR of 0.23dB when trained on the DIV2K dataset, while reducing the number of parameter and MACs by about \textbf{60\%} and \textbf{49\% } in only self-attention module respectively. We hope that our simple and effective method that can easily applied to SR models based on window-division self-attention can serve as a useful tool for further research in image super-resolution. The code is available at \url{https://github.com/sisrformer/GRFormer}.
SAM-6D: Segment Anything Model Meets Zero-Shot 6D Object Pose Estimation
Nov 27, 2023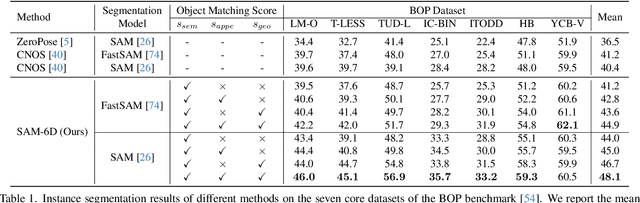
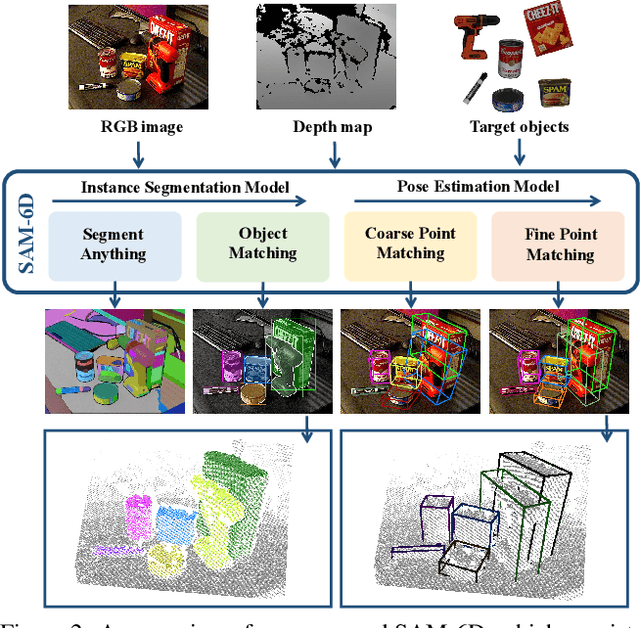
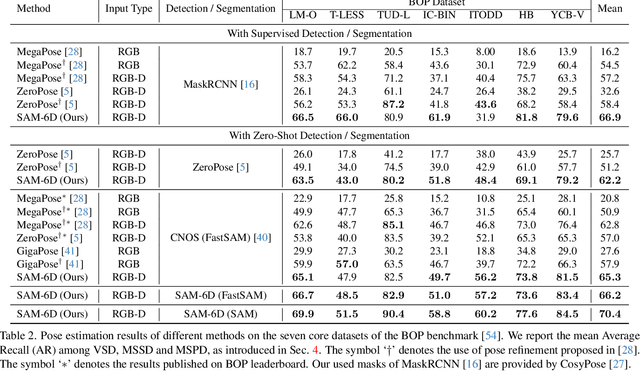
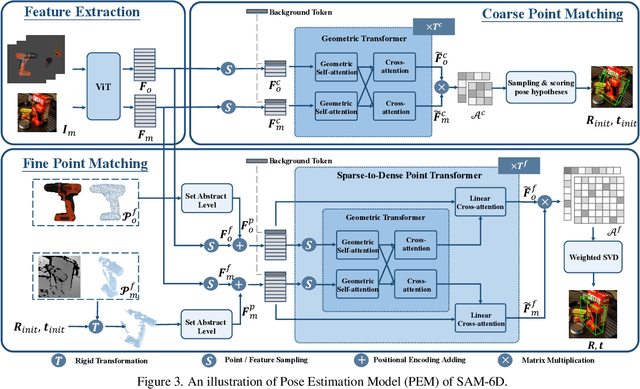
Zero-shot 6D object pose estimation involves the detection of novel objects with their 6D poses in cluttered scenes, presenting significant challenges for model generalizability. Fortunately, the recent Segment Anything Model (SAM) has showcased remarkable zero-shot transfer performance, which provides a promising solution to tackle this task. Motivated by this, we introduce SAM-6D, a novel framework designed to realize the task through two steps, including instance segmentation and pose estimation. Given the target objects, SAM-6D employs two dedicated sub-networks, namely Instance Segmentation Model (ISM) and Pose Estimation Model (PEM), to perform these steps on cluttered RGB-D images. ISM takes SAM as an advanced starting point to generate all possible object proposals and selectively preserves valid ones through meticulously crafted object matching scores in terms of semantics, appearance and geometry. By treating pose estimation as a partial-to-partial point matching problem, PEM performs a two-stage point matching process featuring a novel design of background tokens to construct dense 3D-3D correspondence, ultimately yielding the pose estimates. Without bells and whistles, SAM-6D outperforms the existing methods on the seven core datasets of the BOP Benchmark for both instance segmentation and pose estimation of novel objects.