 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Volumetric Object Selection
May 30, 2022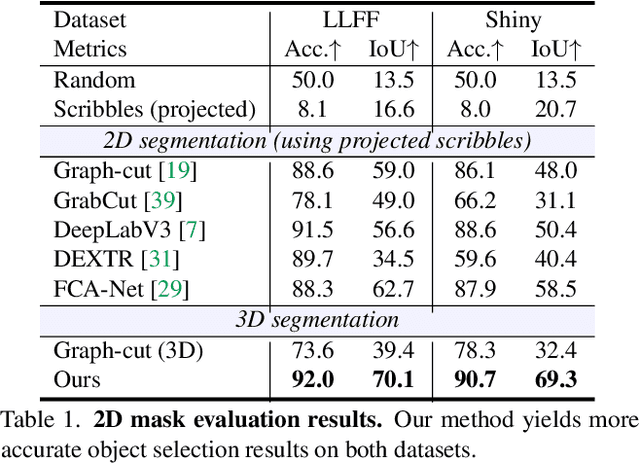
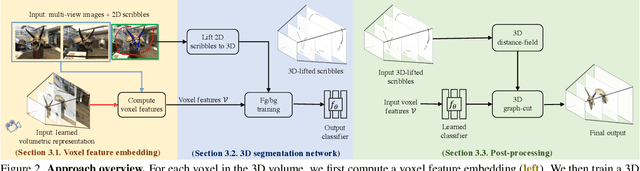


We introduce an approach for selecting objects in neural volumetric 3D representations, such as multi-plane images (MPI) and neural radiance fields (NeRF). Our approach takes a set of foreground and background 2D user scribbles in one view and automatically estimates a 3D segmentation of the desired object, which can be rendered into novel views. To achieve this result, we propose a novel voxel feature embedding that incorporates the neural volumetric 3D representation and multi-view image features from all input views. To evaluate our approach, we introduce a new dataset of human-provided segmentation masks for depicted objects in real-world multi-view scene captures. We show that our approach out-performs strong baselines, including 2D segmentation and 3D segmentation approaches adapted to our task.
Deep Homography Estimation for Dynamic Scenes
Apr 05, 2020

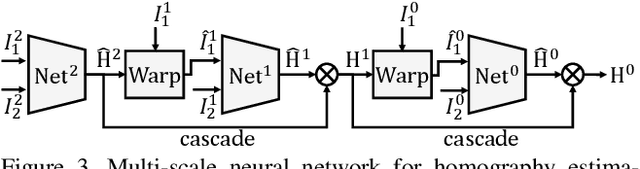
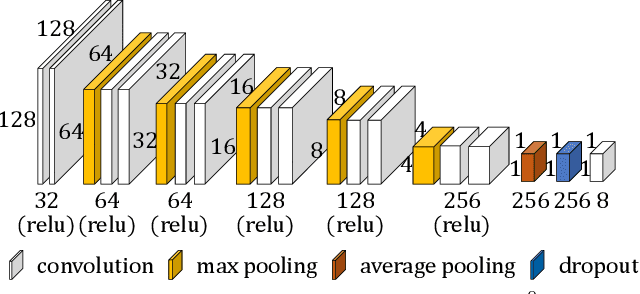
Homography estimation is an important step in many computer vision problems. Recently, deep neural network methods have shown to be favorable for this problem when compared to traditional methods. However, these new methods do not consider dynamic content in input images. They train neural networks with only image pairs that can be perfectly aligned using homographies. This paper investigates and discusses how to design and train a deep neural network that handles dynamic scenes. We first collect a large video dataset with dynamic content. We then develop a multi-scale neural network and show that when properly trained using our new dataset, this neural network can already handle dynamic scenes to some extent. To estimate a homography of a dynamic scene in a more principled way, we need to identify the dynamic content. Since dynamic content detection and homography estimation are two tightly coupled tasks, we follow the multi-task learning principles and augment our multi-scale network such that it jointly estimates the dynamics masks and homographies. Our experiments show that our method can robustly estimate homography for challenging scenarios with dynamic scenes, blur artifacts, or lack of textures.
A Compact Embedding for Facial Expression Similarity
Nov 27, 2018


