 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Pre-trained Transformers into Decaying Fast Weights
Oct 09, 2022



Autoregressive Transformers are strong language models but incur O(T) complexity during per-token generation due to the self-attention mechanism. Recent work proposes kernel-based methods to approximate causal self-attention by replacing it with recurrent formulations with various update rules and feature maps to achieve O(1) time and memory complexity. We explore these approaches and find that they are unnecessarily complex, and propose a simple alternative - decaying fast weights - that runs fast on GPU, outperforms prior methods, and retains 99% of attention's performance for GPT-2. We also show competitive performance on WikiText-103 against more complex attention substitutes.
A Survey on Self-supervised Pre-training for Sequential Transfer Learning in Neural Networks
Jul 01, 2020
Deep neural networks are typically trained under a supervised learning framework where a model learns a single task using labeled data. Instead of relying solely on labeled data, practitioners can harness unlabeled or related data to improve model performance, which is often more accessible and ubiquitous. Self-supervised pre-training for transfer learning is becoming an increasingly popular technique to improve state-of-the-art results using unlabeled data. It involves first pre-training a model on a large amount of unlabeled data, then adapting the model to target tasks of interest. In this review, we survey self-supervised learning methods and their applications within the sequential transfer learning framework. We provide an overview of the taxonomy for self-supervised learning and transfer learning, and highlight some prominent methods for designing pre-training tasks across different domains. Finally, we discuss recent trends and suggest areas for future investigation.
Speech Recognition and Multi-Speaker Diarization of Long Conversations
May 16, 2020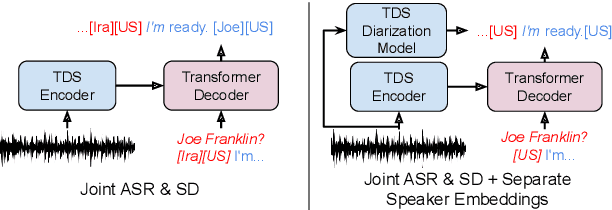
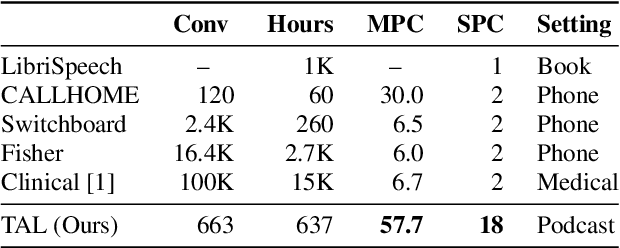
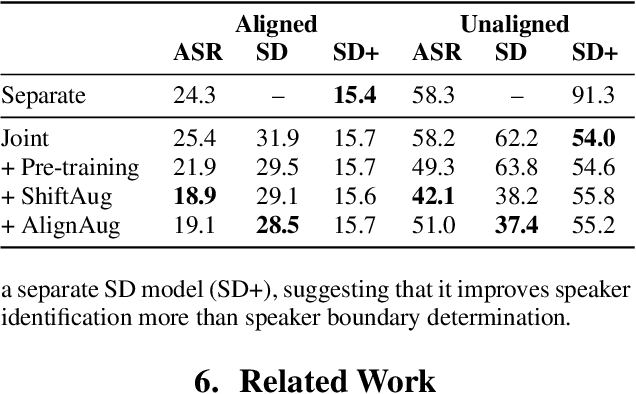
Speech recognition (ASR) and speaker diarization (SD) models have traditionally been trained separately to produce rich conversation transcripts with speaker labels. Recent advances have shown that joint ASR and SD models can learn to leverage audio-lexical inter-dependencies to improve word diarization performance. We introduce a new benchmark of hour-long podcasts collected from the weekly This American Life radio program to better compare these approaches when applied to extended multi-speaker conversations. We find that training separate ASR and SD models perform better when utterance boundaries are known but otherwise joint models can perform better. To handle long conversations with unknown utterance boundaries, we introduce a striding attention decoding algorithm and data augmentation techniques which, combined with model pre-training, improves ASR and SD.
