 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2C: Visual Voice Cloning
Paper and Code
Nov 25, 2021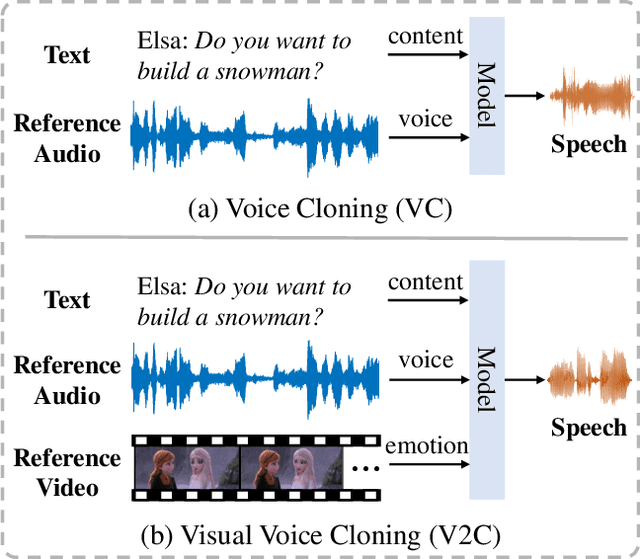
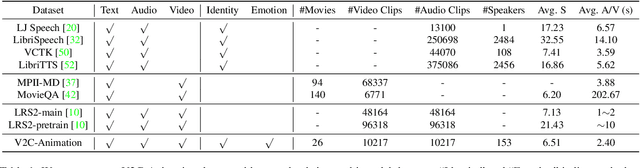

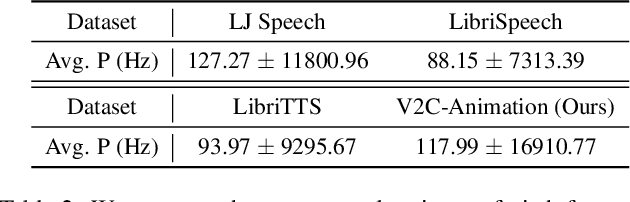
Existing Voice Cloning (VC) tasks aim to convert a paragraph text to a speech with desired voice specified by a reference audio. This has significantly boosted the development of artificial speech applications. However, there also exist many scenarios that cannot be well reflected by these VC tasks, such as movie dubbing, which requires the speech to be with emotions consistent with the movie plots. To fill this gap, in this work we propose a new task named Visual Voice Cloning (V2C), which seeks to convert a paragraph of text to a speech with both desired voice specified by a reference audio and desired emotion specified by a reference video. To facilitate research in this field, we construct a dataset, V2C-Animation, and propose a strong baseline based on existing state-of-the-art (SoTA) VC techniques. Our dataset contains 10,217 animated movie clips covering a large variety of genres (e.g., Comedy, Fantasy) and emotions (e.g., happy, sad). We further design a set of evaluation metrics, named MCD-DTW-SL, which help evaluate the similarity between ground-truth speeches and the synthesised ones. Extensive experimental results show that even SoTA VC methods cannot generate satisfying speeches for our V2C task. We hope the proposed new task together with the constructed dataset and evaluation metric will facilitate the research in the field of voice cloning and the broader vision-and-language community.