 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient One-stage Video Object Detection by Exploiting Temporal Consistency
Feb 14, 2024Recently, one-stage detectors have achieved competitive accuracy and faster speed compared with traditional two-stage detectors on image data. However, in the field of video object detection (VOD), most existing VOD methods are still based on two-stage detectors. Moreover, directly adapting existing VOD methods to one-stage detectors introduces unaffordable computational costs. In this paper, we first analyse the computational bottlenecks of using one-stage detectors for VOD. Based on the analysis, we present a simple yet efficient framework to address the computational bottlenecks and achieve efficient one-stage VOD by exploiting the temporal consistency in video frames. Specifically, our method consists of a location-prior network to filter out background regions and a size-prior network to skip unnecessary computations on low-level feature maps for specific frames. We test our method on various modern one-stage detectors and conduct extensive experiments on the ImageNet VID dataset. Excellent experimental results demonstrate the superior effectiveness, efficiency, and compatibility of our method. The code is available at https://github.com/guanxiongsun/vfe.pytorch.
TDViT: Temporal Dilated Video Transformer for Dense Video Tasks
Feb 14, 2024Deep video models, for example, 3D CNNs or video transformers, have achieved promising performance on sparse video tasks, i.e., predicting one result per video. However, challenges arise when adapting existing deep video models to dense video tasks, i.e., predicting one result per frame. Specifically, these models are expensive for deployment, less effective when handling redundant frames, and difficult to capture long-range temporal correlations. To overcome these issues, we propose a Temporal Dilated Video Transformer (TDViT) that consists of carefully designed temporal dilated transformer blocks (TDTB). TDTB can efficiently extract spatiotemporal representations and effectively alleviate the negative effect of temporal redundancy. Furthermore, by using hierarchical TDTBs, our approach obtains an exponentially expanded temporal receptive field and therefore can model long-range dynamics. Extensive experiments are conducted on two different dense video benchmarks, i.e., ImageNet VID for video object detection and YouTube VIS for video instance segmentation. Excellent experimental results demonstrate the superior efficiency, effectiveness, and compatibility of our method. The code is available at https://github.com/guanxiongsun/vfe.pytorch.
MAMBA: Multi-level Aggregation via Memory Bank for Video Object Detection
Feb 01, 2024



State-of-the-art video object detection methods maintain a memory structure, either a sliding window or a memory queue, to enhance the current frame using attention mechanisms. However, we argue that these memory structures are not efficient or sufficient because of two implied operations: (1) concatenating all features in memory for enhancement, leading to a heavy computational cost; (2) frame-wise memory updating, preventing the memory from capturing more temporal information. In this paper, we propose a multi-level aggregation architecture via memory bank called MAMBA. Specifically, our memory bank employs two novel operations to eliminate the disadvantages of existing methods: (1) light-weight key-set construction which can significantly reduce the computational cost; (2) fine-grained feature-wise updating strategy which enables our method to utilize knowledge from the whole video. To better enhance features from complementary levels, i.e., feature maps and proposals, we further propose a generalized enhancement operation (GEO) to aggregate multi-level features in a unified manner. We conduct extensive evaluations on the challenging ImageNetVID dataset. Compared with existing state-of-the-art methods, our method achieves superior performance in terms of both speed and accuracy. More remarkably, MAMBA achieves mAP of 83.7/84.6% at 12.6/9.1 FPS with ResNet-101. Code is available at https://github.com/guanxiongsun/vfe.pytorch.
