 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Decoder DPRNN: High Accuracy Source Counting and Separation
Nov 30, 2020
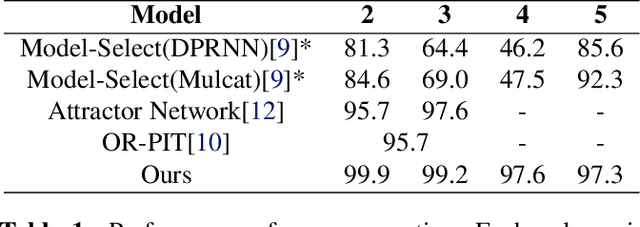
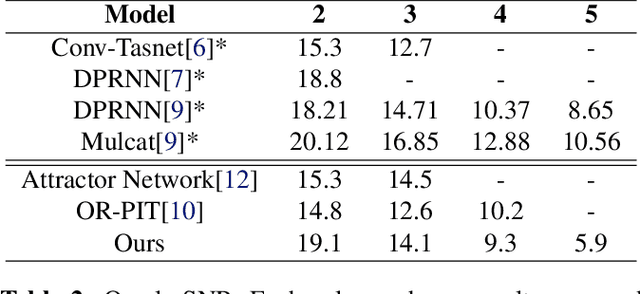

We propose an end-to-end trainable approach to single-channel speech separation with unknown number of speakers. Our approach extends the MulCat source separation backbone with additional output heads: a count-head to infer the number of speakers, and decoder-heads for reconstructing the original signals. Beyond the model, we also propose a metric on how to evaluate source separation with variable number of speakers. Specifically, we cleared up the issue on how to evaluate the quality when the ground-truth hasmore or less speakers than the ones predicted by the model. We evaluate our approach on the WSJ0-mix datasets, with mixtures up to five speakers. We demonstrate that our approach outperforms state-of-the-art in counting the number of speakers and remains competitive in quality of reconstructed signals.
Semantic Facial Expression Editing using Autoencoded Flow
Nov 30, 2016


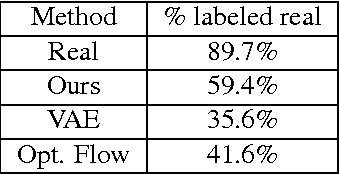
High-level manipulation of facial expressions in images --- such as changing a smile to a neutral expression --- is challenging because facial expression changes are highly non-linear, and vary depending on the appearance of the face. We present a fully automatic approach to editing faces that combines the advantages of flow-based face manipulation with the more recent generative capabilities of Variational Autoencoders (VAEs). During training, our model learns to encode the flow from one expression to another over a low-dimensional latent space. At test time, expression editing can be done simply using latent vector arithmetic. We evaluate our methods on two applications: 1) single-image facial expression editing, and 2) facial expression interpolation between two images. We demonstrate that our method generates images of higher perceptual quality than previous VAE and flow-based methods.