 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Convolutional Networks for Semantic Segmentation
May 20, 2016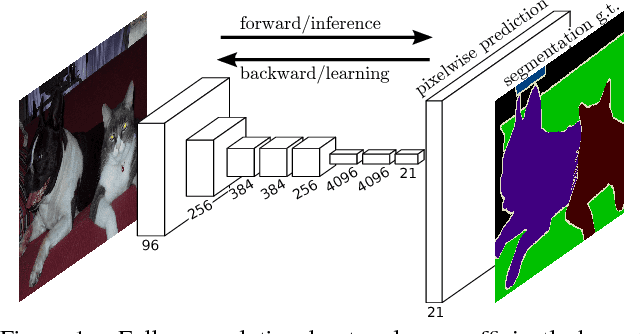
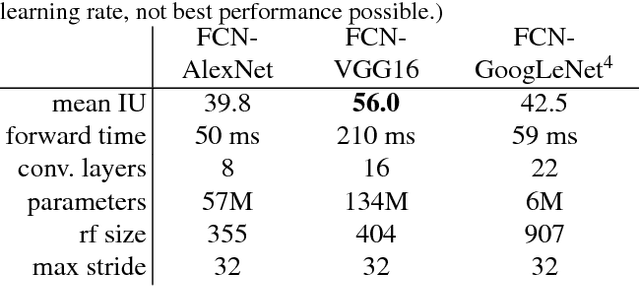

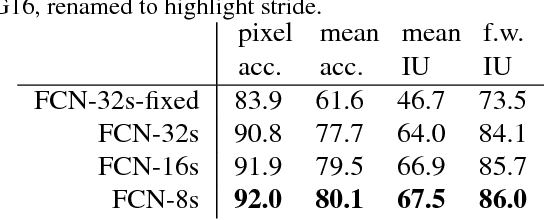
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, improve on the previous best result in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves improved segmentation of PASCAL VOC (30% relative improvement to 67.2% mean IU on 2012), NYUDv2, SIFT Flow, and PASCAL-Context, while inference takes one tenth of a second for a typical image.
Fully Convolutional Multi-Class Multiple Instance Learning
Apr 15, 2015

Multiple instance learning (MIL) can reduce the need for costly annotation in tasks such as semantic segmentation by weakening the required degree of supervision. We propose a novel MIL formulation of multi-class semantic segmentation learning by a fully convolutional network. In this setting, we seek to learn a semantic segmentation model from just weak image-level labels. The model is trained end-to-end to jointly optimize the representation while disambiguating the pixel-image label assignment. Fully convolutional training accepts inputs of any size, does not need object proposal pre-processing, and offers a pixelwise loss map for selecting latent instances. Our multi-class MIL loss exploits the further supervision given by images with multiple labels. We evaluate this approach through preliminary experiments on the PASCAL VOC segmentation challenge.
Do Convnets Learn Correspondence?
Nov 04, 2014



Convolutional neural nets (convnets) trained from massive labeled datasets have substantially improved the state-of-the-art in image classification and object detection. However, visual understanding requires establishing correspondence on a finer level than object category. Given their large pooling regions and training from whole-image labels, it is not clear that convnets derive their success from an accurate correspondence model which could be used for precise localization. In this paper, we study the effectiveness of convnet activation features for tasks requiring correspondence. We present evidence that convnet features localize at a much finer scale than their receptive field sizes, that they can be used to perform intraclass alignment as well as conventional hand-engineered features, and that they outperform conventional features in keypoint prediction on objects from PASCAL VOC 2011.
Caffe: Convolutional Architecture for Fast Feature Embedding
Jun 20, 2014

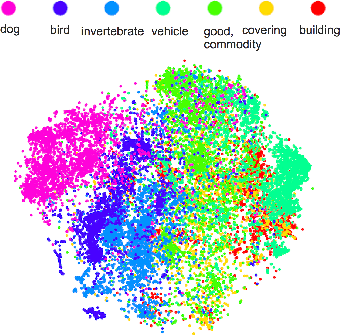
Caffe provides multimedia scientists and practitioners with a clean and modifiable framework for state-of-the-art deep learning algorithms and a collection of reference models. The framework is a BSD-licensed C++ library with Python and MATLAB bindings for training and deploying general-purpose convolutional neural networks and other deep models efficiently on commodity architectures. Caffe fits industry and internet-scale media needs by CUDA GPU computation, processing over 40 million images a day on a single K40 or Titan GPU ($\approx$ 2.5 ms per image). By separating model representation from actual implementation, Caffe allows experimentation and seamless switching among platforms for ease of development and deployment from prototyping machines to cloud environments. Caffe is maintained and developed by the Berkeley Vision and Learning Center (BVLC) with the help of an active community of contributors on GitHub. It powers ongoing research projects, large-scale industrial applications, and startup prototypes in vision, speech, and multimedia.