 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistorical Trajectory Assisted Zeroth-Order Federated Optimization
Paper and Code
Sep 25, 2024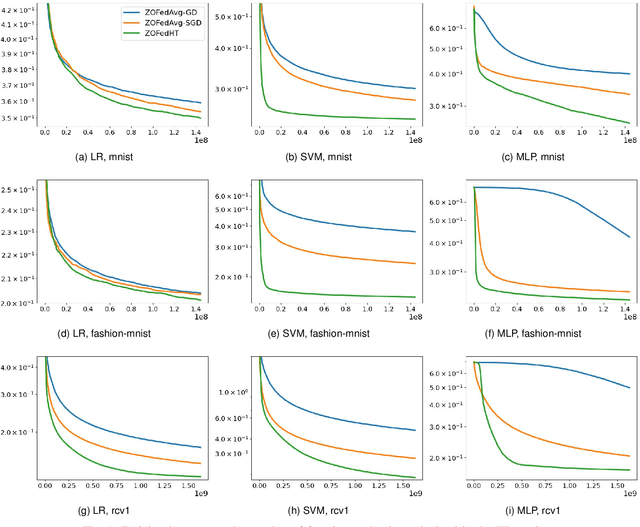


Federated learning is a distributed learning framework which enables clients to train models individually and to upload their model updates for aggregation. The local training process heavily relies on distributed gradient descent techniques. In the situation where gradient information is not available, the gradients need to be estimated from zeroth-order information, which typically involves computing finite-differences along isotropic random directions. This method suffers from high estimation errors, as the geometric features of the objective landscape may be overlooked during the isotropic sampling. In this work, we propose a non-isotropic sampling method to improve the gradient estimation procedure. Gradients in our method are estimated in a subspace spanned by historical trajectories of solutions, aiming to encourage the exploration of promising regions and hence improve the convergence. We implement this method in zeroth-order federated settings, and show that the convergence rate aligns with existing ones while introducing no significant overheads in communication or local computation. The effectiveness of our proposal is verified on several numerical experiments in comparison to several commonly-used zeroth-order federated optimization algorithms.