* update code url https://github.com/guanxiongsun/vfe.pytorch
Imbalance Robust Softmax for Deep Embeeding Learning
Nov 23, 2020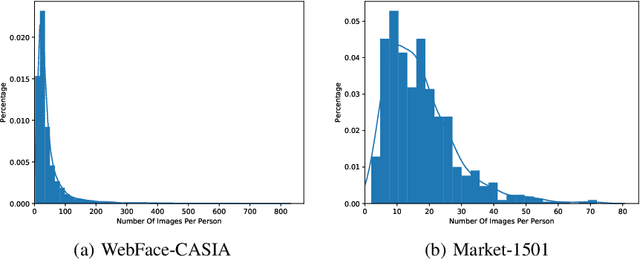
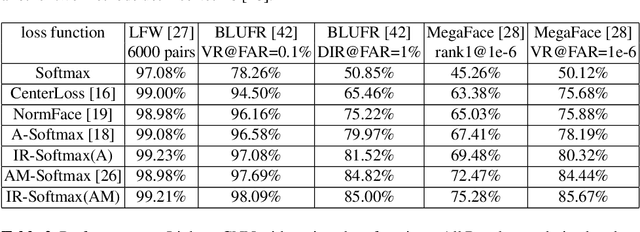
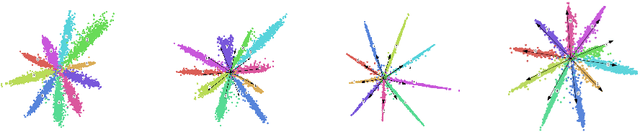
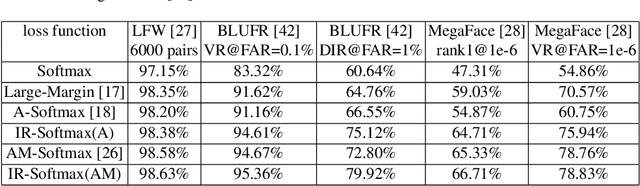
Deep embedding learning is expected to learn a metric space in which features have smaller maximal intra-class distance than minimal inter-class distance. In recent years, one research focus is to solve the open-set problem by discriminative deep embedding learning in the field of face recognition (FR) and person re-identification (re-ID). Apart from open-set problem, we find that imbalanced training data is another main factor causing the performance degradation of FR and re-ID, and data imbalance widely exists in the real applications. However, very little research explores why and how data imbalance influences the performance of FR and re-ID with softmax or its variants. In this work, we deeply investigate data imbalance in the perspective of neural network optimisation and feature distribution about softmax. We find one main reason of performance degradation caused by data imbalance is that the weights (from the penultimate fully-connected layer) are far from their class centers in feature space. Based on this investigation, we propose a unified framework, Imbalance-Robust Softmax (IR-Softmax), which can simultaneously solve the open-set problem and reduce the influence of data imbalance. IR-Softmax can generalise to any softmax and its variants (which are discriminative for open-set problem) by directly setting the weights as their class centers, naturally solving the data imbalance problem. In this work, we explicitly re-formulate two discriminative softmax (A-Softmax and AM-Softmax) under the framework of IR-Softmax. We conduct extensive experiments on FR databases (LFW, MegaFace) and re-ID database (Market-1501, Duke), and IR-Softmax outperforms many state-of-the-art methods.
ParaCNN: Visual Paragraph Generation via Adversarial Twin Contextual CNNs
Apr 21, 2020

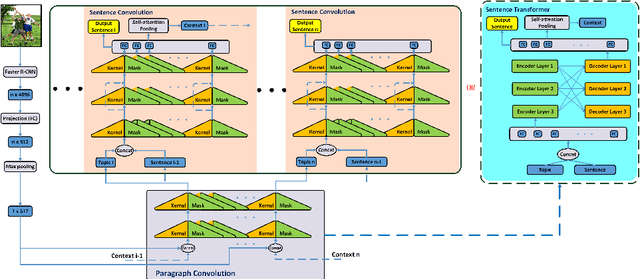

Image description generation plays an important role in many real-world applications, such as image retrieval, automatic navigation, and disabled people support. A well-developed task of image description generation is image captioning, which usually generates a short captioning sentence and thus neglects many of fine-grained properties, e.g., the information of subtle objects and their relationships. In this paper, we study the visual paragraph generation, which can describe the image with a long paragraph containing rich details. Previous research often generates the paragraph via a hierarchical Recurrent Neural Network (RNN)-like model, which has complex memorising, forgetting and coupling mechanism. Instead, we propose a novel pure CNN model, ParaCNN, to generate visual paragraph using hierarchical CNN architecture with contextual information between sentences within one paragraph. The ParaCNN can generate an arbitrary length of a paragraph, which is more applicable in many real-world applications. Furthermore, to enable the ParaCNN to model paragraph comprehensively, we also propose an adversarial twin net training scheme. During training, we force the forwarding network's hidden features to be close to that of the backwards network by using adversarial training. During testing, we only use the forwarding network, which already includes the knowledge of the backwards network, to generate a paragraph. We conduct extensive experiments on the Stanford Visual Paragraph dataset and achieve state-of-the-art performance.