ReZero is All You Need: Fast Convergence at Large Depth
Mar 10, 2020
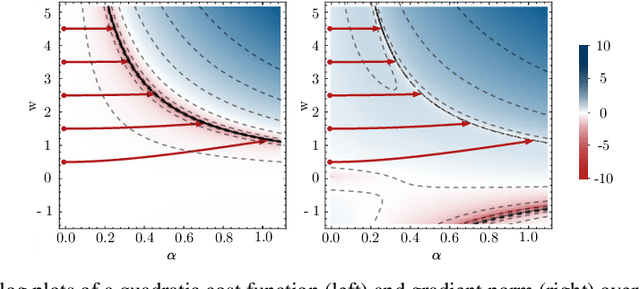

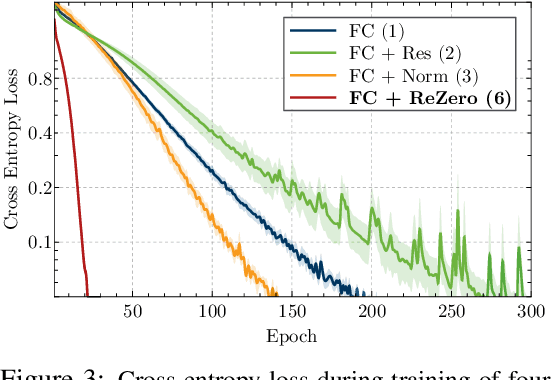
Deep networks have enabled significant performance gains across domains, but they often suffer from vanishing/exploding gradients. This is especially true for Transformer architectures where depth beyond 12 layers is difficult to train without large datasets and computational budgets. In general, we find that inefficient signal propagation impedes learning in deep networks. In Transformers, multi-head self-attention is the main cause of this poor signal propagation. To facilitate deep signal propagation, we propose ReZero, a simple change to the architecture that initializes an arbitrary layer as the identity map, using a single additional learned parameter per layer. We apply this technique to language modeling and find that we can easily train ReZero-Transformer networks over a hundred layers. When applied to 12 layer Transformers, ReZero converges 56% faster on enwiki8. ReZero applies beyond Transformers to other residual networks, enabling 1,500% faster convergence for deep fully connected networks and 32% faster convergence for a ResNet-56 trained on CIFAR 10.
Improving Neural Story Generation by Targeted Common Sense Grounding
Aug 26, 2019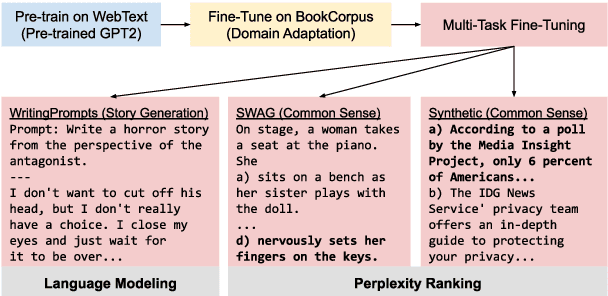
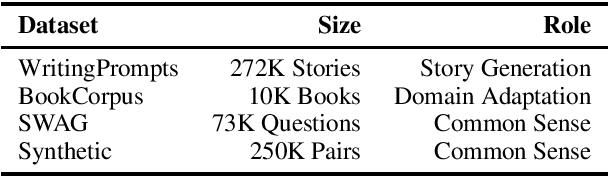

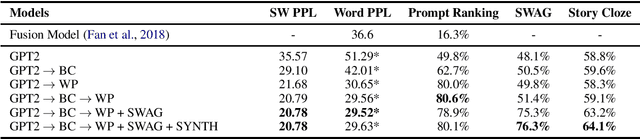
Stories generated with neural language models have shown promise in grammatical and stylistic consistency. However, the generated stories are still lacking in common sense reasoning, e.g., they often contain sentences deprived of world knowledge. We propose a simple multi-task learning scheme to achieve quantitatively better common sense reasoning in language models by leveraging auxiliary training signals from datasets designed to provide common sense grounding. When combined with our two-stage fine-tuning pipeline, our method achieves improved common sense reasoning and state-of-the-art perplexity on the Writing Prompts (Fan et al., 2018) story generation dataset.
