 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Predicates Structuring urban perception with scene graphs
Dec 22, 2025Perception research is increasingly modelled using streetscapes, yet many approaches still rely on pixel features or object co-occurrence statistics, overlooking the explicit relations that shape human perception. This study proposes a three stage pipeline that transforms street view imagery (SVI) into structured representations for predicting six perceptual indicators. In the first stage, each image is parsed using an open-set Panoptic Scene Graph model (OpenPSG) to extract object predicate object triplets. In the second stage, compact scene-level embeddings are learned through a heterogeneous graph autoencoder (GraphMAE). In the third stage, a neural network predicts perception scores from these embeddings. We evaluate the proposed approach against image-only baselines in terms of accuracy, precision, and cross-city generalization. Results indicate that (i) our approach improves perception prediction accuracy by an average of 26% over baseline models, and (ii) maintains strong generalization performance in cross-city prediction tasks. Additionally, the structured representation clarifies which relational patterns contribute to lower perception scores in urban scenes, such as graffiti on wall and car parked on sidewalk. Overall, this study demonstrates that graph-based structure provides expressive, generalizable, and interpretable signals for modelling urban perception, advancing human-centric and context-aware urban analytics.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025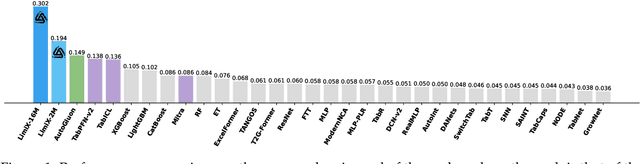
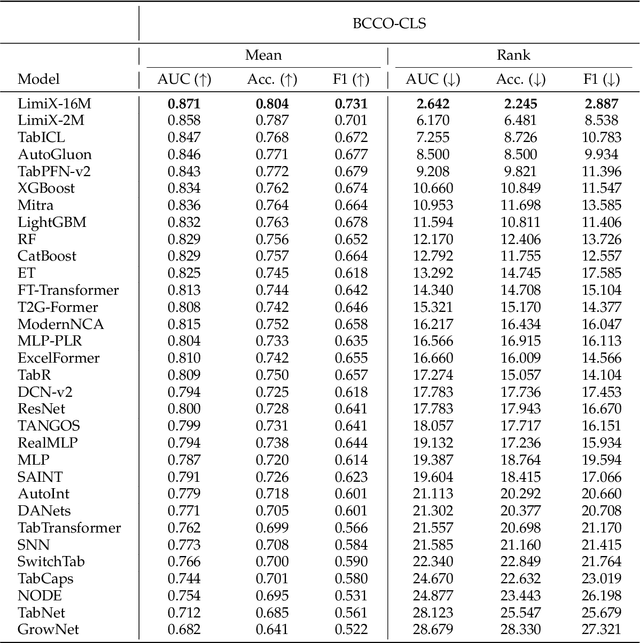
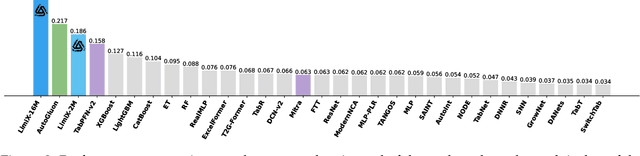
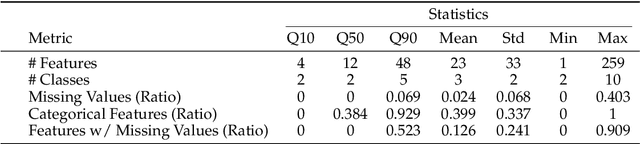
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
Semantic Localization Guiding Segment Anything Model For Reference Remote Sensing Image Segmentation
Jun 12, 2025The Reference Remote Sensing Image Segmentation (RRSIS) task generates segmentation masks for specified objects in images based on textual descriptions, which has attracted widespread attention and research interest. Current RRSIS methods rely on multi-modal fusion backbones and semantic segmentation heads but face challenges like dense annotation requirements and complex scene interpretation. To address these issues, we propose a framework named \textit{prompt-generated semantic localization guiding Segment Anything Model}(PSLG-SAM), which decomposes the RRSIS task into two stages: coarse localization and fine segmentation. In coarse localization stage, a visual grounding network roughly locates the text-described object. In fine segmentation stage, the coordinates from the first stage guide the Segment Anything Model (SAM), enhanced by a clustering-based foreground point generator and a mask boundary iterative optimization strategy for precise segmentation. Notably, the second stage can be train-free, significantly reducing the annotation data burden for the RRSIS task. Additionally, decomposing the RRSIS task into two stages allows for focusing on specific region segmentation, avoiding interference from complex scenes.We further contribute a high-quality, multi-category manually annotated dataset. Experimental validation on two datasets (RRSIS-D and RRSIS-M) demonstrates that PSLG-SAM achieves significant performance improvements and surpasses existing state-of-the-art models.Our code will be made publicly available.