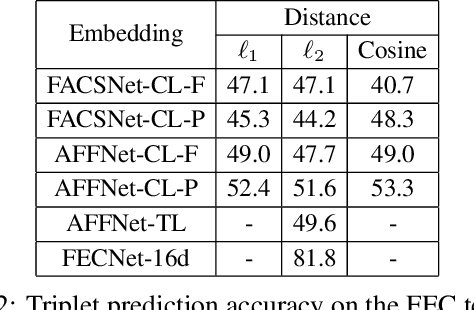
Most of the existing work on automatic facial expression analysis focuses on discrete emotion recognition, or facial action unit detection. However, facial expressions do not always fall neatly into pre-defined semantic categories. Also, the similarity between expressions measured in the action unit space need not correspond to how humans perceive expression similarity. Different from previous work, our goal is to describe facial expressions in a continuous fashion using a compact embedding space that mimics human visual preferences. To achieve this goal, we collect a large-scale faces-in-the-wild dataset with human annotations in the form: Expressions A and B are visually more similar when compared to expression C, and use this dataset to train a neural network that produces a compact (16-dimensional) expression embedding. We experimentally demonstrate that the learned embedding can be successfully used for various applications such as expression retrieval, photo album summarization, and emotion recognition. We also show that the embedding learned using the proposed dataset performs better than several other embeddings learned using existing emotion or action unit datasets.
Video Frame Synthesis using Deep Voxel Flow
Aug 05, 2017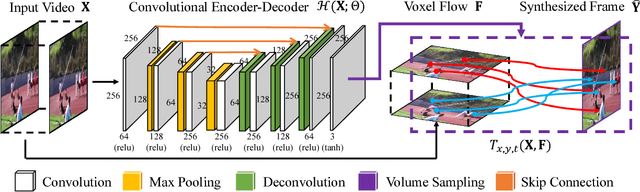
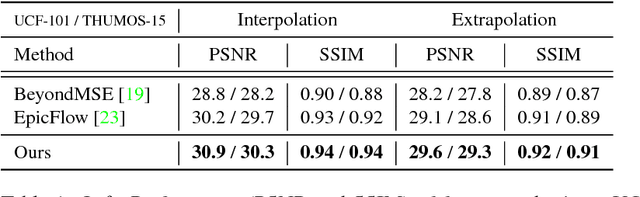
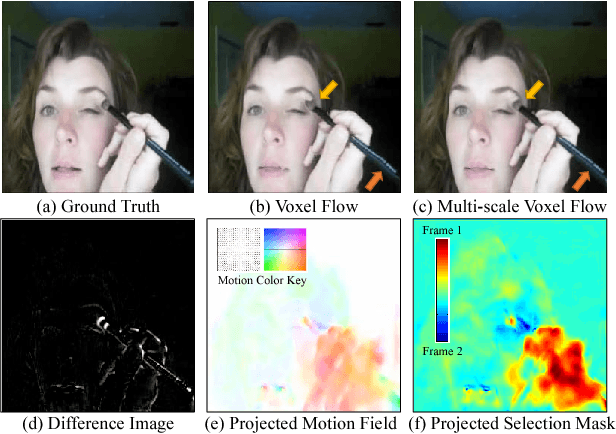
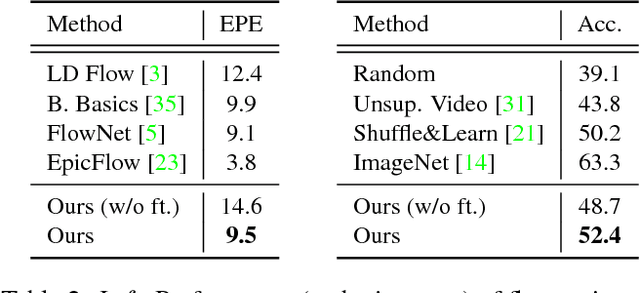
We address the problem of synthesizing new video frames in an existing video, either in-between existing frames (interpolation), or subsequent to them (extrapolation). This problem is challenging because video appearance and motion can be highly complex. Traditional optical-flow-based solutions often fail where flow estimation is challenging, while newer neural-network-based methods that hallucinate pixel values directly often produce blurry results. We combine the advantages of these two methods by training a deep network that learns to synthesize video frames by flowing pixel values from existing ones, which we call deep voxel flow. Our method requires no human supervision, and any video can be used as training data by dropping, and then learning to predict, existing frames. The technique is efficient, and can be applied at any video resolution. We demonstrate that our method produces results that both quantitatively and qualitatively improve upon the state-of-the-art.
Semantic Facial Expression Editing using Autoencoded Flow
Nov 30, 2016


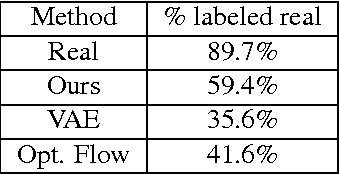
High-level manipulation of facial expressions in images --- such as changing a smile to a neutral expression --- is challenging because facial expression changes are highly non-linear, and vary depending on the appearance of the face. We present a fully automatic approach to editing faces that combines the advantages of flow-based face manipulation with the more recent generative capabilities of Variational Autoencoders (VAEs). During training, our model learns to encode the flow from one expression to another over a low-dimensional latent space. At test time, expression editing can be done simply using latent vector arithmetic. We evaluate our methods on two applications: 1) single-image facial expression editing, and 2) facial expression interpolation between two images. We demonstrate that our method generates images of higher perceptual quality than previous VAE and flow-based methods.
DeepFont: Identify Your Font from An Image
Jul 12, 2015
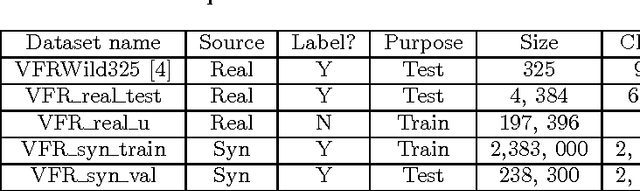


