 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Transformer Dynamics as Movement through Embedding Space
Aug 21, 2023



Transformer language models exhibit intelligent behaviors such as understanding natural language, recognizing patterns, acquiring knowledge, reasoning, planning, reflecting and using tools. This paper explores how their underlying mechanics give rise to intelligent behaviors. We adopt a systems approach to analyze Transformers in detail and develop a mathematical framework that frames their dynamics as movement through embedding space. This novel perspective provides a principled way of thinking about the problem and reveals important insights related to the emergence of intelligence: 1. At its core the Transformer is a Embedding Space walker, mapping intelligent behavior to trajectories in this vector space. 2. At each step of the walk, it composes context into a single composite vector whose location in Embedding Space defines the next step. 3. No learning actually occurs during decoding; in-context learning and generalization are simply the result of different contexts composing into different vectors. 4. Ultimately the knowledge, intelligence and skills exhibited by the model are embodied in the organization of vectors in Embedding Space rather than in specific neurons or layers. These abilities are properties of this organization. 5. Attention's contribution boils down to the association-bias it lends to vector composition and which influences the aforementioned organization. However, more investigation is needed to ascertain its significance. 6. The entire model is composed from two principal operations: data independent filtering and data dependent aggregation. This generalization unifies Transformers with other sequence models and across modalities. Building upon this foundation we formalize and test a semantic space theory which posits that embedding vectors represent semantic concepts and find some evidence of its validity.
Full Page Handwriting Recognition via Image to Sequence Extraction
Mar 11, 2021
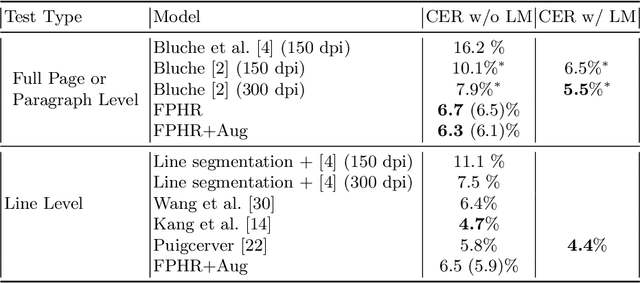


We present a Neural Network based Handwritten Text Recognition (HTR) model architecture that can be trained to recognize full pages of handwritten or printed text without image segmentation. Being based on an Image to Sequence architecture, it can be trained to extract text present in an image and sequence it correctly without imposing any constraints on language, shape of characters or orientation and layout of text and non-text. The model can also be trained to generate auxiliary markup related to formatting, layout and content. We use character level token vocabulary, thereby supporting proper nouns and terminology of any subject. The model achieves a new state-of-art in full page recognition on the IAM dataset and when evaluated on scans of real world handwritten free form test answers - a dataset beset with curved and slanted lines, drawings, tables, math, chemistry and other symbols - it performs better than all commercially available HTR APIs. It is deployed in production as part of a commercial web application.
Teaching Machines to Code: Neural Markup Generation with Visual Attention
Jun 15, 2018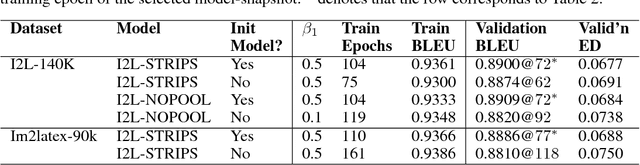
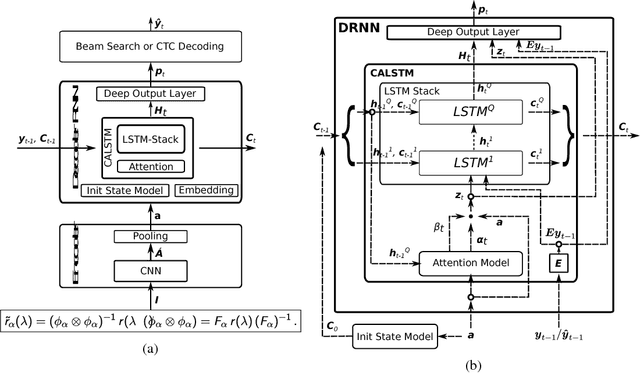
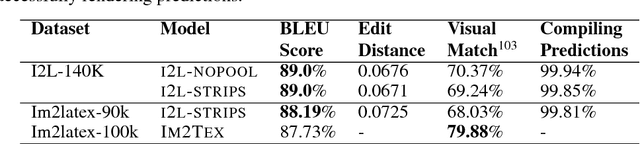
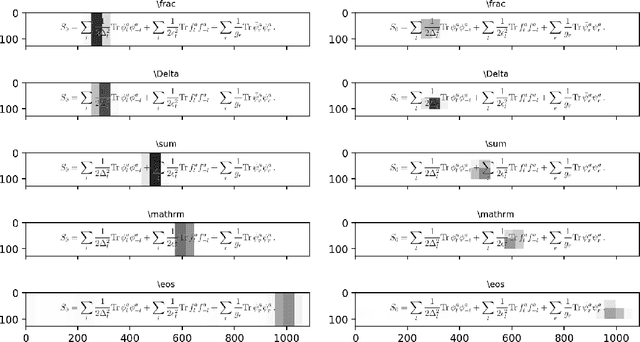
We present a neural transducer model with visual attention that learns to generate LaTeX markup of a real-world math formula given its image. Applying sequence modeling and transduction techniques that have been very successful across modalities such as natural language, image, handwriting, speech and audio; we construct an image-to-markup model that learns to produce syntactically and semantically correct LaTeX markup code over 150 words long and achieves a BLEU score of 89%; improving upon the previous state-of-art for the Im2Latex problem. We also demonstrate with heat-map visualization how attention helps in interpreting the model and can pinpoint (detect and localize) symbols on the image accurately despite having been trained without any bounding box data.