Assistive Recipe Editing through Critiquing
May 05, 2022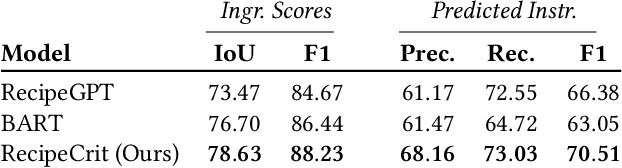
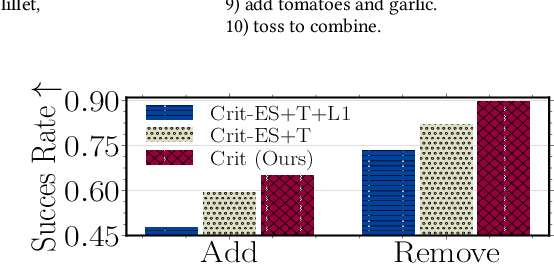
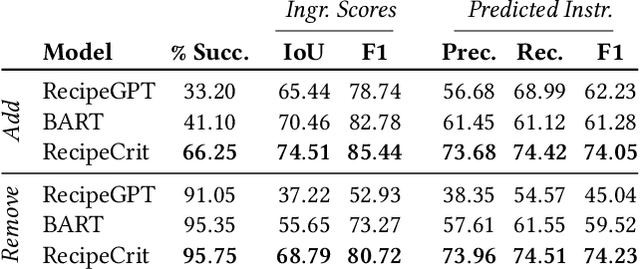

There has recently been growing interest in the automatic generation of cooking recipes that satisfy some form of dietary restrictions, thanks in part to the availability of online recipe data. Prior studies have used pre-trained language models, or relied on small paired recipe data (e.g., a recipe paired with a similar one that satisfies a dietary constraint). However, pre-trained language models generate inconsistent or incoherent recipes, and paired datasets are not available at scale. We address these deficiencies with RecipeCrit, a hierarchical denoising auto-encoder that edits recipes given ingredient-level critiques. The model is trained for recipe completion to learn semantic relationships within recipes. Our work's main innovation is our unsupervised critiquing module that allows users to edit recipes by interacting with the predicted ingredients; the system iteratively rewrites recipes to satisfy users' feedback. Experiments on the Recipe1M recipe dataset show that our model can more effectively edit recipes compared to strong language-modeling baselines, creating recipes that satisfy user constraints and are more correct, serendipitous, coherent, and relevant as measured by human judges.
Instilling Type Knowledge in Language Models via Multi-Task QA
Apr 28, 2022
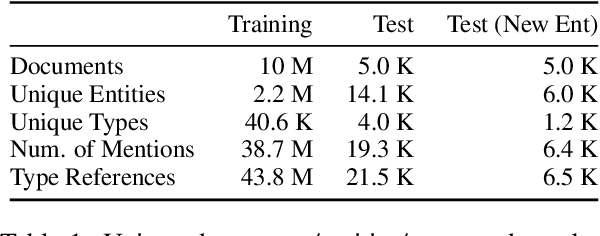

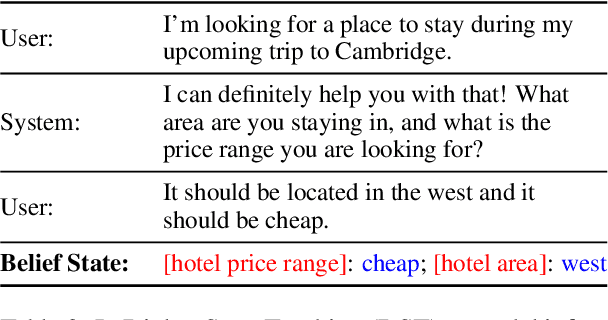
Understanding human language often necessitates understanding entities and their place in a taxonomy of knowledge -- their types. Previous methods to learn entity types rely on training classifiers on datasets with coarse, noisy, and incomplete labels. We introduce a method to instill fine-grained type knowledge in language models with text-to-text pre-training on type-centric questions leveraging knowledge base documents and knowledge graphs. We create the WikiWiki dataset: entities and passages from 10M Wikipedia articles linked to the Wikidata knowledge graph with 41K types. Models trained on WikiWiki achieve state-of-the-art performance in zero-shot dialog state tracking benchmarks, accurately infer entity types in Wikipedia articles, and can discover new types deemed useful by human judges.
