 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmphasis Regularisation by Gradient Rescaling for Training Deep Neural Networks with Noisy Labels
Paper and Code
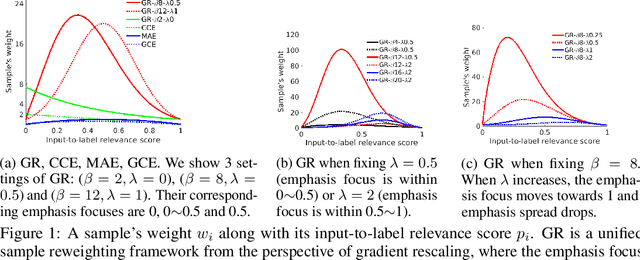

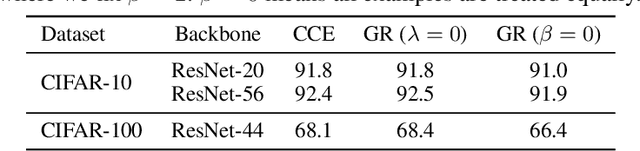
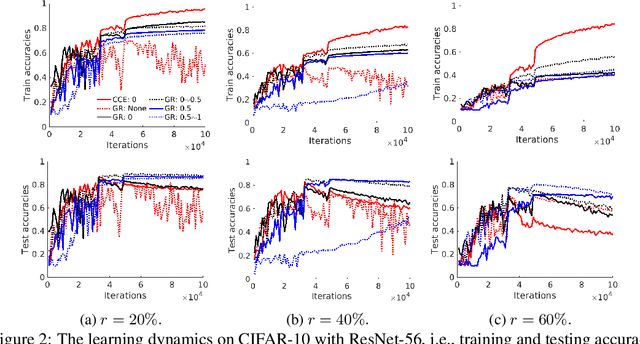
It is fundamental and challenging to train robust and accurate Deep Neural Networks (DNNs) when noisy labels exist. Although great progress has been made, there is still one crucial research question which is not thoroughly explored yet: What training examples should be focused and how much more should they be emphasised when training DNNs under label noise? In this work, we study this question and propose gradient rescaling (GR) to solve it. GR modifies the magnitude of logit vector's gradient to emphasise on relatively easier training data points when severe noise exists, which functions as explicit emphasis regularisation to improve the generalisation performance of DNNs. Apart from regularisation, we also interpret GR from the perspectives of sample reweighting and designing robust loss functions. Therefore, our proposed GR helps connect these three approaches in the literature. We empirically demonstrate that GR is highly noise-robust and outperforms the state-of-the-art noise-tolerant algorithms by a large margin, e.g., increasing 7% on CIFAR-100 with 40% noisy labels. It is also significantly superior to standard regularisors. Furthermore, we present comprehensive ablation studies to explore the behaviours of GR under different cases, which is informative for applying GR in real-world scenarios.