 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Steerable Convolutions: An Efficient Learning of SE(3)-Equivariant Features for Estimation and Tracking of Object Poses in 3D Space
Paper and Code
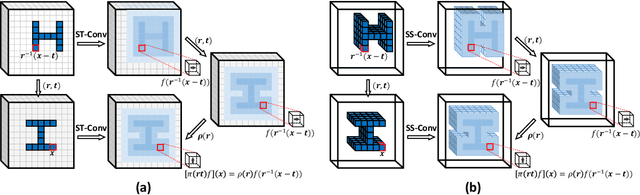

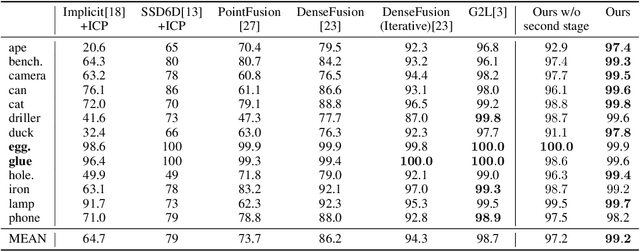
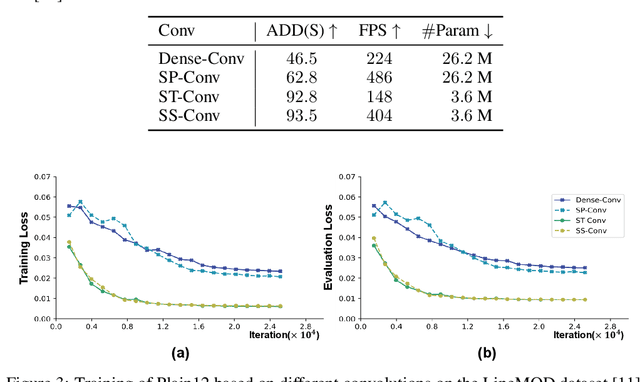
As a basic component of SE(3)-equivariant deep feature learning, steerable convolution has recently demonstrated its advantages for 3D semantic analysis. The advantages are, however, brought by expensive computations on dense, volumetric data, which prevent its practical use for efficient processing of 3D data that are inherently sparse. In this paper, we propose a novel design of Sparse Steerable Convolution (SS-Conv) to address the shortcoming; SS-Conv greatly accelerates steerable convolution with sparse tensors, while strictly preserving the property of SE(3)-equivariance. Based on SS-Conv, we propose a general pipeline for precise estimation of object poses, wherein a key design is a Feature-Steering module that takes the full advantage of SE(3)-equivariance and is able to conduct an efficient pose refinement. To verify our designs, we conduct thorough experiments on three tasks of 3D object semantic analysis, including instance-level 6D pose estimation, category-level 6D pose and size estimation, and category-level 6D pose tracking. Our proposed pipeline based on SS-Conv outperforms existing methods on almost all the metrics evaluated by the three tasks. Ablation studies also show the superiority of our SS-Conv over alternative convolutions in terms of both accuracy and efficiency. Our code is released publicly at https://github.com/Gorilla-Lab-SCUT/SS-Conv.