Self-Supervised Bot Play for Conversational Recommendation with Justifications
Dec 09, 2021

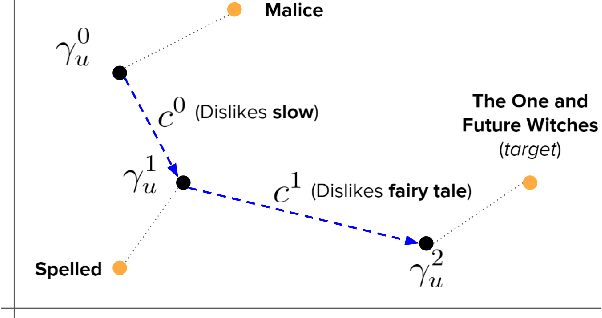
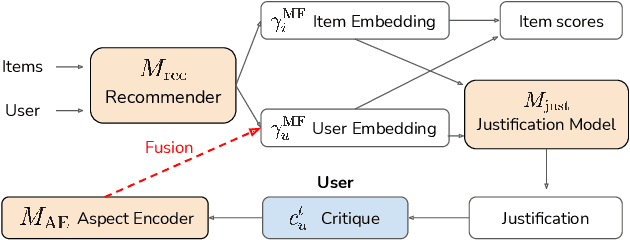
Conversational recommender systems offer the promise of interactive, engaging ways for users to find items they enjoy. We seek to improve conversational recommendation via three dimensions: 1) We aim to mimic a common mode of human interaction for recommendation: experts justify their suggestions, a seeker explains why they don't like the item, and both parties iterate through the dialog to find a suitable item. 2) We leverage ideas from conversational critiquing to allow users to flexibly interact with natural language justifications by critiquing subjective aspects. 3) We adapt conversational recommendation to a wider range of domains where crowd-sourced ground truth dialogs are not available. We develop a new two-part framework for training conversational recommender systems. First, we train a recommender system to jointly suggest items and justify its reasoning with subjective aspects. We then fine-tune this model to incorporate iterative user feedback via self-supervised bot-play. Experiments on three real-world datasets demonstrate that our system can be applied to different recommendation models across diverse domains to achieve superior performance in conversational recommendation compared to state-of-the-art methods. We also evaluate our model on human users, showing that systems trained under our framework provide more useful, helpful, and knowledgeable recommendations in warm- and cold-start settings.
