 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRID: Scene-Graph-based Instruction-driven Robotic Task Planning
Paper and Code
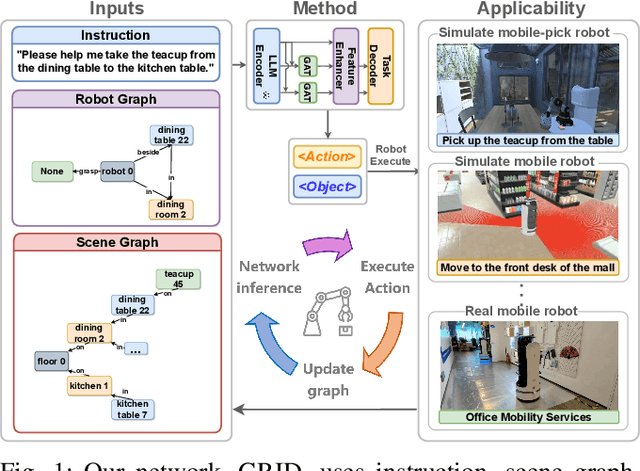
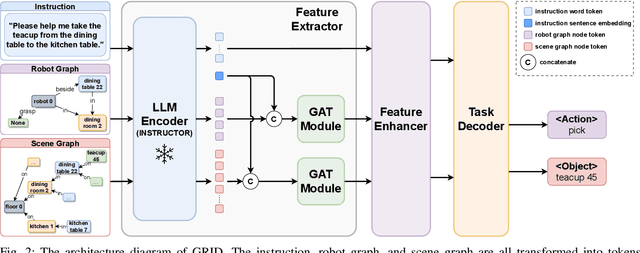
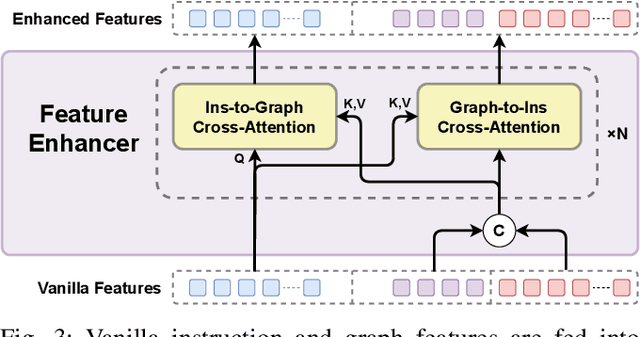
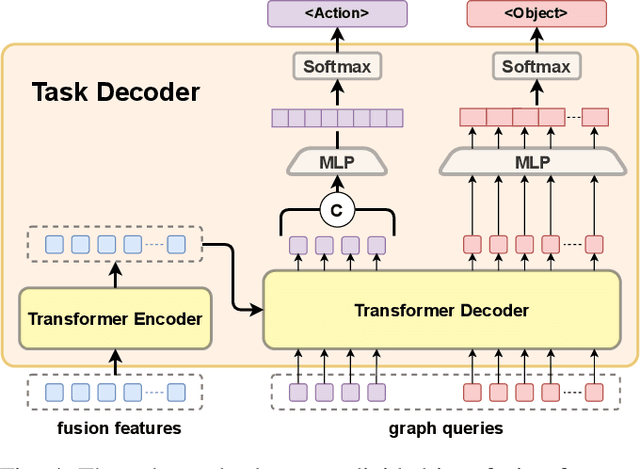
Recent works have shown that Large Language Models (LLMs) can promote grounding instructions to robotic task planning. Despite the progress, most existing works focused on utilizing raw images to help LLMs understand environmental information, which not only limits the observation scope but also typically requires massive multimodal data collection and large-scale models. In this paper, we propose a novel approach called Graph-based Robotic Instruction Decomposer (GRID), leverages scene graph instead of image to perceive global scene information and continuously plans subtask in each stage for a given instruction. Our method encodes object attributes and relationships in graphs through an LLM and Graph Attention Networks, integrating instruction features to predict subtasks consisting of pre-defined robot actions and target objects in the scene graph. This strategy enables robots to acquire semantic knowledge widely observed in the environment from the scene graph. To train and evaluate GRID, we build a dataset construction pipeline to generate synthetic datasets in graph-based robotic task planning. Experiments have shown that our method outperforms GPT-4 by over 25.4% in subtask accuracy and 43.6% in task accuracy. Experiments conducted on datasets of unseen scenes and scenes with different numbers of objects showed that the task accuracy of GRID declined by at most 3.8%, which demonstrates its good cross-scene generalization ability. We validate our method in both physical simulation and the real world.