LakhNES: Improving multi-instrumental music generation with cross-domain pre-training
Jul 10, 2019
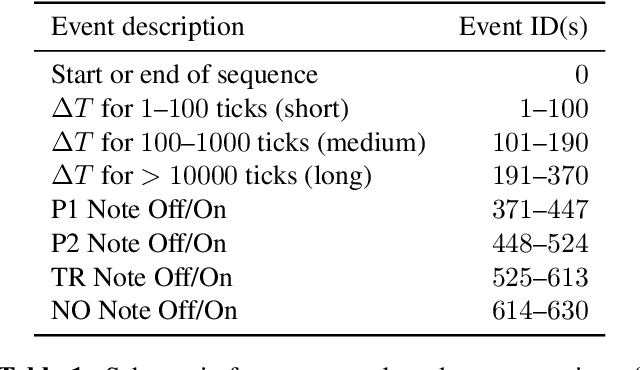
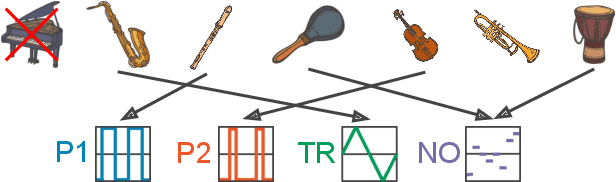
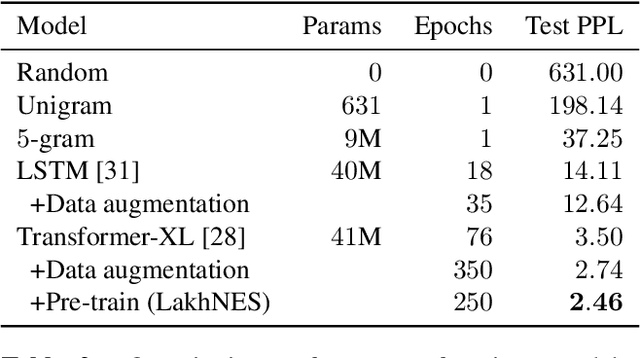
We are interested in the task of generating multi-instrumental music scores. The Transformer architecture has recently shown great promise for the task of piano score generation; here we adapt it to the multi-instrumental setting. Transformers are complex, high-dimensional language models which are capable of capturing long-term structure in sequence data, but require large amounts of data to fit. Their success on piano score generation is partially explained by the large volumes of symbolic data readily available for that domain. We leverage the recently-introduced NES-MDB dataset of four-instrument scores from an early video game sound synthesis chip (the NES), which we find to be well-suited to training with the Transformer architecture. To further improve the performance of our model, we propose a pre-training technique to leverage the information in a large collection of heterogeneous music, namely the Lakh MIDI dataset. Despite differences between the two corpora, we find that this transfer learning procedure improves both quantitative and qualitative performance for our primary task.
The NES Music Database: A multi-instrumental dataset with expressive performance attributes
Jun 12, 2018
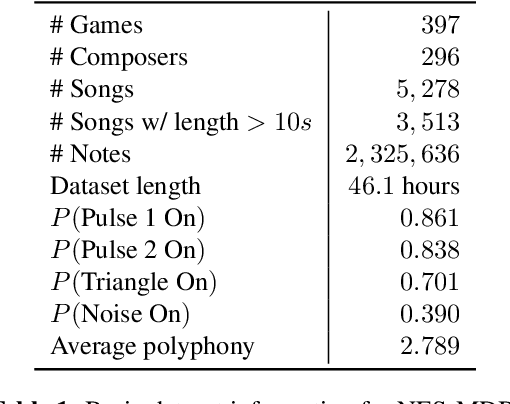
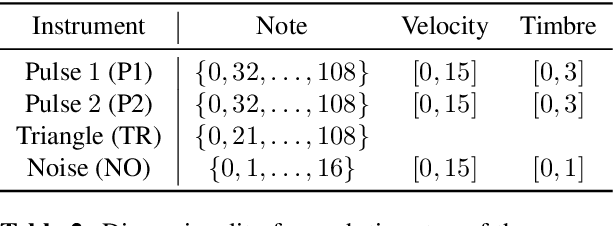

Existing research on music generation focuses on composition, but often ignores the expressive performance characteristics required for plausible renditions of resultant pieces. In this paper, we introduce the Nintendo Entertainment System Music Database (NES-MDB), a large corpus allowing for separate examination of the tasks of composition and performance. NES-MDB contains thousands of multi-instrumental songs composed for playback by the compositionally-constrained NES audio synthesizer. For each song, the dataset contains a musical score for four instrument voices as well as expressive attributes for the dynamics and timbre of each voice. Unlike datasets comprised of General MIDI files, NES-MDB includes all of the information needed to render exact acoustic performances of the original compositions. Alongside the dataset, we provide a tool that renders generated compositions as NES-style audio by emulating the device's audio processor. Additionally, we establish baselines for the tasks of composition, which consists of learning the semantics of composing for the NES synthesizer, and performance, which involves finding a mapping between a composition and realistic expressive attributes.