As font is one of the core design concepts, automatic font identification and similar font suggestion from an image or photo has been on the wish list of many designers. We study the Visual Font Recognition (VFR) problem, and advance the state-of-the-art remarkably by developing the DeepFont system. First of all, we build up the first available large-scale VFR dataset, named AdobeVFR, consisting of both labeled synthetic data and partially labeled real-world data. Next, to combat the domain mismatch between available training and testing data, we introduce a Convolutional Neural Network (CNN) decomposition approach, using a domain adaptation technique based on a Stacked Convolutional Auto-Encoder (SCAE) that exploits a large corpus of unlabeled real-world text images combined with synthetic data preprocessed in a specific way. Moreover, we study a novel learning-based model compression approach, in order to reduce the DeepFont model size without sacrificing its performance. The DeepFont system achieves an accuracy of higher than 80% (top-5) on our collected dataset, and also produces a good font similarity measure for font selection and suggestion. We also achieve around 6 times compression of the model without any visible loss of recognition accuracy.
Decomposition-Based Domain Adaptation for Real-World Font Recognition
Apr 01, 2015

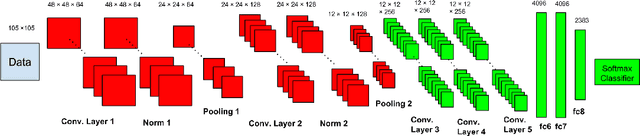

We present a domain adaption framework to address a domain mismatch between synthetic training and real-world testing data. We demonstrate our method on a challenging fine-grain classification problem: recognizing a font style from an image of text. In this task, it is very easy to generate lots of rendered font examples but very hard to obtain real-world labeled images. This real-to-synthetic domain gap caused poor generalization to new real data in previous font recognition methods (Chen et al. (2014)). In this paper, we introduce a Convolutional Neural Network decomposition approach, leveraging a large training corpus of synthetic data to obtain effective features for classification. This is done using an adaptation technique based on a Stacked Convolutional Auto-Encoder that exploits a large collection of unlabeled real-world text images combined with synthetic data preprocessed in a specific way. The proposed DeepFont method achieves an accuracy of higher than 80% (top-5) on a new large labeled real-world dataset we collected.
Real-World Font Recognition Using Deep Network and Domain Adaptation
Mar 31, 2015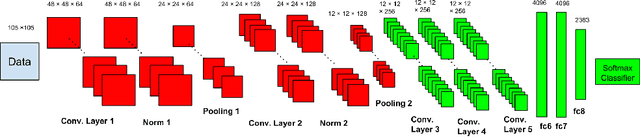
We address a challenging fine-grain classification problem: recognizing a font style from an image of text. In this task, it is very easy to generate lots of rendered font examples but very hard to obtain real-world labeled images. This real-to-synthetic domain gap caused poor generalization to new real data in previous methods (Chen et al. (2014)). In this paper, we refer to Convolutional Neural Networks, and use an adaptation technique based on a Stacked Convolutional Auto-Encoder that exploits unlabeled real-world images combined with synthetic data. The proposed method achieves an accuracy of higher than 80% (top-5) on a real-world dataset.
Recognizing Image Style
Jul 23, 2014


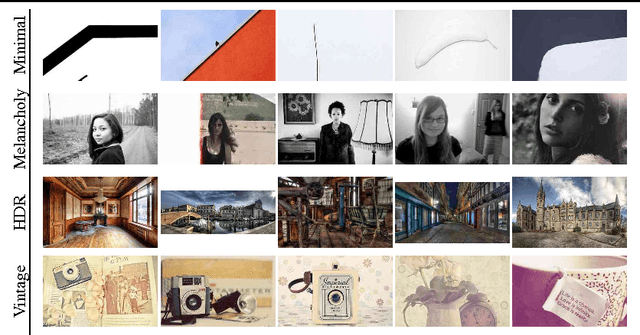
The style of an image plays a significant role in how it is viewed, but style has received little attention in computer vision research. We describe an approach to predicting style of images, and perform a thorough evaluation of different image features for these tasks. We find that features learned in a multi-layer network generally perform best -- even when trained with object class (not style) labels. Our large-scale learning methods results in the best published performance on an existing dataset of aesthetic ratings and photographic style annotations. We present two novel datasets: 80K Flickr photographs annotated with 20 curated style labels, and 85K paintings annotated with 25 style/genre labels. Our approach shows excellent classification performance on both datasets. We use the learned classifiers to extend traditional tag-based image search to consider stylistic constraints, and demonstrate cross-dataset understanding of style.