 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCL-Net: Deep Correspondence Learning Network for 6D Pose Estimation
Paper and Code


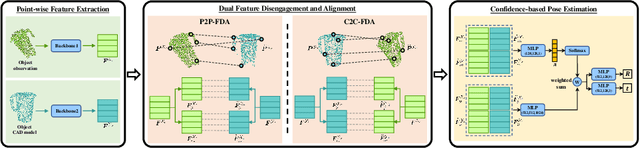

Establishment of point correspondence between camera and object coordinate systems is a promising way to solve 6D object poses. However, surrogate objectives of correspondence learning in 3D space are a step away from the true ones of object pose estimation, making the learning suboptimal for the end task. In this paper, we address this shortcoming by introducing a new method of Deep Correspondence Learning Network for direct 6D object pose estimation, shortened as DCL-Net. Specifically, DCL-Net employs dual newly proposed Feature Disengagement and Alignment (FDA) modules to establish, in the feature space, partial-to-partial correspondence and complete-to-complete one for partial object observation and its complete CAD model, respectively, which result in aggregated pose and match feature pairs from two coordinate systems; these two FDA modules thus bring complementary advantages. The match feature pairs are used to learn confidence scores for measuring the qualities of deep correspondence, while the pose feature pairs are weighted by confidence scores for direct object pose regression. A confidence-based pose refinement network is also proposed to further improve pose precision in an iterative manner. Extensive experiments show that DCL-Net outperforms existing methods on three benchmarking datasets, including YCB-Video, LineMOD, and Oclussion-LineMOD; ablation studies also confirm the efficacy of our novel designs.