Instance Cross Entropy for Deep Metric Learning
Nov 22, 2019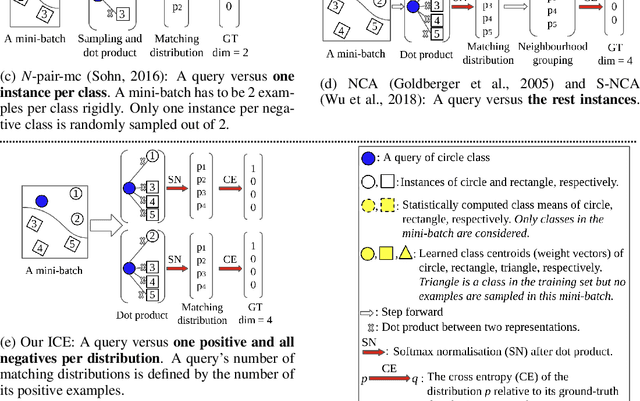
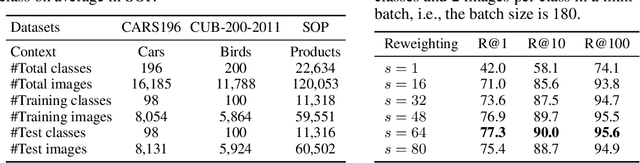

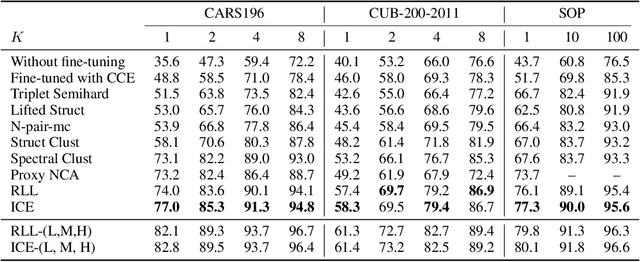
Loss functions play a crucial role in deep metric learning thus a variety of them have been proposed. Some supervise the learning process by pairwise or tripletwise similarity constraints while others take advantage of structured similarity information among multiple data points. In this work, we approach deep metric learning from a novel perspective. We propose instance cross entropy (ICE) which measures the difference between an estimated instance-level matching distribution and its ground-truth one. ICE has three main appealing properties. Firstly, similar to categorical cross entropy (CCE), ICE has clear probabilistic interpretation and exploits structured semantic similarity information for learning supervision. Secondly, ICE is scalable to infinite training data as it learns on mini-batches iteratively and is independent of the training set size. Thirdly, motivated by our relative weight analysis, seamless sample reweighting is incorporated. It rescales samples' gradients to control the differentiation degree over training examples instead of truncating them by sample mining. In addition to its simplicity and intuitiveness, extensive experiments on three real-world benchmarks demonstrate the superiority of ICE.
Emphasis Regularisation by Gradient Rescaling for Training Deep Neural Networks with Noisy Labels
May 27, 2019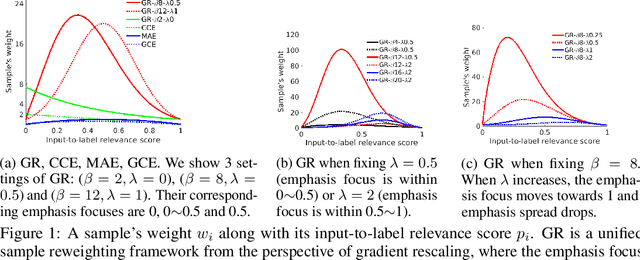

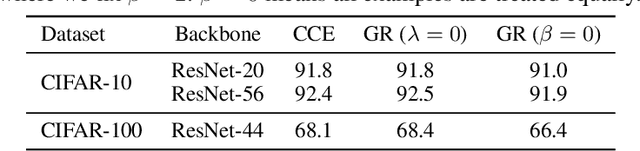
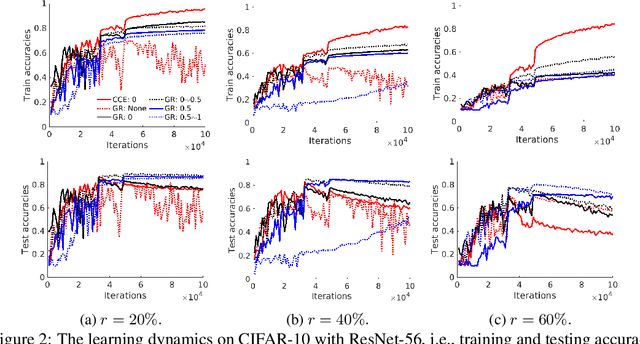
It is fundamental and challenging to train robust and accurate Deep Neural Networks (DNNs) when noisy labels exist. Although great progress has been made, there is still one crucial research question which is not thoroughly explored yet: What training examples should be focused and how much more should they be emphasised when training DNNs under label noise? In this work, we study this question and propose gradient rescaling (GR) to solve it. GR modifies the magnitude of logit vector's gradient to emphasise on relatively easier training data points when severe noise exists, which functions as explicit