SHARE: a System for Hierarchical Assistive Recipe Editing
May 17, 2021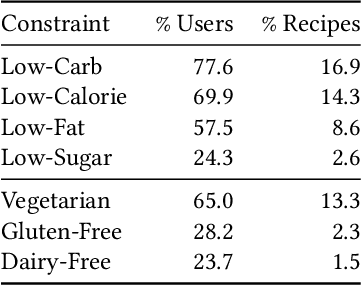
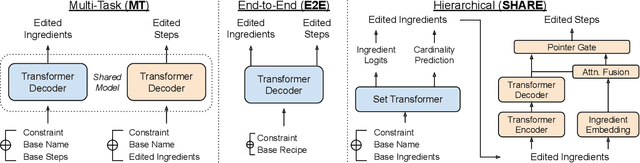
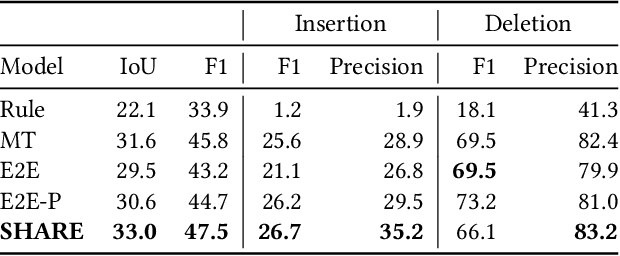
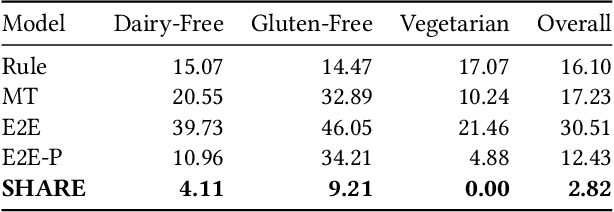
We introduce SHARE: a System for Hierarchical Assistive Recipe Editing to assist home cooks with dietary restrictions -- a population under-served by existing cooking resources. Our hierarchical recipe editor makes necessary substitutions to a recipe's ingredients list and re-writes the directions to make use of the new ingredients. We introduce the novel RecipePairs dataset of 84K pairs of similar recipes in which one recipe satisfies one of seven dietary constraints, allowing for supervised training of such recipe editing models. Experiments on this dataset demonstrate that our system produces convincing, coherent recipes that are appropriate for a target dietary constraint (contain no prohibited ingredients). We show that this is a challenging task that cannot be adequately solved with human-written ingredient substitution rules or straightforward adaptation of state-of-the-art models for recipe generation. We further demonstrate through human evaluations and real-world cooking trials that recipes edited by our system can be easily followed by home cooks to create delicious and satisfactory dishes.
Zero-shot Generalization in Dialog State Tracking through Generative Question Answering
Jan 20, 2021
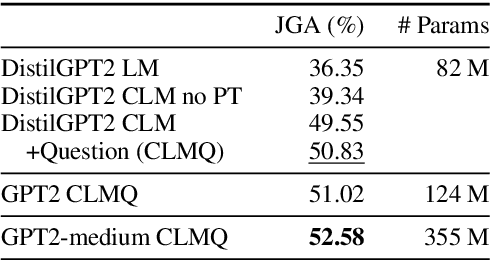
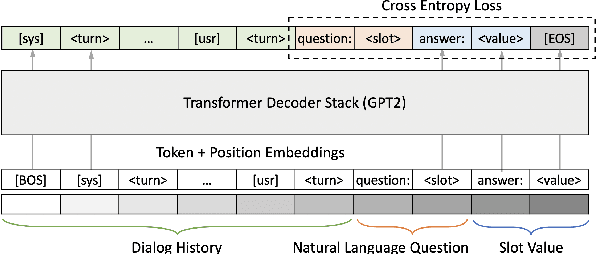
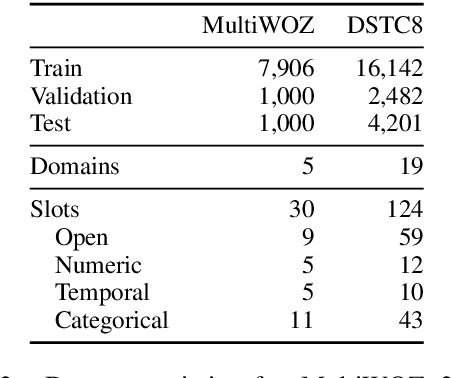
Dialog State Tracking (DST), an integral part of modern dialog systems, aims to track user preferences and constraints (slots) in task-oriented dialogs. In real-world settings with constantly changing services, DST systems must generalize to new domains and unseen slot types. Existing methods for DST do not generalize well to new slot names and many require known ontologies of slot types and values for inference. We introduce a novel ontology-free framework that supports natural language queries for unseen constraints and slots in multi-domain task-oriented dialogs. Our approach is based on generative question-answering using a conditional language model pre-trained on substantive English sentences. Our model improves joint goal accuracy in zero-shot domain adaptation settings by up to 9% (absolute) over the previous state-of-the-art on the MultiWOZ 2.1 dataset.
