 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaCNN: Visual Paragraph Generation via Adversarial Twin Contextual CNNs
Paper and Code
Apr 21, 2020

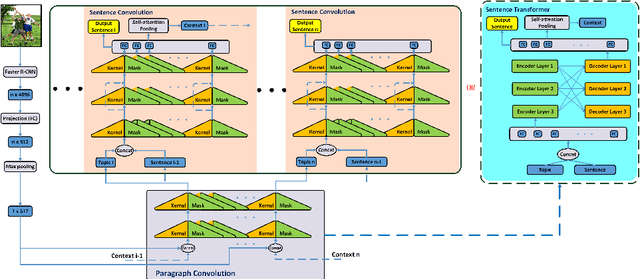

Image description generation plays an important role in many real-world applications, such as image retrieval, automatic navigation, and disabled people support. A well-developed task of image description generation is image captioning, which usually generates a short captioning sentence and thus neglects many of fine-grained properties, e.g., the information of subtle objects and their relationships. In this paper, we study the visual paragraph generation, which can describe the image with a long paragraph containing rich details. Previous research often generates the paragraph via a hierarchical Recurrent Neural Network (RNN)-like model, which has complex memorising, forgetting and coupling mechanism. Instead, we propose a novel pure CNN model, ParaCNN, to generate visual paragraph using hierarchical CNN architecture with contextual information between sentences within one paragraph. The ParaCNN can generate an arbitrary length of a paragraph, which is more applicable in many real-world applications. Furthermore, to enable the ParaCNN to model paragraph comprehensively, we also propose an adversarial twin net training scheme. During training, we force the forwarding network's hidden features to be close to that of the backwards network by using adversarial training. During testing, we only use the forwarding network, which already includes the knowledge of the backwards network, to generate a paragraph. We conduct extensive experiments on the Stanford Visual Paragraph dataset and achieve state-of-the-art performance.