emphasis regularisation to improve the generalisation performance of DNNs. Apart from regularisation, we also interpret GR from the perspectives of sample reweighting and designing robust loss functions. Therefore, our proposed GR helps connect these three approaches in the literature. We empirically demonstrate that GR is highly noise-robust and outperforms the state-of-the-art noise-tolerant algorithms by a large margin, e.g., increasing 7% on CIFAR-100 with 40% noisy labels. It is also significantly superior to standard regularisors. Furthermore, we present comprehensive ablation studies to explore the behaviours of GR under different cases, which is informative for applying GR in real-world scenarios.
IEGAN: Multi-purpose Perceptual Quality Image Enhancement Using Generative Adversarial Network
Nov 22, 2018
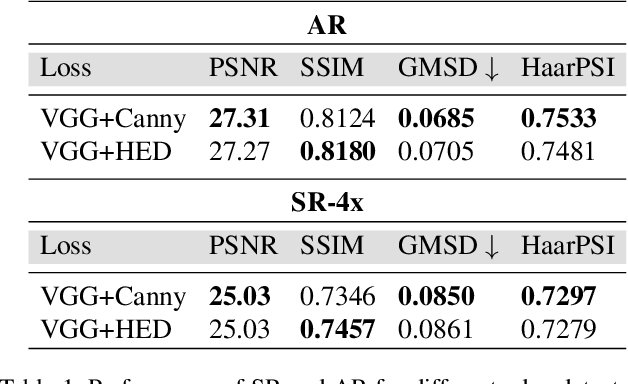
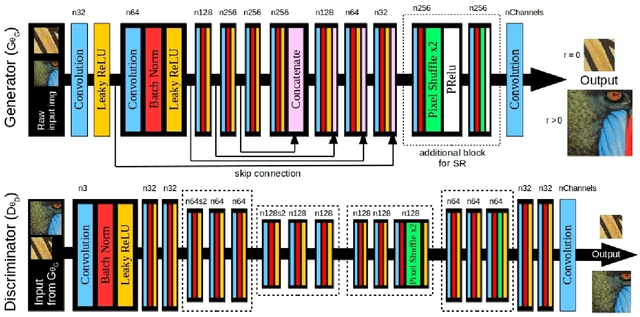
Despite the breakthroughs in quality of image enhancement, an end-to-end solution for simultaneous recovery of the finer texture details and sharpness for degraded images with low resolution is still unsolved. Some existing approaches focus on minimizing the pixel-wise reconstruction error which results in a high peak signal-to-noise ratio. The enhanced images fail to provide high-frequency details and are perceptually unsatisfying, i.e., they fail to match the quality expected in a photo-realistic image. In this paper, we present Image Enhancement Generative Adversarial Network (IEGAN), a versatile framework capable of inferring photo-realistic natural images for both artifact removal and super-resolution simultaneously. Moreover, we propose a new loss function consisting of a combination of reconstruction loss, feature loss and an edge loss counterpart. The feature loss helps to push the output image to the natural image manifold and the edge loss preserves the sharpness of the output image. The reconstruction loss provides low-level semantic information to the generator regarding the quality of the generated images compared to the original. Our approach has been experimentally proven to recover photo-realistic textures from heavily compressed low-resolution images on public benchmarks and our proposed high-resolution World100 dataset.