Speech Recognition and Multi-Speaker Diarization of Long Conversations
May 16, 2020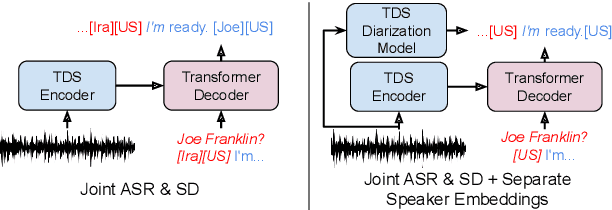
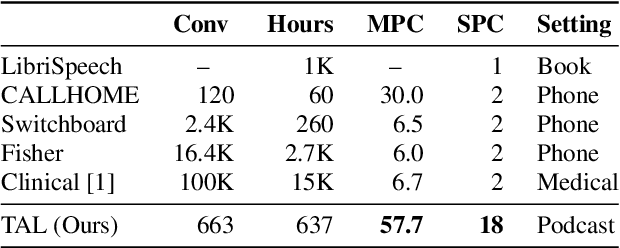
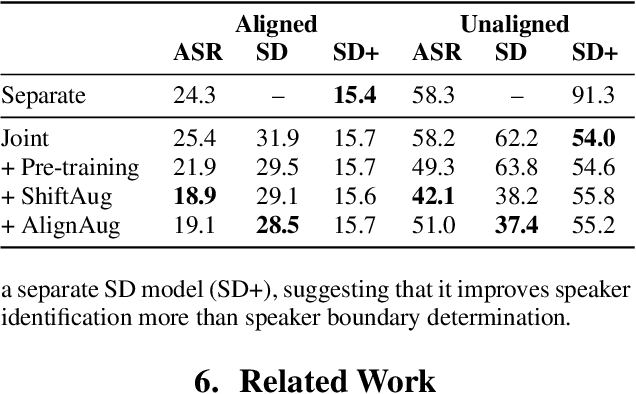
Speech recognition (ASR) and speaker diarization (SD) models have traditionally been trained separately to produce rich conversation transcripts with speaker labels. Recent advances have shown that joint ASR and SD models can learn to leverage audio-lexical inter-dependencies to improve word diarization performance. We introduce a new benchmark of hour-long podcasts collected from the weekly This American Life radio program to better compare these approaches when applied to extended multi-speaker conversations. We find that training separate ASR and SD models perform better when utterance boundaries are known but otherwise joint models can perform better. To handle long conversations with unknown utterance boundaries, we introduce a striding attention decoding algorithm and data augmentation techniques which, combined with model pre-training, improves ASR and SD.
Interview: A Large-Scale Open-Source Corpus of Media Dialog
Apr 07, 2020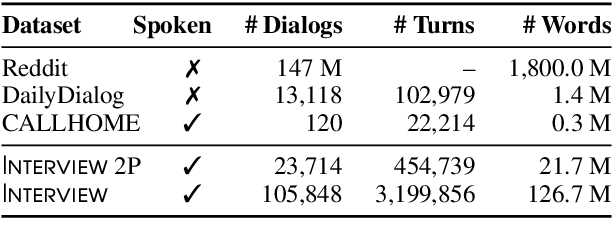
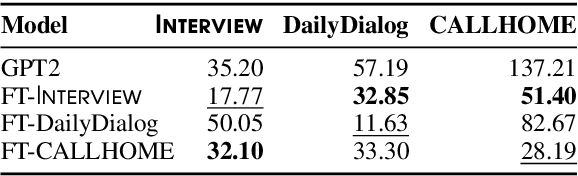
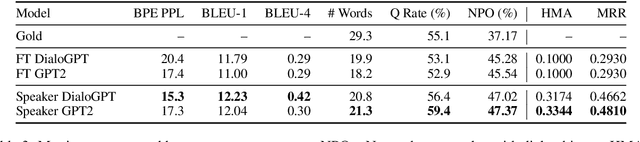

Existing conversational datasets consist either of written proxies for dialog or small-scale transcriptions of natural speech. We introduce 'Interview': a large-scale (105K conversations) media dialog dataset collected from news interview transcripts. Compared to existing large-scale proxies for conversational data, language models trained on our dataset exhibit better zero-shot out-of-domain performance on existing spoken dialog datasets, demonstrating its usefulness in modeling real-world conversations. 'Interview' contains speaker role annotations for each turn, facilitating the development of engaging, responsive dialog systems. In fact, experiments on two dialog tasks show that leveraging such labels improves performance over strong speaker-agnostic baselines, and enabling models to generate more specific and inquisitive responses in interview-style conversations.