 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull Page Handwriting Recognition via Image to Sequence Extraction
Mar 11, 2021
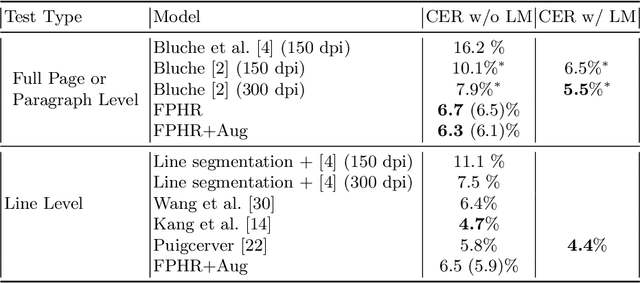


We present a Neural Network based Handwritten Text Recognition (HTR) model architecture that can be trained to recognize full pages of handwritten or printed text without image segmentation. Being based on an Image to Sequence architecture, it can be trained to extract text present in an image and sequence it correctly without imposing any constraints on language, shape of characters or orientation and layout of text and non-text. The model can also be trained to generate auxiliary markup related to formatting, layout and content. We use character level token vocabulary, thereby supporting proper nouns and terminology of any subject. The model achieves a new state-of-art in full page recognition on the IAM dataset and when evaluated on scans of real world handwritten free form test answers - a dataset beset with curved and slanted lines, drawings, tables, math, chemistry and other symbols - it performs better than all commercially available HTR APIs. It is deployed in production as part of a commercial web application.
Recognizing Image Style
Jul 23, 2014


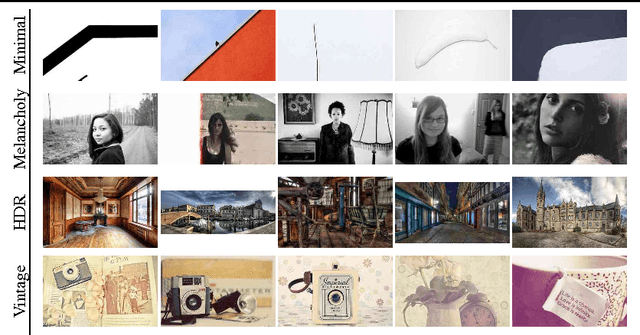
The style of an image plays a significant role in how it is viewed, but style has received little attention in computer vision research. We describe an approach to predicting style of images, and perform a thorough evaluation of different image features for these tasks. We find that features learned in a multi-layer network generally perform best -- even when trained with object class (not style) labels. Our large-scale learning methods results in the best published performance on an existing dataset of aesthetic ratings and photographic style annotations. We present two novel datasets: 80K Flickr photographs annotated with 20 curated style labels, and 85K paintings annotated with 25 style/genre labels. Our approach shows excellent classification performance on both datasets. We use the learned classifiers to extend traditional tag-based image search to consider stylistic constraints, and demonstrate cross-dataset understanding of style.
Caffe: Convolutional Architecture for Fast Feature Embedding
Jun 20, 2014

Caffe provides multimedia scientists and practitioners with a clean and modifiable framework for state-of-the-art deep learning algorithms and a collection of reference models. The framework is a BSD-licensed C++ library with Python and MATLAB bindings for training and deploying general-purpose convolutional neural networks and other deep models efficiently on commodity architectures. Caffe fits industry and internet-scale media needs by CUDA GPU computation, processing over 40 million images a day on a single K40 or Titan GPU ($\approx$ 2.5 ms per image). By separating model representation from actual implementation, Caffe allows experimentation and seamless switching among platforms for ease of development and deployment from prototyping machines to cloud environments. Caffe is maintained and developed by the Berkeley Vision and Learning Center (BVLC) with the help of an active community of contributors on GitHub. It powers ongoing research projects, large-scale industrial applications, and startup prototypes in vision, speech, and multimedia.
DenseNet: Implementing Efficient ConvNet Descriptor Pyramids
Apr 07, 2014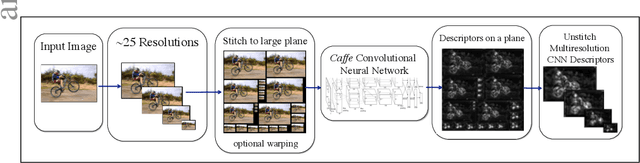
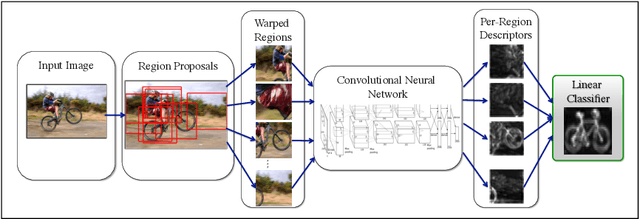
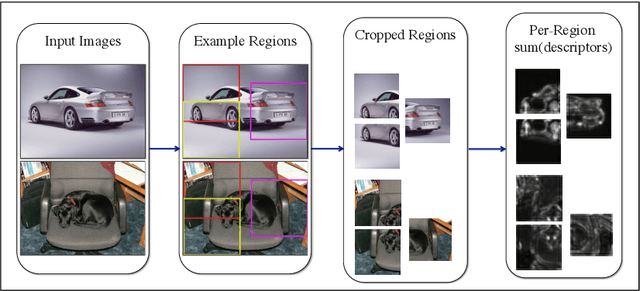
Convolutional Neural Networks (CNNs) can provide accurate object classification. They can be extended to perform object detection by iterating over dense or selected proposed object regions. However, the runtime of such detectors scales as the total number and/or area of regions to examine per image, and training such detectors may be prohibitively slow. However, for some CNN classifier topologies, it is possible to share significant work among overlapping regions to be classified. This paper presents DenseNet, an open source system that computes dense, multiscale features from the convolutional layers of a CNN based object classifier. Future work will involve training efficient object detectors with DenseNet feature descriptors.