 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Parameter Collision Hindering Continual Learning in LLMs?
Oct 14, 2024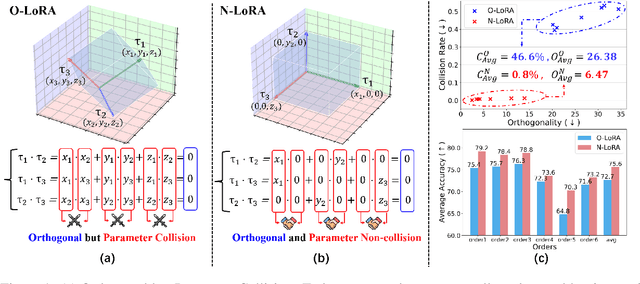
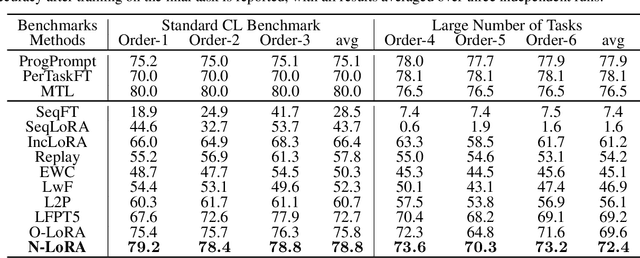
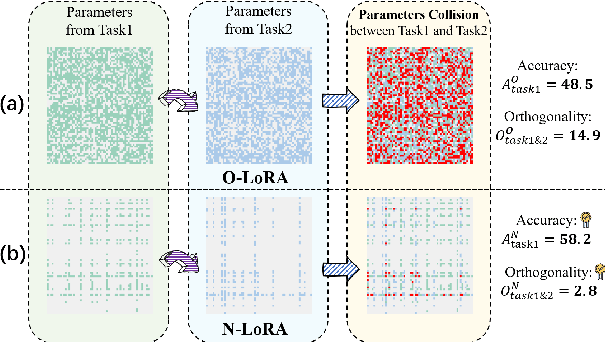

Large Language Models (LLMs) often suffer from catastrophic forgetting when learning multiple tasks sequentially, making continual learning (CL) essential for their dynamic deployment. Existing state-of-the-art (SOTA) methods, such as O-LoRA, typically focus on constructing orthogonality tasks to decouple parameter interdependence from various domains.In this paper, we reveal that building non-collision parameters is a more critical factor in addressing CL challenges. Our theoretical and experimental analyses demonstrate that non-collision parameters can provide better task orthogonality, which is a sufficient but unnecessary condition. Furthermore, knowledge from multiple domains will be preserved in non-collision parameter subspaces, making it more difficult to forget previously seen data. Leveraging this insight, we propose Non-collision Low-Rank Adaptation (N-LoRA), a simple yet effective approach leveraging low collision rates to enhance CL in LLMs. Experimental results on multiple CL benchmarks indicate that N-LoRA achieves superior performance (+2.9), higher task orthogonality (*4.1 times), and lower parameter collision (*58.1 times) than SOTA methods.